Tripadvisor est le site Web le plus visité permettant de trouver les meilleurs hôtels, restaurants, attractions touristiques, jeux d’aventure, et essentiellement tout ce qu’il faut pour un voyage amusant. Visiter Tripadvisor pour découvrir les meilleures activités à faire est devenu une habitude pour tous ceux qui cherchent à se rendre dans une ville ou un pays différent, comme ce que indique son nom.
Chaque année, des millions de personnes organisent des voyages extraordinaires à l’aide de l’Internet. En même temps, des millions d’utilisateurs y ont partagé leurs expériences et leurs opinions sur des sites. La popularité de cette plateforme conduit à ce que de plus en plus d’hôtels, de restaurants et d’autres entreprises touristiques tentent d’y figurer et d’y maintenir une bonne position, car des évaluations positives sur le site peuvent être très avantageuses.
Des informations comme prix, évaluations, avis clients, etc, sont très utiles, car elles vous permettent de récupérer les évaluations, de surveiller vos concurrents, d’améliorer votre service, et bien plus encore. Ainsi, dans cet article, nous allons essayer faire un Tripadvisor scraper pour obtenir tous les types de données d’hôtels ou de restaurants.
Réflexions générales sur scraping TripAdvisor
Tripadvisor autorise-t-il le scraping ?
Vous êtes libre de récupérer les données qui sont publiques sur ce site. Tripadvisor dispose d’une abondance de données utiles, notamment les prix des vols, les tarifs des hôtels, les attractions les plus populaires et même des indications statistiques sur ce qui est tendance ou peut l’être. Le scraping en ligne, ou l’extraction automatique d’informations à partir de sites web, pourrait être utilisé pour récupérer ce genre contenu sur Tripadvisor.
En outre, Tripadvisor offre un accès API qui permet aux agences de voyage et aux hôtels d’intégrer les évaluations, les critiques et les statistiques de Tripadvisor dans leurs sites Web. Vous réussirez si vous faites le scraping pour obtenir des données utiles tout en profitant de l’API de Tripadvisor.
Une grande varitété de données accessibles sur Tripadvisor
Sur Tripadvisor, les particuliers l’utilisent pour réserver des vols, des hôtels et des activités. Les utilisateurs peuvent également donner leur avis sur les hôtels, les restaurants, les excursions et d’autres. Par conséquent, le site lui-même fournit une pléthore d’avis et d’informations sur les prix. Les consommateurs peuvent utiliser ces informations pour trouver les meilleures réductions, y compris les forfaits, et pour rassembler les commentaires afin de se faire une idée d’un lieu au-delà des photos. Dans le secteur encombré et agressif du tourisme, Tripadvisor aide les visiteurs à découvrir des villages de vacances, des locations ou des excursions, ce qui importe grandement pour les agences de voyage ou toute personne travaillant dans l’hôtellerie.
Outre les prix des vols ou des chambres, vous pouvez également récupérer les avis laissés par les clients, les noms d’utilisateur, les détails des lieux les plus populaires, etc.
Avantages de scraping Tripadvisor
L’un des principaux avantages de scraping Tripadvisor est qu’on peut comparer les prix des locations ou des hébergements. Il s’agit d’une approche simple permettant aux gens de rechercher la meilleure valeur et d’évaluer différents types d’unités. En recherchant les prix, les agences de voyage peuvent obtenir une meilleure idée du marché. La comparaison des prix est particulièrement importante si vous devez encore choisir où séjourer.
Tripadvisor permet aux voyageurs de publier des avis sur des hébergements, des activités, des cafés et d’autres services. En scrapant Tripadvisor pour extraire ces avis, on peut récupérer des informations sur la façon dont les gens perçoivent votre service. Tripadvisor propose des statistiques qui peuvent vous aider à comprendre votre image publique, que vous gériez un restaurant, une maison d’hôtes ou une excursion dans les environs.
Vous pouvez utiliser les données de Tripadvisor pour examiner toutes les alternatives potentielles pour vos clients. Vous pouvez adjuster les mots-clés pour vous procurer des recommandations après avoir compris leurs préférences.
Scraping Tripadvisor avec Octoparse sans code
Dans cette partie, nous allons vous montrer comment scraper un site Web comme Tripadvisor et exporter des données telles que le nom de l’hôtel, son classement, son prix et des comparaisons de prix. Octoparse est un outil de scraping sans code qui permet de collecter des données sur les hôtels à partir de Tripadvisor sans avoir codage. N’importe qui peut rapidement créer un crawler grâce à la fonction de détection automatique. En outre, il propose des modèles prédéfinis pour la majorité des sites (y compris Tripadvisor), ce qui rend le processus de scraping plus rapide et plus facile à démarrer. Même les débutants peuvent obtenir ce dont ils ont besoin en très peu de temps.
Étapes pour récupérer les données de Tripadvisor sans codage
Après avoir téléchargé et installé Octoparse sur votre appareil Windows/Mac, vous pouvez suivre les étapes ci-dessous pour faire un essai gratuit (il existe un plan gratuit à vie). Si vous souhaitez obtenir plus de détails sur le guide, vous pouvez consulter le centre d’aide ou contacter le support.
Étape 1 : Collez votre URL Tripadvisor ciblé pour lancer l’auto-détection
Il suffit de copier l’URL ciblée que vous voulez scraper et de la coller dans la barre de recherche sur la page d’accueil d’Octoparse. Ensuite, vous pouvez utiliser la fonction d’auto-détection en cliquant simplement sur le bouton “Auto-detect webpage data” pour que Octoparse crée automatiquement un workflow capable de récupérer les données désirées.
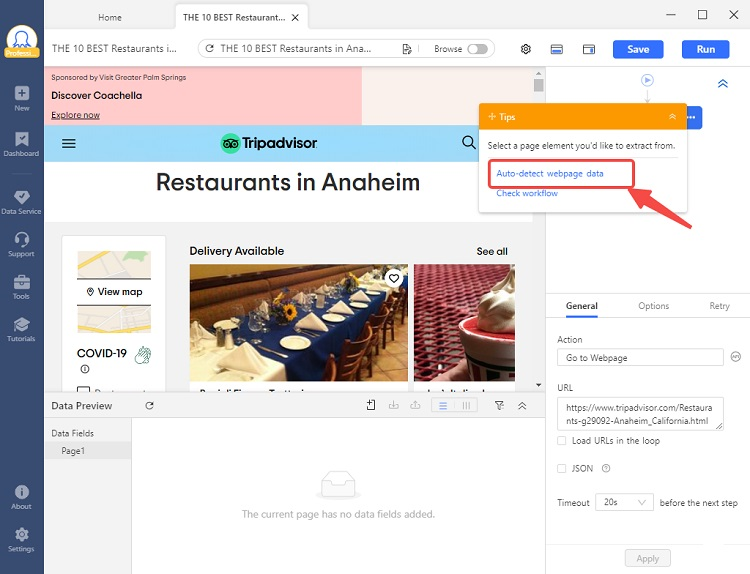
Étape 2 : Examinez et modifiez le workflow
Après que l’auto-détection ont créé automatiquement un workflow pour vous, il vous faut encore examiner les champs de données dans la section d’aperçu. Modifiez n’importe quel champ de données que vous voulez, vous pouvez trouver un panneau d’astuces pour vous donner quelques conseils.
Étape 3 : Lancez la tâche de scraping pour récupérer les données
Une fois la modification terminée, cliquez sur le bouton “Run” pour commencer à extraire les données. Vous pouvez exporter les résultats de l’extraction au format Excel, CSV ou tout autre format ou utiliser API pour les importer dans d’autres systèmes.
Scraping Tripadvisor avec Python
Pour ceux qui savent coder, Python est une bonne méthode pour récupérer les données de n’importe quelle page Web, y compris Tripadvisor. Vous pouvez trouver de nombreux tutoriels ou codes partagés par d’autres développeurs sur GitHub. Par exemple, vous pouvez trouver Scraping Tripadvisor avec Python. En général, nous avons besoin de l’aide de modules Python tels que Selenium ou Beautiful Soup pour coder avec Python.
Tripadvisor contient une mine d’informations sur les voyages, les hébergements, les restaurants et les communautés de discussion. Le web scraping est la méthode idéale pour collecter et analyser ces données afin d’en tirer des enseignements. D’une part, les consommateurs peuvent utiliser ces données pour organiser leurs vacances de rêve, en intégrant des conseils tirés des commentaires pour éviter les erreurs fréquentes. De l’autre part, les données de Tripadvisor indiquent aux agences de voyage ce que leurs clients attendent le plus de certains endroits et les aident à repérer la concurrence. L’API de Tripadvisor permet aux agences et autres sites d’accueil d’intégrer les avis de Tripadvisor à leurs sites Web. En fin de compte, j’espère que cet article vous servira de guide fiable pour le scrapping de Tripadvisor.



