Sauvegarder un site pour le consulter hors ligne, en garder une copie avant une refonte, ou en extraire des données précises : ce sont des besoins concrets que rencontrent chaque jour développeurs, responsables marketing et équipes data en France. Les aspirateurs de site web couvrent une partie de ces usages, mais leurs limites sont réelles, et en 2026, certains cas nécessitent une approche fondamentalement différente.
Six logiciels pour aspirer un site web ont été testés et comparés : avantages réels, blocages concrets, et situations où une alternative plus ciblée s’impose. Si vous gérez des données web en France, que ce soit pour de la veille tarifaire, de la génération de leads ou de l’archivage réglementaire, vous trouverez ici une réponse directe.
Si votre priorité est d’extraire des données précises plutôt que de télécharger l’intégralité d’un site, Octoparse fait exactement ça, gratuitement, sans passer des heures en configuration.
Cet article a été rédigé et testé par l’équipe technique d’Octoparse, spécialisée dans l’extraction de données web depuis plus de 10 ans. Tous les outils mentionnés ont été testés en conditions réelles sur des sites français en 2026.
Qu’est-ce qu’un aspirateur de site web ?
Selon Wikipédia, un aspirateur de site web est un logiciel qui télécharge toutes les données d’un site pour les sauvegarder sur un support local, généralement un disque dur ou un SSD.
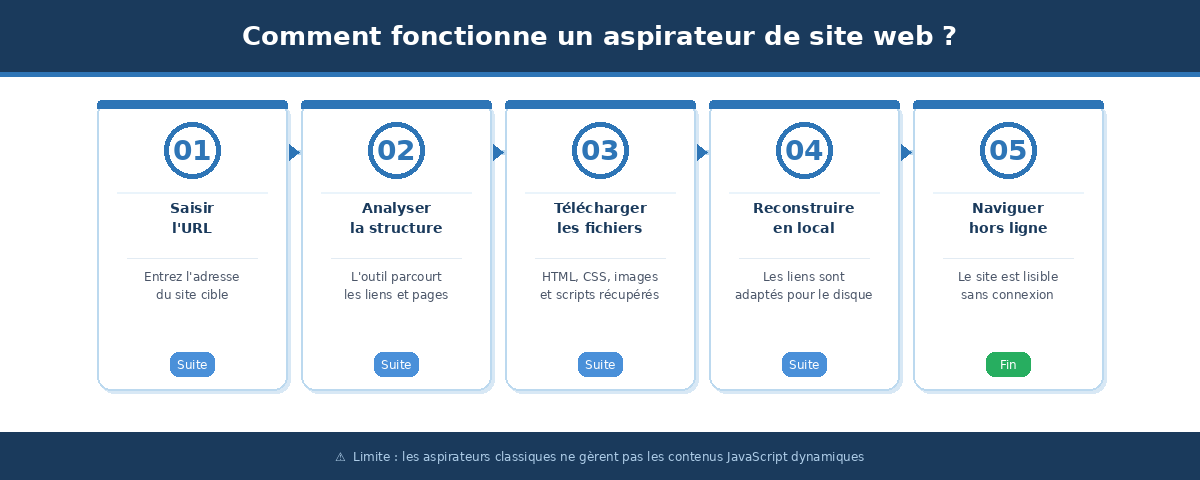
Concrètement, l’outil analyse la structure du site, suit chaque lien interne et récupère l’ensemble des fichiers : pages HTML, feuilles de style CSS, images, scripts JavaScript et autres ressources. Il reconstitue ensuite une copie locale navigable, avec des liens relatifs fonctionnels.
Pour accéder aux fichiers hébergés sur un serveur, certains outils utilisent le protocole FTP. Cependant, si le site repose sur un CMS comme WordPress ou Shopify, cette méthode ne récupère que les fichiers statiques générés : les bases de données et fonctionnalités dynamiques ne peuvent pas être dupliquées.
Un aspirateur de site couvre efficacement les contenus statiques (HTML, CSS, images). Pour les pages qui chargent leur contenu via JavaScript ou AJAX, c’est-à-dire la grande majorité des sites modernes, des outils de web scraping spécialisés sont nécessaires.
À qui s’adresse l’aspiration de site ?
Ce type d’outil est principalement utilisé par :
- les développeurs web qui souhaitent analyser la structure d’un site concurrent ou effectuer des tests hors ligne ;
- les responsables marketing et SEO qui veulent auditer l’architecture d’un site ou conserver une trace de ses évolutions ;
- les archivistes et chercheurs qui ont besoin de préserver des contenus web à un instant T ;
- les professionnels en mobilité souhaitant consulter des ressources sans connexion internet.
Pourquoi télécharger un site web ? Les cas d’usage concrets
Plusieurs raisons légitimes poussent à télécharger un site web :
- Archivage et sauvegarde : conserver une copie locale avant une migration, une refonte ou en cas de risque de perte de données.
- Consultation hors ligne : accéder à des ressources dans des zones à connectivité limitée (zones blanches en France, déplacements à l’étranger). Par exemple, un commercial itinérant qui prospecte dans des zones rurales sans 4G peut sauvegarder les fiches entreprises de PagesJaunes ou les annonces Leboncoin avant sa tournée, et les consulter sans connexion.
https://www.octoparse.fr/template/leboncoin-data-scraper
- Analyse SEO et structurelle : cartographier les liens internes, identifier des erreurs 404, étudier l’arborescence d’un site concurrent.
- Web scraping ciblé : extraire des données structurées (prix, descriptions, contacts) depuis un ou plusieurs sites, de façon automatisée et exportable. La méthode pratique est disponible ici : récupérer des données d’un site web vers Excel.
- Test et prototypage : reproduire un site pour le développement ou la démonstration client.
Dans tous les cas, il est indispensable de respecter les droits d’auteur et la législation en vigueur.
Aspirateur de site web vs Web Scraping : quelle différence ?
Ces deux approches sont souvent confondues, et la confusion coûte du temps. La distinction est pourtant simple :
Un aspirateur de site télécharge une copie complète des contenus statiques d’un site : pages HTML, images, fichiers CSS. L’objectif est de reproduire fidèlement l’ensemble du site pour le consulter hors ligne ou l’archiver.
Le web scraping fonctionne autrement : il extrait des données précises et structurées (prix, avis, coordonnées) à partir d’une ou plusieurs pages web. Les outils de scraping interagissent avec le DOM de la page, exécutent JavaScript si nécessaire et permettent d’automatiser la collecte à grande échelle.
Si vous voulez sauvegarder un site entier, utilisez un aspirateur. Si vous souhaitez extraire des informations spécifiques (prix, contacts, annonces), un outil de web scraping sera plus adapté, plus rapide et plus fiable.
Alternative efficace d’aspirateur de site – l’outil de web scraping
Vous cherchez une méthode plus simple ou plus ciblée pour collecter des données spécifiques ? Plutôt que de télécharger l’intégralité d’un site, Octoparse vous permet d’extraire précisément les données dont vous avez besoin — prix, contacts, descriptions — sans aucune connaissance en programmation.
Contrairement à un aspirateur de site classique, Octoparse interagit avec le contenu dynamique chargé via JavaScript, et permet une exportation directe vers Excel, Google Sheets ou CSV. Vous pouvez également programmer vos extractions pour qu’elles s’exécutent automatiquement, sans intervention manuelle.
Les catégories d’aspirateurs de site web
Il existe trois grandes familles d’outils pour aspirer un site web, auxquelles s’ajoute désormais une quatrième catégorie propulsée par l’IA :
- Logiciels desktop : installés sur votre ordinateur, ils offrent le niveau de configuration le plus avancé (gestion de la profondeur, des types de fichiers, des proxies). Idéaux pour les sites volumineux.
- Outils en ligne : accessibles depuis un navigateur, sans installation. Pratiques pour des besoins ponctuels, mais limités sur les sites complexes.
- Extensions navigateur : intégrées à Chrome ou Firefox, elles permettent une capture rapide d’une page ou d’un site léger en quelques clics.
- Outils propulsés par l’IA : une catégorie émergente qui ne télécharge pas le site, mais en extrait les données à la demande, via langage naturel. Cette approche est détaillée dans la section dédiée ci-dessous.
Certains utilisateurs recherchent un sniffer de site web ou un website sniffer pour analyser les ressources chargées par une page (requêtes HTTP, scripts, images). Ces outils sont distincts des aspirateurs classiques : ils inspectent le trafic réseau plutôt que de télécharger le contenu. L’outil le plus accessible pour cela reste l’onglet Réseau des outils de développement de votre navigateur (F12 dans Chrome, Firefox ou Edge), qui liste en temps réel toutes les ressources chargées par une page, sans aucune installation.
Comment aspirer un site web ?

Six outils ont été testés selon trois critères : facilité d’utilisation, compatibilité système et rapport qualité-prix. Voici les résultats.
HTTrack – La référence open source

Note : ⭐⭐⭐⭐⭐
Facilité : ⭐⭐⭐
Compatibilité : ⭐⭐⭐⭐⭐
Rapport qualité-prix : ⭐⭐⭐⭐⭐
HTTrack est l’outil de référence pour copier un site web sur votre disque dur. Il télécharge récursivement l’ensemble des répertoires et fichiers du serveur (HTML, images, vidéos) en conservant la structure des liens relatifs pour une navigation hors ligne fidèle.
Contrairement à un navigateur classique qui ne sauvegarde que la page en cours, HTTrack peut télécharger un site web complet, avec tous ses contenus liés.
Systèmes d’exploitation : WinHTTrack (Windows 7 à 11), WebHTTrack (Linux/Unix/BSD)
Comment télécharger un site web complet avec HTTrack ?
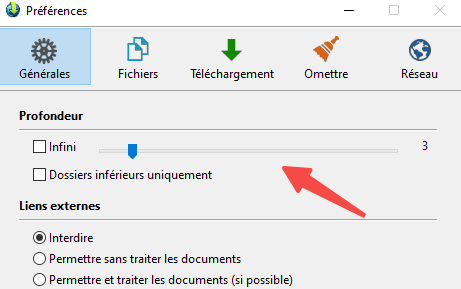
- Lancez HTTrack, rendez-vous dans Preferences pour passer l’interface en français (Options > Choix de la langue).
- Créez un nouveau projet, enregistrez-le dans un dossier sans accents ni espaces (ex. : C:\MesSitesWeb) pour éviter les erreurs.
- Saisissez l’URL cible et vérifiez que l’option “Copie automatique de site(s) Web” est sélectionnée.
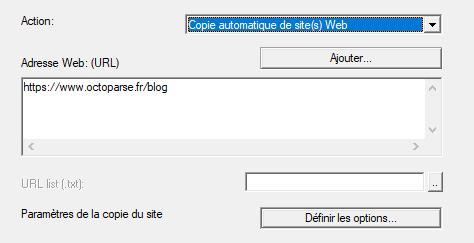
- Ajustez les options si besoin : profondeur de crawl, types de fichiers à exclure, délai entre requêtes.
- Cliquez sur “Terminer” pour lancer le téléchargement.
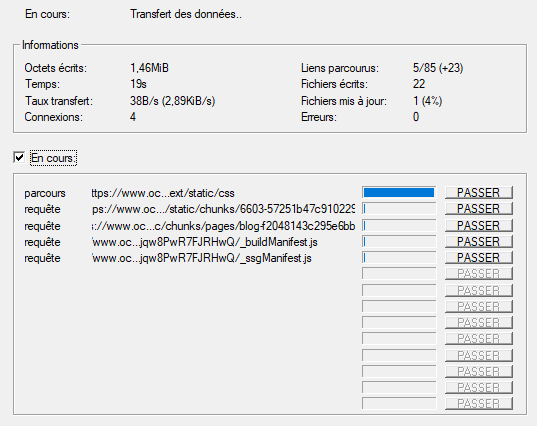
Pendant le téléchargement, cliquez pour voir les détails des fichiers en cours :
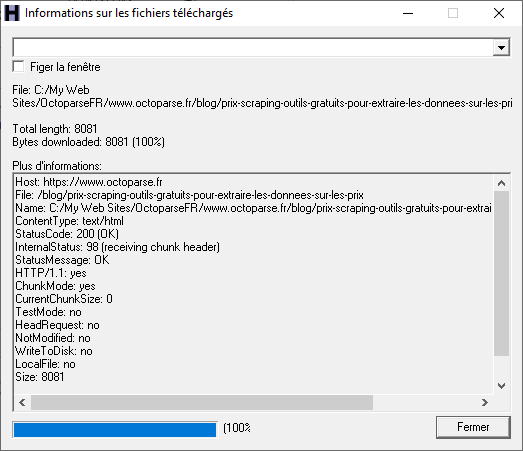
- À la fin, ouvrez le fichier index.html pour naviguer hors ligne.
Astuces
- Analysez la taille du site avant de lancer pour éviter les téléchargements interminables.
- Excluez les fichiers volumineux inutiles (vidéos, ZIP) via les filtres de type de fichiers.
- Limitez la profondeur de crawl si vous n’avez besoin que des pages principales.
Avantages
- Gratuit et open source
- Compatible Windows, Linux et BSD
- Préserve la structure des liens relatifs du site original
- Efficace sur les sites statiques volumineux
Inconvénients
- Interface datée, peu intuitive pour les débutants
- Mises à jour rares
- Inefficace sur les sites dynamiques ou en JavaScript
- Fréquemment bloqué par les protections anti-crawling modernes
- Peut être très lent sur des sites volumineux
Test et avis
Lors de nos tests, HTTrack a rencontré régulièrement l’erreur “MIRROR ERROR” sur des sites modernes utilisant des mesures anti-crawling (détection du User-Agent, limitation des requêtes). Pour y remédier, il faut modifier manuellement le User-Agent et réduire la vitesse de téléchargement. Ces ajustements restent accessibles aux profils techniques, mais s’avèrent fastidieux pour un utilisateur non averti.
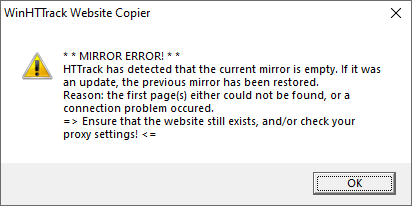
Pour copier un site web simple avec une structure statique, HTTrack reste le choix le plus complet et le plus éprouvé en 2026.
Cyotek WebCopy – Interface accessible pour débuter

Note : ⭐⭐⭐⭐
Facilité : ⭐⭐⭐⭐
Compatibilité : ⭐⭐
Rapport qualité-prix : ⭐⭐⭐⭐⭐
Cyotek WebCopy permet de copier des sites web partiels ou complets en local. L’outil analyse la structure du site et ajuste automatiquement les liens vers les ressources (images, feuilles de style, vidéos) pour un fonctionnement hors ligne.
Configuration minimale : Windows 10/8.1/8/7/Vista SP2, .NET Framework 4.6, 20 Mo d’espace disque.
Étapes clés
- Ouvrez le logiciel et saisissez l’URL du site cible.
- Conservez le dossier de sauvegarde par défaut (C:\Downloaded Web Sites) ou choisissez votre emplacement.
- Lancez la copie via le bouton “Copy” ou la touche F5.
- Une fois terminé, ouvrez le site copié dans l’Explorateur de fichiers via la flèche verte.
- Sauvegardez votre projet avec Ctrl+S.
Astuces
- Utilisez la fonction “Scan” avant de lancer la copie pour visualiser la structure et la profondeur du site.
- La fonction “Test URL” permet de vérifier la disponibilité de plusieurs URLs avant de démarrer.
Avantages
- Gratuit, interface claire et bien documentée
- Supporte HTTP, HTTPS et FTP
Inconvénients
- Exclusivement Windows
- Incapable d’extraire du contenu dynamique (JavaScript, AJAX)
- Peut nécessiter une configuration manuelle pour les sites complexes
- Problèmes de doublons signalés lors de reprises de téléchargement
Test et avis
Cyotek WebCopy convient bien aux sites statiques légers. Son interface claire en fait un bon point d’entrée pour les débutants. En revanche, sur les sites modernes utilisant JavaScript, les résultats sont décevants : de nombreux contenus sont simplement absents de la copie locale.
A1 Website Download – Mode simplifié avec filtres avancés

Note : ⭐⭐⭐⭐
Facilité : ⭐⭐⭐⭐
Compatibilité : ⭐⭐⭐⭐
Rapport qualité-prix : ⭐⭐⭐
A1 Website Download propose une approche guidée pour télécharger un site web complet sous forme de copie locale navigable. Il gère les sites multi-pages volumineux, les redirections, les frames, JavaScript et CSS.
Systèmes d’exploitation : Windows 11/10/8/7/Vista, macOS 10.8+
Comment aspirer un site web pour le consulter hors ligne ?
- Indiquez l’URL du site pour lancer le scan depuis la racine.
- Désactivez la correction automatique des liens et limitez la vitesse pour préserver le serveur.
- Ajoutez des filtres pour cibler précisément les pages à télécharger.
- Utilisez le mode simplifié (Easy Mode) pour une prise en main immédiate sans configuration avancée.

Avantages
- Compatible Windows et macOS
- Mode simplifié très accessible pour les non-techniciens
- Tutoriels vidéo et documentation fournis
- Détection des liens cassés intégrée
Inconvénients
- Période d’essai de 30 jours ; la licence complète est payante (tarif à vérifier sur le site officiel, autour de 39 $ selon les sources tierces). À peser selon la fréquence d’utilisation prévue.
- Vitesse de téléchargement limitée sur les grands sites
- Sur les sites dynamiques, seule une partie du contenu est récupérée
Test et avis
Le mode simplifié d’A1 Website Download permet de démarrer sans formation préalable. Toutefois, sur les sites complexes ou dynamiques, des réglages avancés restent nécessaires pour obtenir un résultat satisfaisant.
Web Dumper – À utiliser avec précaution

Note : ⭐⭐⭐
Facilité : ⭐⭐⭐
Compatibilité : ⭐⭐
Rapport qualité-prix : ⭐⭐
Web Dumper est un outil Windows qui analyse la structure d’un site, adapte les liens internes pour une consultation locale et offre des options de filtrage par type de fichier. Sa prise en main est rapide.
Configuration minimale : Windows 7/8/10, Java Runtime Environment 8+, 20 Mo.
Astuces
- Ajustez la profondeur de navigation pour limiter le téléchargement à une section précise du site.
Avantages
- Interface intuitive, adapté aux non-techniciens
- Configuration fine du processus de téléchargement
Inconvénients
- Outil peu maintenu : dernière mise à jour datant de plusieurs années
- Interface vieillissante
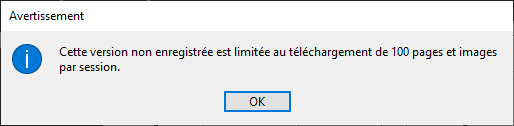
- Version gratuite très limitée (nombre de sites et images restreint) ; licence complète à 24,95 €
- Instable sur les sites dynamiques ou volumineux ; erreurs de timeout fréquentes
- Nécessite Java, ce qui alourdit l’installation
Test et avis
Web Dumper peut convenir pour des sauvegardes ponctuelles de pages statiques simples. Pour tout usage régulier ou sur des sites modernes, ses limitations techniques et son manque de maintenance récente le rendent difficile à recommander en 2026.
SiteSucker – La solution pour les utilisateurs Mac
Note : ⭐⭐⭐⭐
Facilité : ⭐⭐⭐⭐⭐
Compatibilité : ⭐
Rapport qualité-prix : ⭐⭐⭐
SiteSucker est une application payante macOS et iOS qui télécharge automatiquement tout ou partie d’un site web, en préservant sa structure et ses liens. Son interface claire en fait l’un des outils les plus simples à prendre en main.
Systèmes d’exploitation : macOS 12 Monterey ou supérieur, processeurs Intel ou Apple Silicon.
Astuces
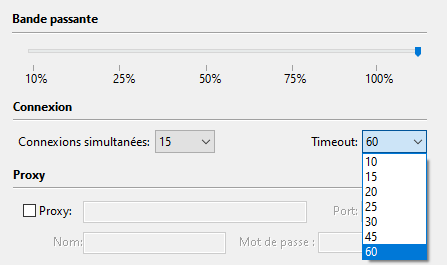
- Utilisez la fonction pause/reprise pour gérer les téléchargements en cas de connexion instable.
- Limitez le nombre de pages pour les sites volumineux afin d’éviter les plantages.
Avantages
- Interface extrêmement simple, prise en main immédiate
- Téléchargement automatique de sites HTML simples
- Personnalisation de la profondeur de crawl
Inconvénients
- Disponible uniquement sur Mac et iOS : aucune version Windows ou Linux
- 4,99 $ sur l’App Store
- Pas de reprise automatique en cas d’interruption
- Sur les sites WordPress ou PHP, la structure n’est pas toujours parfaitement préservée
Test et avis
SiteSucker est idéal pour les utilisateurs Mac qui ont besoin de sauvegarder ponctuellement des sites HTML simples. Au-delà de quelques centaines de pages, l’outil montre ses limites : pas d’indicateur de progression mémoire, impossibilité de prioriser une page précise.
Wget – La puissance en ligne de commande
Note : ⭐⭐⭐⭐
Facilité : ⭐⭐
Compatibilité : ⭐⭐⭐⭐⭐
Rapport qualité-prix : ⭐⭐⭐⭐⭐
Wget est un outil en ligne de commande gratuit et open source, disponible sur Linux, macOS et Windows (via WSL). Il permet de télécharger récursivement des sites web en conservant la structure des dossiers et des liens. Sa flexibilité et sa robustesse en font un favori pour les sauvegardes automatisées et les scripts.
Avantages
- Entièrement gratuit et open source
- Compatible Linux, macOS et Windows (via WSL ou ports natifs)
- Excellente gestion des redirections, authentifications, cookies et proxies
- Hautement scriptable pour des automatisations récurrentes
Inconvénients
- Aucune interface graphique : utilisation exclusive en ligne de commande
- Courbe d’apprentissage significative pour les non-développeurs
- Inefficace sur les sites utilisant JavaScript pour charger le contenu
Exemples de commandes Wget
- Télécharger un fichier unique :
wget https://example.com/fichier.zip
- Renommer le fichier lors du téléchargement :
wget -O nouveau_nom.zip https://example.com/fichier.zip
- Télécharger à partir d’une liste d’URLs :
wget -i liste_urls.txt
- Reprendre un téléchargement interrompu :
wget -c https://example.com/gros_fichier.zip
- Télécharger un site web complet en mode miroir :
wget –mirror –convert-links –page-requisites –no-parent https://example.com
Test et avis
Wget est l’outil de référence pour les profils techniques. Sa robustesse sur les protocoles HTTP, HTTPS et FTP en fait un choix solide pour les sauvegardes automatisées. Pour les utilisateurs non développeurs, la barrière de la ligne de commande reste un obstacle réel.
Aspirer un site web avec l’IA : une nouvelle approche en 2026
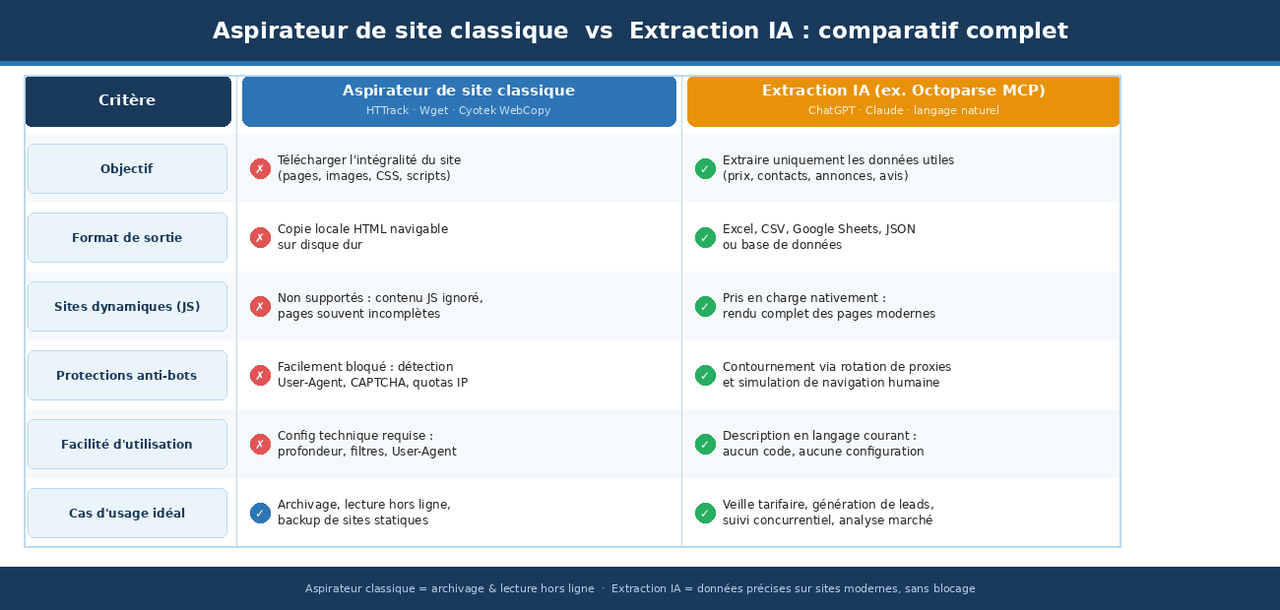
Tous les aspirateurs présentés ci-dessus partagent une limite structurelle commune : ils ne savent pas gérer les contenus chargés dynamiquement via JavaScript. Or, en 2026, la quasi-totalité des sites e-commerce, portails B2B et plateformes médias français utilisent ce type de rendu.
Face à ce constat, une nouvelle approche émerge : plutôt que de télécharger l’intégralité d’un site, extraire uniquement les données dont vous avez besoin, en indiquant à un outil IA ce que vous cherchez, en langage courant, sans écrire une seule ligne de code.
Octoparse MCP fonctionne sur ce principe : connecté à ChatGPT ou Claude, vous décrivez en langage courant les données souhaitées (prix, contacts, descriptions produits), et l’outil s’occupe de les extraire, y compris sur des pages dynamiques et derrière des protections anti-bots.
Pour aller plus loin : un tutoriel complet explique comment connecter ChatGPT à Octoparse pour scraper le web, et une introduction accessible détaille ce qu’est le protocole MCP et comment l’utiliser sans développement.
Si votre objectif est de sauvegarder un site statique pour le consulter hors ligne, un aspirateur classique reste la solution la plus directe. Si vous souhaitez extraire des données précises d’un site moderne, l’approche IA vous fera gagner 80 % du temps, tout en évitant les blocages techniques qui font perdre des heures.
Capacités clés pour « download any website offline »
Tous les outils ne se valent pas. Avant de télécharger le premier logiciel aspirateur de site qui apparaît dans les résultats, voici les critères qui font réellement la différence :
- Téléchargement récursif complet : l’outil doit parcourir tous les liens internes et récupérer l’ensemble des ressources liées.
- Préservation des liens relatifs : indispensable pour que la navigation hors ligne fonctionne correctement.
- Gestion des contenus statiques : HTML, CSS, images, documents PDF.
- Options de configuration avancées : profondeur de crawl, filtres de types de fichiers, gestion des cookies et sessions.
- Gestion des proxies : pour éviter les blocages sur les sites avec protection anti-crawling.
- Reprise en cas d’interruption : critique pour les sites volumineux, afin de ne pas repartir de zéro.
Les obstacles courants lors de l’aspiration de site
L’aspiration de site peut se heurter à plusieurs difficultés :
- Protections anti-bots et CAPTCHA : les sites modernes détectent et bloquent les outils automatisés. Plusieurs techniques existent pour contourner ces blocages, détaillées dans ce comparatif des solutions anti-CAPTCHA pour le web scraping. En France, des plateformes comme Leboncoin, SeLoger ou PagesJaunes intègrent des protections particulièrement robustes qui rendent l’aspiration classique quasi impossible. C’est l’une des situations où un outil de scraping spécialisé avec rotation de proxies devient indispensable.
- Contenu JavaScript dynamique : les aspirateurs classiques ne peuvent pas exécuter JavaScript et manquent une grande partie du contenu réel des pages modernes.
- Redirections excessives : certains sites multiplient les redirections, ce qui perturbe le crawl et génère des erreurs.
- Quotas de requêtes serveur : les serveurs peuvent limiter le nombre de requêtes par IP et par unité de temps, ralentissant ou bloquant le téléchargement.
- Sites volumineux : sur les sites de plusieurs milliers de pages, les aspirateurs peuvent devenir instables ou extrêmement lents si la gestion de la reprise n’est pas prévue.
Pour les cas complexes (sites dynamiques, protections anti-crawling, extraction de données structurées), Octoparse propose des mécanismes avancés (rotation de proxies, simulation de navigation humaine) qui permettent de contourner ces obstacles tout en respectant les conditions d’utilisation du site cible.
Aspirer un site web sans logiciel
Vous pouvez sauvegarder une page web rapidement en faisant un clic droit et en sélectionnant “Enregistrer sous”. Cette méthode ne récupère que la page en cours, sans les liens associés.
D’autres solutions existent pour éviter l’installation d’un logiciel :
Les aspirateurs de site web en ligne
Websitedownloader
WebsiteDownloader permet d’aspirer un site complet en ligne, y compris ses liens internes, sans aucune installation. Son fonctionnement est simple : saisissez l’URL, lancez la copie.
Note : ⭐⭐⭐
- Accessible depuis n’importe quel navigateur
- Aspiration de sites complets avec liens internes
- Fonctionne bien sur les sites statiques simples ; les sites dynamiques avec JavaScript ne sont pas pris en charge. Pour les besoins plus avancés, l’outil payant websitedownloader.com propose des exports en HTML, Word et PDF avec des plans à partir de quelques dollars par téléchargement.
- Pas de reprise automatique en cas d’interruption
Archivarix
Archivarix est un outil en ligne permettant de télécharger une page ou un site à partir de son URL. Une inscription gratuite est nécessaire. Particulièrement utile pour récupérer des versions archivées de pages.
Note : ⭐⭐⭐
- Utile pour récupérer des versions archivées de pages web
- Interface simple, prise en main immédiate
- Limité aux sites statiques : les contenus JavaScript ne sont pas restitués
- Nécessite une inscription même pour l’usage gratuit
Ces outils en ligne fonctionnent correctement sur les sites statiques simples. Sur les sites modernes utilisant JavaScript, les contenus chargés dynamiquement ou les pages nécessitant une authentification, leurs résultats sont généralement incomplets.
Les extensions Chrome pour le téléchargement de pages web
Website Downloader
Website Downloader explore automatiquement les sites et télécharge leur contenu sans intervention manuelle complexe.
Note : ⭐⭐⭐
- Fonctionne sur Chrome, quelle que soit la plateforme
- Peut télécharger un site entier avec ses liens internes
- Essai gratuit de 3 jours, puis 5,99 €/semaine : le rapport qualité-prix est à peser selon votre fréquence d’utilisation.
WebScrapBook
WebScrapBook est une extension avancée pour sauvegarder fidèlement des pages web avec plusieurs formats d’archivage.
Note : ⭐⭐⭐⭐
- Capture fidèle incluant images, styles et éléments interactifs
- Organisation avancée : dossiers, tags, recherche pleine texte, annotations
- Compatible Chrome, Firefox, Edge et navigateurs mobiles
- Configuration plus complexe pour les débutants
SingleFile
SingleFile est l’extension la plus utilisée en France pour sauvegarder une page web complète en un seul fichier HTML autonome. Entièrement gratuite, elle capture fidèlement CSS, images et polices.
Note : ⭐⭐⭐⭐⭐
- Entièrement gratuite et open source
- Sauvegarde en un seul fichier HTML : pratique pour le partage et l’archivage
- Compatible Chrome, Firefox, Edge, Safari, Brave et Opera
- Très populaire dans la communauté française des développeurs et journalistes
- Limitée à une page à la fois (pas de crawl multi-pages)
Tableau comparatif des aspirateurs de site web
Voici un comparatif synthétique pour vous aider à choisir l’outil adapté à votre situation :
| Outil | Plateforme | Prix | Support JS | Hors ligne | Extraction ciblée | Maint. active | Facilité | Note |
| HTTrack | Win/ Linux/ BSD | Gratuit | ✗ | ✓ | ✗ | Partielle | ⭐⭐⭐ | ⭐⭐⭐ ⭐⭐ |
| Cyotek WebCopy | Windows | Gratuit | ✗ | ✓ | ✗ | Oui | ⭐⭐⭐ ⭐ | ⭐⭐⭐ ⭐ |
| A1 Website Download | Win/ Mac | ~39 $ | Partiel | ✓ | ✗ | Limitée | ⭐⭐⭐ ⭐ | ⭐⭐⭐ ⭐ |
| Web Dumper | Windows | 24,95 € | ✗ | ✓ | ✗ | Faible | ⭐⭐⭐ | ⭐⭐⭐ |
| SiteSucker | macOS/ iOS | 4,99 $ | ✗ | ✓ | ✗ | Oui | ⭐⭐⭐ ⭐ | ⭐⭐⭐ ⭐ |
| Wget | Linux/ Mac/ Win | Gratuit | ✗ | ✓ | ✗ | Oui | ⭐⭐ | ⭐⭐⭐ ⭐ |
Les colonnes “Support JS”, “Extraction ciblée” et “Maint. active” ont été ajoutées pour refléter les critères les plus pertinents en 2026.
Ces outils fonctionnent sur les sites statiques. Dès qu’il s’agit d’extraire des prix depuis un e-commerce, de récupérer des coordonnées sur PagesJaunes ou de surveiller des annonces Leboncoin, aucun d’entre eux n’est à la hauteur. Essayez Octoparse 14 jours et évaluez le résultat sur votre cas d’usage réel.
Légalité et bonnes pratiques en France
Avant de télécharger ou de copier du contenu web, il est indispensable de respecter les droits d’auteur et la propriété intellectuelle.
En France, la reproduction non autorisée de contenus protégés est encadrée par le Code de la Propriété Intellectuelle (CPI). Copier un site sans autorisation peut constituer une contrefaçon et entraîner des sanctions civiles et pénales.
Pour les données personnelles, la collecte automatisée est encadrée par le RGPD. La CNIL rappelle que toute collecte de données relatives à des personnes physiques identifiables, même publiquement accessibles, doit respecter les principes de minimisation et de finalité. En cas de doute sur la légalité de votre démarche, consultez le guide RGPD de la CNIL avant de lancer une extraction.
Respectez également le fichier robots.txt du site cible : il indique si le site autorise ou interdit l’exploration par des outils automatisés.
Pour approfondir ce sujet : un article détaillé couvre les limites légales et techniques à connaître avant de scraper.
Utilisez ces outils uniquement à des fins personnelles, éducatives ou professionnelles légitimes, et avec l’autorisation du propriétaire du contenu si nécessaire.
Cloner un site web : quand l’aspirateur ne suffit plus
L’aspiration de site couvre les besoins d’archivage et de consultation hors ligne. Mais si votre objectif est de reproduire la structure d’un site pour le développement, la migration ou la création d’un prototype, les aspirateurs traditionnels montrent rapidement leurs limites.
Si votre objectif va au-delà de la simple sauvegarde, des approches spécialisées permettent de cloner un site web, d’en dupliquer l’architecture ou d’en extraire les données à grande échelle. Un comparatif complet de ces méthodes est disponible ici : tout savoir sur le clonage de site web en 2026.
Si votre cas d’usage touche à l’analyse de profils LinkedIn ou à la collecte de données professionnelles, un guide dédié à l’extraction de données LinkedIn couvre ces scénarios en détail.
En conclusion
Les aspirateurs de site web restent des outils utiles pour archiver des sites statiques ou les consulter hors ligne. HTTrack et Wget s’imposent pour les profils techniques, Cyotek WebCopy et SiteSucker pour les utilisateurs en quête de simplicité.
En 2026, ces outils atteignent leurs limites dès que le site cible utilise JavaScript pour charger son contenu, ce qui représente la grande majorité des plateformes françaises actives. Si vous avez besoin d’extraire des données (prix, contacts, annonces) plutôt que de simplement sauvegarder des pages, une solution d’extraction ciblée sera plus rapide, plus fiable et vous fera gagner du temps à chaque nouvelle collecte.
Pour toute question ou besoin d’assistance : support@octoparse.com.

Fonctionne sur tous les sites, y compris ceux chargés en JavaScript.
Extrait uniquement les données dont vous avez besoin : prix, contacts, annonces.
Export direct en Excel, CSV ou Google Sheets, sans manipulation manuelle.
Ne se retrouve jamais bloqué grâce à la rotation de proxies IP intégrée.
Programmez vos extractions en Cloud : les données arrivent automatiquement.
FAQ
- Qu’est-ce qu’un aspirateur de site web ?
Un aspirateur de site web est un logiciel qui télécharge l’ensemble des fichiers d’un site (HTML, CSS, images, scripts) pour en créer une copie locale consultable hors ligne. Il reconstitue la structure du site avec des liens relatifs fonctionnels. Efficace sur les sites statiques, il montre ses limites face aux contenus chargés dynamiquement via JavaScript.
- Quel est le meilleur aspirateur de site web gratuit en 2026 ?
Pour un usage général sur Windows, Cyotek WebCopy reste une valeur sûre gratuite. HTTrack est la référence open source multi-plateforme. Pour les utilisateurs Mac, SiteSucker (4,99 $) offre la meilleure expérience. Pour une simple page, l’extension SingleFile (Chrome/Firefox) est la solution la plus rapide et entièrement gratuite.
- Comment aspirer un site web protégé ?
Les sites protégés utilisent des mesures anti-crawling comme le CAPTCHA, la détection du User-Agent ou la limitation de requêtes. Pour tenter de les aspirer :
- Modifiez le User-Agent dans les paramètres du logiciel pour simuler un navigateur classique.
- Réduisez la vitesse de téléchargement pour éviter la détection.
- Des pistes concrètes sont réunies dans ce comparatif des solutions anti-CAPTCHA pour le web scraping.
Attention : contourner les protections d’un site peut être contraire à ses conditions d’utilisation. Vérifiez toujours la légalité de votre démarche.
- Comment aspirer un site web pour le consulter hors ligne ?
Utilisez HTTrack (Windows/Linux) ou SiteSucker (Mac) pour télécharger le site complet avec ses ressources. Ouvrez ensuite le fichier index.html depuis votre dossier local. Pour les sites dynamiques, les résultats seront partiels : dans ce cas, une approche de web scraping ciblé donnera de meilleurs résultats.
- Comment aspirer un site web complet avec HTTrack ?
Lancez HTTrack, créez un nouveau projet dans un dossier sans accents, saisissez l’URL cible, sélectionnez “Copie automatique de site(s) Web”, ajustez la profondeur et les filtres si nécessaire, puis cliquez sur “Terminer”. À la fin du téléchargement, naviguez depuis le fichier index.html.
- Quelle est la différence entre un aspirateur de site et le web scraping ?
L’aspirateur télécharge une copie complète du site (pages, images, CSS) pour la consultation hors ligne. Le web scraping extrait des données précises et structurées (prix, contacts, avis) pour les exploiter dans un tableur ou une base de données. Les deux approches sont complémentaires selon l’objectif visé.
- Existe-t-il des aspirateurs de site web en ligne gratuits ?
Oui : WebsiteDownloader et Archivarix proposent des versions gratuites avec limitations. Pour des besoins ponctuels sur des sites statiques simples, ils suffisent. Au-delà, les logiciels desktop offrent bien plus de contrôle.
- Comment télécharger un site web en local ?
Utilisez HTTrack, Cyotek WebCopy ou A1 Website Download pour télécharger l’intégralité du site avec ses pages, images et ressources. Configurez la profondeur de crawl selon vos besoins. Pour extraire des données spécifiques plutôt que de télécharger le site entier, un outil de web scraping no-code sera plus adapté : il cible uniquement les données souhaitées et les exporte directement en Excel, CSV ou Google Sheets. Octoparse est l’une des solutions les plus utilisées en France pour ce type d’usage.
- Comment télécharger une page web en PDF ?
Depuis votre navigateur (Chrome, Firefox, Edge), appuyez sur Ctrl+P (ou Cmd+P sur Mac), sélectionnez “Enregistrer au format PDF” comme destination d’impression, et confirmez. Cette méthode fonctionne sur n’importe quelle page web.
- Est-ce légal d’aspirer un site web en France ?
L’aspiration de site est légale dans le cadre d’un usage personnel ou éducatif, à condition de respecter le fichier robots.txt du site, le Code de la Propriété Intellectuelle français et le RGPD pour les données personnelles. La reproduction commerciale ou la réutilisation de contenus protégés sans autorisation est en revanche illégale. En cas de doute, la documentation officielle de la CNIL reste la référence pour les bonnes pratiques en matière de collecte de données en France.
- Peut-on aspirer un site web sur Android ou mobile ?
Les aspirateurs professionnels sont conçus pour Windows, macOS et Linux. Sur Android, les options sont limitées : quelques applications de capture de page existent sur le Play Store, mais leur efficacité reste faible sur les sites complexes. Pour une extraction de données depuis mobile, les solutions cloud comme Octoparse permettent de programmer des tâches accessibles depuis n’importe quel appareil.
- Comment télécharger des vidéos depuis un site web ?
Des extensions navigateur ou des outils en ligne permettent de récupérer une vidéo depuis son URL. Pour extraire des listes de liens vidéo en masse depuis YouTube ou d’autres plateformes, un template de scraping dédié automatise cette collecte en quelques clics.
Des logiciels comme VLC ou 4K Video Downloader permettent ensuite de télécharger les vidéos en haute qualité.
- Comment copier un site web entier gratuitement ?
Pour copier un site web en local, HTTrack (Windows/Linux) reste la solution gratuite la plus complète : il reproduit la structure du site avec tous ses fichiers et ses liens relatifs. Sur Mac, SiteSucker propose une interface plus intuitive pour un résultat similaire. Si vous souhaitez copier non pas l’apparence du site mais ses données (prix, descriptions, contacts), un outil de web scraping sera plus adapté et exportera directement les résultats en Excel ou CSV, sans manipulation manuelle.