Le scraping d’écran est une technique de collecte de données généralement utilisée pour copier les informations qui s’affichent sur un écran numérique afin de les utiliser à d’autres objets. Dans cet article, nous allons présenter le processus de récupération d’écran et comment fonctionne un récupérateur d’écran.
Scraping d’écran
Normalement associé à la collecte programmatique de données visuelles à partir d’une source, le grattage d’écran fait généralement référence à la pratique consistant à lire des données textuelles sur l’écran d’un terminal d’affichage informatique.
En tant que méthode de collecte de données d’affichage d’écran à partir d’une application et de leur traduction pour qu’une autre application puisse les afficher, le screen scraping est normalement utilisé pour récupérer les données visuelles d’une ancienne application afin de les afficher à l’aide d’une interface utilisateur plus moderne.
Pourquoi le scraping d’écran est-il généralement utilisé pour transférer des données ?
“Dans des circonstances normales, une application patrimoniale est soit remplacée par un nouveau programme, soit mise à jour en réécrivant le code source.
Dans certains cas, il est souhaitable de continuer à utiliser une application patrimoniale mais le manque de disponibilité du code source, des programmeurs ou de la documentation rend impossible la réécriture ou la mise à jour de l’application. Dans ce cas, la seule façon de continuer à utiliser l’application existante peut être d’écrire un logiciel de nettoyage d’écran pour la traduire en une interface utilisateur plus moderne. Le grattage d’écran n’est généralement effectué que lorsque toutes les autres options sont impraticables.” (Telecharger en masse des images a partir des sites Web / Liens)
Bien que le screen scraping consiste également à extraire des données d’un site Web ou d’une application, il est différent du web scraping, qui vise à obtenir des données individuelles sur un site Web. Le screen scraping se concentre davantage sur les informations visuelles affichées sur un écran et ne cible pas de données ou d’éléments spécifiques.
Outil de scraping d’écran
Un scraper d’écran est un programme informatique qui utilise une technique de scrapping d’écran pour effectuer une traduction entre les programmes d’application existants (écrits pour communiquer avec des dispositifs d’entrée/sortie et des interfaces utilisateur aujourd’hui généralement obsolètes) et les nouvelles interfaces utilisateur afin que la logique et les données associées aux programmes existants puissent continuer à être utilisées.
Un scraper d’écran utile est censé répondre à deux exigences :
1. Capturer l’entrée de l’écran et la transmettre à l’application patrimoniale pour traitement.
2. Renvoyer les données de l’application à l’utilisateur et les afficher correctement sur l’écran de ce dernier.
Au début des PC, les outils de nettoyage d’écran émulaient un terminal (par exemple IBM 3270) et se faisaient passer pour un utilisateur afin d’extraire et de mettre à jour de manière interactive les informations sur l’ordinateur central. Plus récemment, le concept est appliqué à toute application qui fournit une interface via des pages Web.
Les outils de scraping d’écran jouent un rôle important dans les scénarios de migration et d’intégration de données. En permettant aux applications modernes de communiquer avec les applications existantes qui n’offrent pas d’API et en complétant l’automatisation de la saisie des données, les scrapeurs d’écran viennent à la rescousse dans de nombreux scénarios commerciaux. Même si les clients ont accès à la base de données des applications existantes lorsqu’il est nécessaire de transférer des données, il est plus pratique et moins sujet à l’erreur pour eux de passer directement par l’interface utilisateur avec l’aide des outils de scraping d’écran.
Extraction de Données en mode “No-Code
Les techniques de web scraping et de scraping d’écran sont toutes deux utiles pour la collecte de données. Les deux techniques peuvent être utilisées en même temps pour s’assurer que vous recueillez correctement le bon type de données. Vous pouvez utiliser le web scraping pour saisir des éléments spécifiques d’un site Web, comme les URL, les textes, les statistiques, etc., et les exporter dans un fichier JSON ou Excel. Ensuite, vous pouvez utiliser un scraper d’écran pour extraire des données visuelles, comme des graphiques et des tableaux.
Lorsqu’il s’agit d’extraction de données, les gens sont susceptibles de considérer qu’il s’agit d’une activité réservée à ceux qui ont une formation technique. Mais en réalité, le processus peut se faire sans codage. Divers outils de scraping Web peuvent être sélectionnés par les utilisateurs qui ne sont pas familiers avec le codage. Octoparse est l’un d’entre eux.
Si vous souhaitez extraire les données dont vous avez besoin, Octoparse vous permet de travailler avec des données dynamiques non structurées en cliquant simplement sur des points de données uniques et il génère automatiquement un code efficace pour extraire les données. Aucun codage n’est nécessaire dans ce processus. Il vous permet également d’exporter des données vers les formats de votre choix, tels que Excel, JSON, CSV, TXT, HTML, voire directement vers votre base de données via une API. Octoparse vous permet tout simplement de récolter des données du bout des doigts.
Prenons l’exemple de l’extraction de données de produits sur ebay.
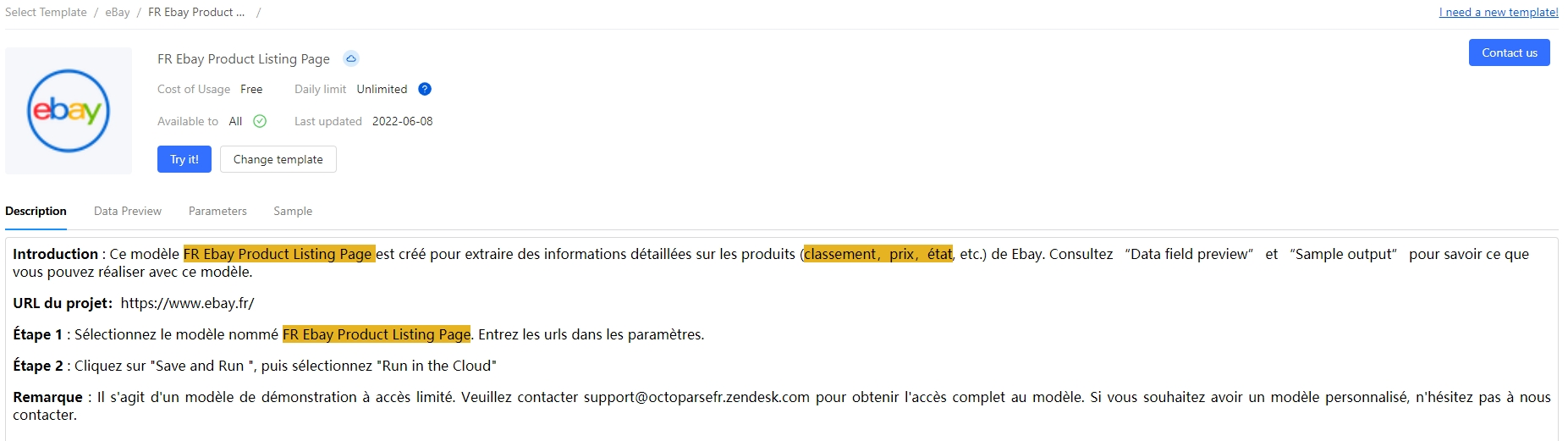
En fonction de vos besoins, vous pouvez choisir d’utiliser les modèles proposés ou de créer votre propre tâche de scraping.
Si vous décidez d’utiliser les modèles, il vous suffit de taper les paramètres requis, puis de cliquer sur “Enregistrer et exécuter”. Une fois l’exécution terminée, les données sont prêtes à être exportées.
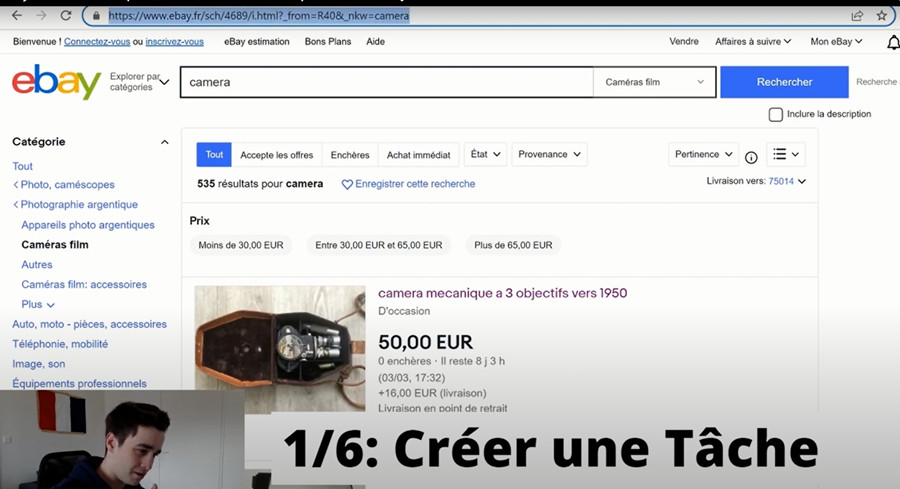
Si vous décidez de créer votre propre scraper, c’est le “mode avancé” que vous devez sélectionner. Il vous suffit de taper l’URL de la page Web dans la barre de recherche, de cliquer sur “Démarrer” et de créer le flux de travail. La vidéo ci-dessous présente le tutoriel étape par étape : Comment scraper des informations sur les produits sur eBay?
Avec Octoparse, le voyage d’extraction de données sans code est prêt à commencer. Bonne chance !



