Quand nous disons « news scraping », on parle toujours des données à partir de la presse, des chapeaux, des textes (y compris des titres du corps, des dates de publication, des auteurs et catégories ou tags), des tableaux ou des photos publiés sur les sites d’actualité. Normalement, le news scraping désigne l’automatisation de la collecte structurée de données provenant de sources journalistiques en ligne.
Selon Statista, le chiffre d’affaires cumulé des quotidiens numériques était prévisible à plus de 322 millions de dollars et celui des magazines numériques à plus de 362 millions de dollars en 2024. Bien entendu, la place de la presse reste l’information essentielle, d’où le news scraping de plus en plus prisé par le plus grand nombre d’utilisateurs, chercheurs, analystes, experts pour mieux gérer et ordonner différents types de données en provenance de plusieurs plateformes.
Nous vous proposons aujourd’hui le tutoriel usuel sur Le Figaro par rapport à la récupération de données journalistiques avec Octoparse. Cela vous aidera à analyser les tendances internationales, à suivre le développement du business, à favoriser votre agrégateur d’actualité par news scraping, etc. Le plus important, c’est d’établir votre propre base de données d’information.
Le Figaro, le site d’information en continu
Fondé en 1826, Le Figaro appartient au panthéon des titres historiques de la presse française. C’est un journal riche en information tant sur les plans de l’actualité politique, économique, culturelle, internationale que sur la pertinence de ses analyses, souvent fouillées et bien étayées. Nous avons d’un côté des archives, permettant d’avoir accès à une information historique plus complète, et de l’autre côté — on peut s’y tenir à jour — les rubriques de Le Figaro servant de base à la veille concurrentielle ou au suivi de sujets d’intérêt.
Les atouts d’Octoparse pour le scraping sur Le Figaro
La facilité d’utilisation sans coder
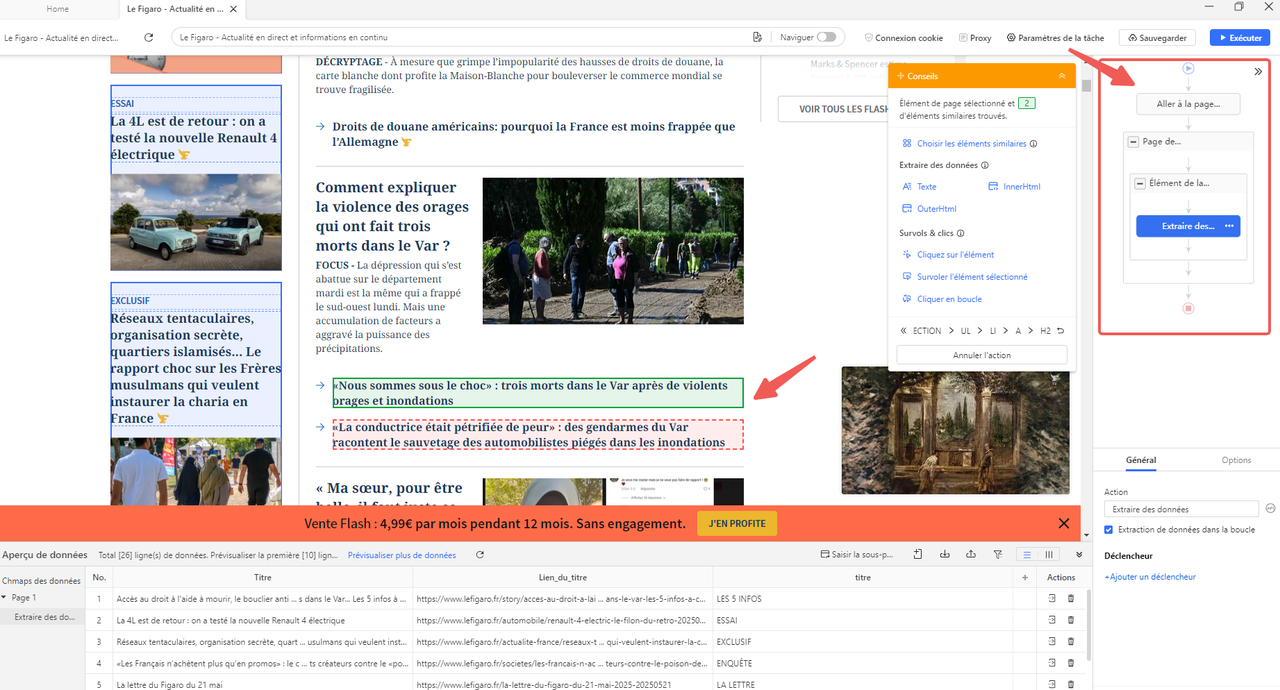
Avec Octoparse, après avoir importé l’URL du Figaro, vous pouvez extraire les données désirées simplement en cliquant sur les éléments sur l’écran, tels que les titres, les images, les chiffres, les textes structurés indiqués ci-dessous, etc. La partie du flux de travail est située à votre droite, il est capable de bouger ou traîner les icônes dedans pour régler les ordres de la création de votre propre crawler du web. Par exemple, vous voulez tout d’abord extraire les images et après les textes. Bien sûr, des actions comme la pagination, cliquer sur quelque élément en boucle sont envisagées pour votre tâche personnalisée.
La fonctionnalités puissantes
Les utilisateurs peuvent configurer les résultats de l’aperçu de données depuis un nouveau flux en temps réel avec Octoparse pour n’importe quels champs de données vers certains articles depuis la page d’accueil ou une section spécifique du Figaro. Des fonctions telles que les expressions XPath ou les affinements de données vous permettent d’extraire les données plus précises, comme les opérations d’ajouter des préfixes ou des suffixes dans les noms des auteurs, de supprimer les espaces des chapeaux, de reformater la date de publication, etc. Selon vos besoins, vous pouvez exporter les données en CSV, Excel ou base de données d’actualité.
La possibilité d’automatisation
Grâce à l’auto-détection, Octoparse est capable de localiser automatiquement les modifications dans la structure du site du Figaro, assurant ainsi une extraction de données fluide et ininterrompue. En pratique, il est suffisant de trier ou de supprimer certains champs pour que les données collectées correspondent précisément à vos catégories visées. Octoparse permet aux utilisateurs de programmer des extractions récurrentes depuis le tableau de bord — à une fréquence horaire ou quotidienne, ce qui rend possible une veille automatisée des actualités dès leur mise en ligne, y compris l’auto-exportation de bases de données en programmant le temps souhaité, par exemple, l’exportation est planifiée pour être exécutée toutes les 1 heure dans la capture d’écran.
L’extraction de fil d’actualités du Figaro sans coder
Étape 1 : Créer un nouveau workflow
Entrez le lien de votre site ciblé du Figaro dans la page d’accueil d’Octoparse, puis vous pouvez sélectionner manuellement les éléments désirés pour créer un nouveau flux de travail sur Octoparse.
En même temps, il est aussi possible d’activer l’auto-détection dans la boîte de conseils et d’attendre qu’elle se termine pour positionner les données de l’écran.
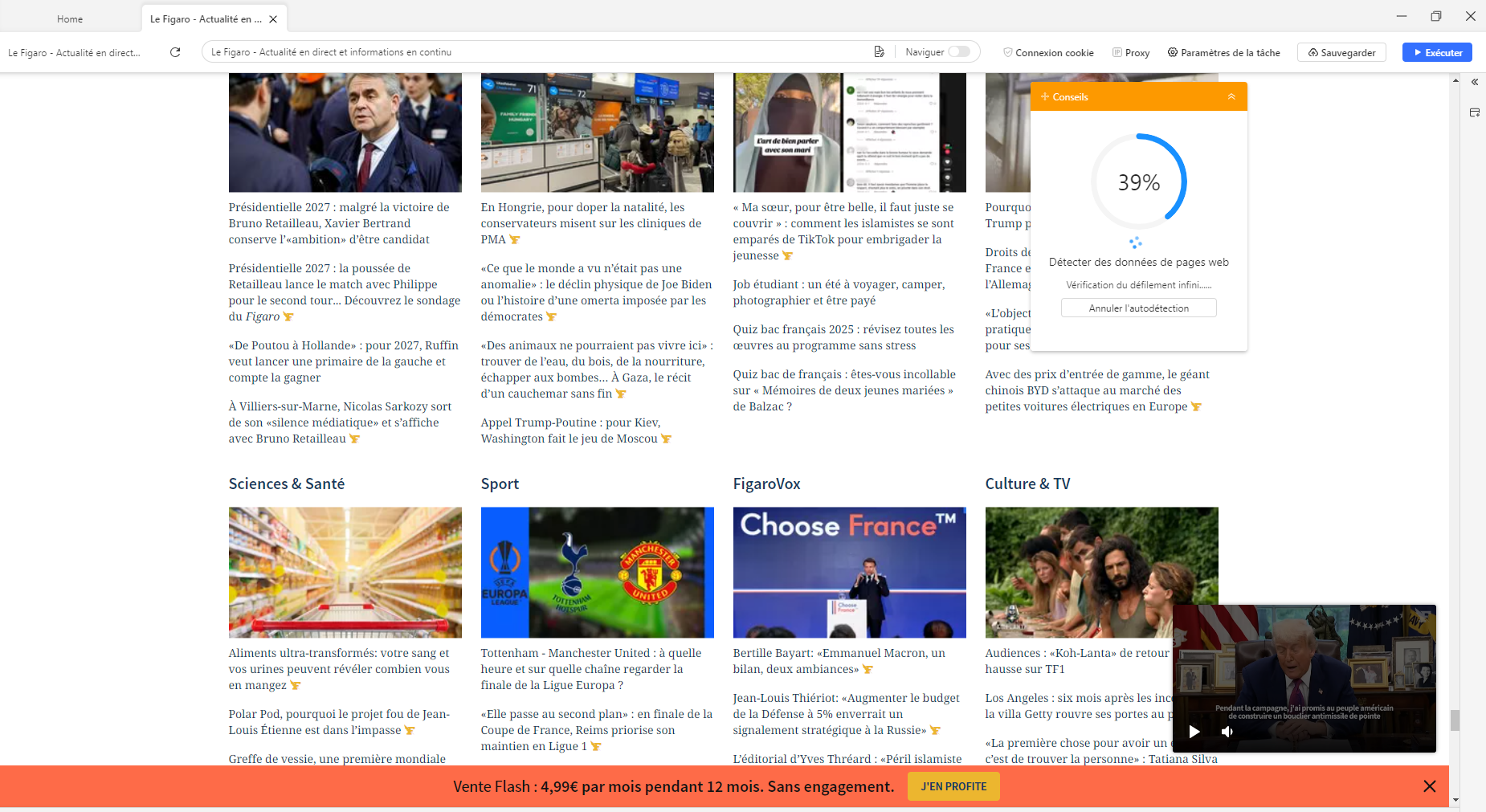
Octoparse génère automatiquement un flux de travail en s’appuyant sur vos interactions avec la page Web et sur les indications fournies dans le panneau de conseils.
Étape 2 : Sélectionner les données et planifier propre crawler du web
Une fois le flux de travail vérifié, il est possible de gérer les champs de données si nécessaire : les renommer, les nettoyer, les supprimer ou en télécharger via le panneau Aperçu des données.
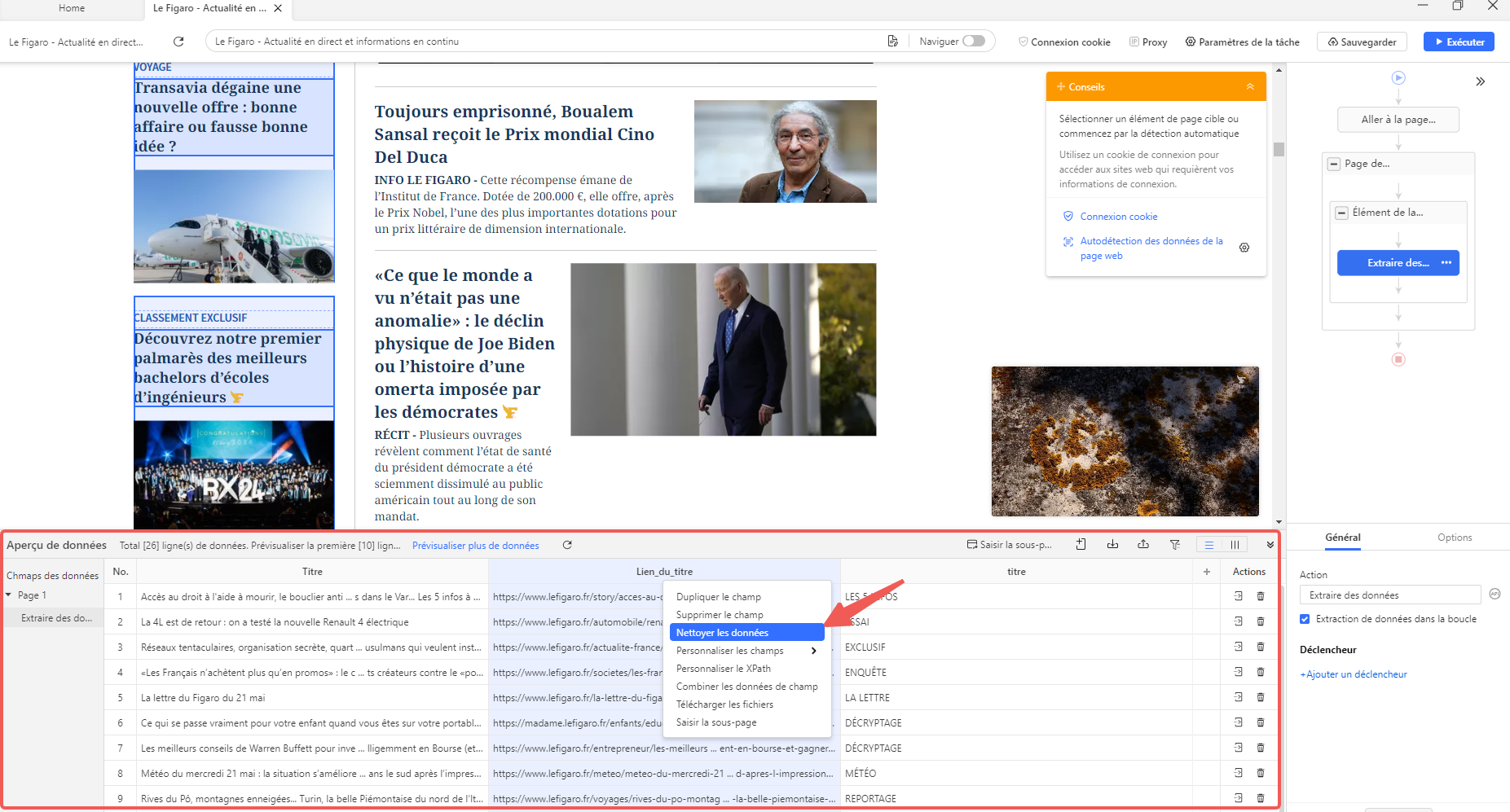
L’exécution de la tâche se fait ensuite en cliquant sur le bouton “Exécuter” en haut à droite, que ce soit localement sur l’appareil ou à distance via le Cloud.
Étape 3 : Extraire les données d’actualité
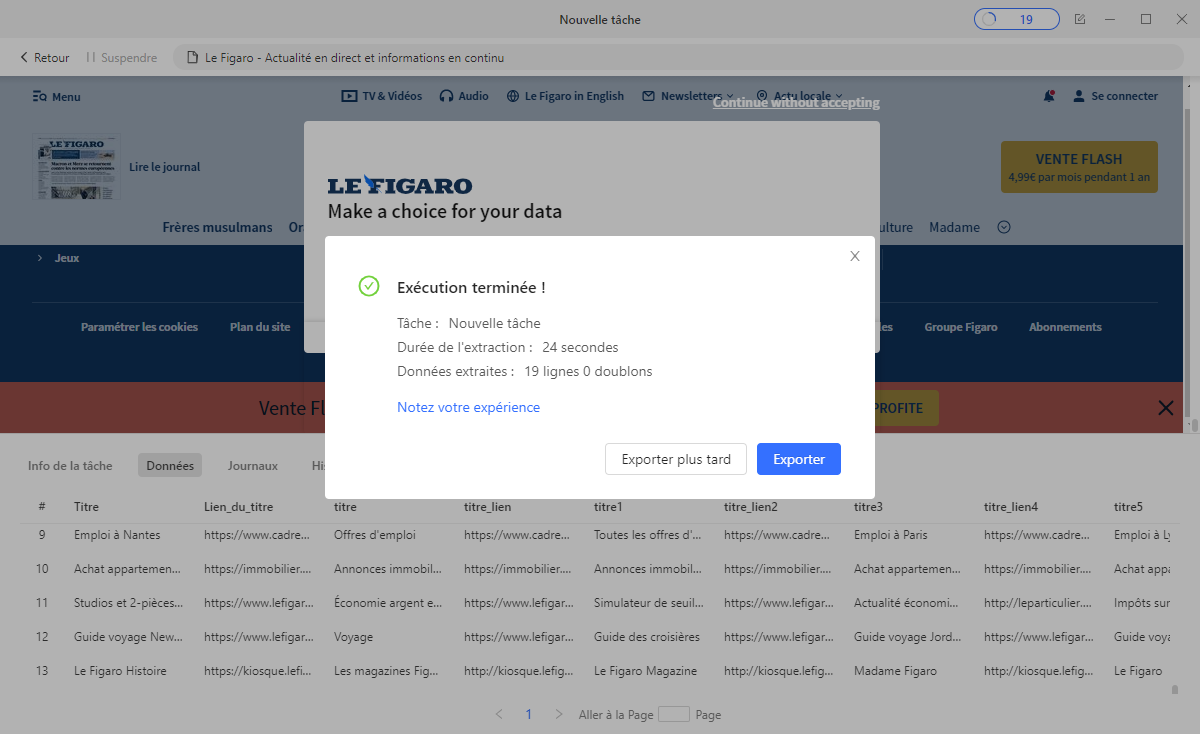
Après l’exécution terminée, vous pouvez cliquer sur le bouton “Exporter” pour exporter les données vers votre base de données sur Octoparse. Choisissez le format de vos données, tel qu’Excel, CSV, HTML, JSON, etc., ou sélectionnez le type de votre base de données, comme Google Sheets, SQLserver d’après vos besoins.
Les plateformes françaises pertinentes pour le scraping
Pour réaliser le scraping de contenus d’actualités en France, il est pertinent de choisir des sites influents parmi lesquels on peut notamment consulter des sites d’actualités nationaux tels que Le Monde, France Info, Libération, etc.
Si cela vous intéresse, je vous propose d’utiliser le modèle du scraper leMonde pour capturer l’information que vous désirez plus rapidement, si vous cliquez sur le lien ci-dessous pour l’utiliser :
https://www.octoparse.fr/template/le-monde-rubrique-scraper
Autre solution, utiliser des plateformes spécialisées ou agrégateurs de news français, comme Google News, Feedly, Flockler, rassemblant plusieurs titres au même endroit, ce qui constitue le gain de temps pour l’agrégation.
Les conseils pour optimiser le scraping avec Octoparse
Dans l’optique de rendre encore plus performante votre activité de scraping avec Octoparse, vous disposez de la possibilité de faire appel à des stratégies de rotation IP. Cela permet d’éviter le blocage de son adresse IP par les sites cibles.
Par ailleurs, automatiser la planification des sessions d’extraction constitue un atout utile pour effectuer une veille régulière et efficace, sans avoir à intervenir manuellement à chaque fois.
Bien sûr, vous pouvez trouver plus des solutions adaptées dans la bibliothèque de modèles d’Octoparse(ayant plus de 500 modèles personnalisés dans le monde entier), vous pouvez cliquer sur le lien du modèle Bing Actualités Scraper ci-dessous pour collecter le contenu dont vous avez besoin dans le nouveau moteur de recherche de Microsoft – Bing:
https://www.octoparse.fr/template/bing-actualites-scraper
Conclusion
Le scraping d’actualités avec Octoparse paraît être un outil intéressant offrant simplicité d’utilisation et automatisation de la collecte, de l’analyse et du traitement des données quant au fil de l’actualité du Figaro et autres sites comme Le Monde.
Un gain de temps et une meilleure précision des résultats qui nous permettront de tirer le meilleur parti de ce service et de créer notre propre base informationnelle et fiable. Téléchargez sans plus tarder Octoparse pour gérer votre veille informationnelle !



