Quand on fait le web scraping sur des pages Web, on scrape en effet le HTML qui contient nos données désirées. Quand on aborde une page avec une implémentation JavaScript, on n’obtiendra les données qu’après un processus de rendering. Dans ce cas-là, si on continue d’utiliser un packet de requêtes normales, la réponse renvoyée ne contiennent pas de données.
Dans cet article de blog, on va voir comment faire le web scraping sur une page Web en JavaScript, et ce qui est plus fascinant, il s’agit d’une méthode sans coder.
Le web scraping sur une page en JavaScript
JavaScript est l’un des trois languages que tous les programmeurs devraient apprendre, c’est aussi l’un des langugages le plus utilisés et le plus facile à apprendre.
Ce langage a été normalisé dans la spécification de langage ECMAScript. Avec HTML et CSS, c’est l’une des trois technologies de base de la production de contenu sur le World Wide Web. Pour une page Web, le HTML sert à définir le contenu affiché sur des pages Web, le CSS à spécifier la mise en page de ce conteu, tandis que JavaScript est destiné à programmer le comportement des pages Web.
JavaScript est un langage de programmation informatique dynamique. Il aide les développeurs à ajouter des fonctionnalités complexes à leur site Web, comme l’affichage de contenu dynamique, de cartes interactives, de juke-boxes vidéo défilants, etc. Chaque fois qu’un site Web fait plus que présenter des informations statistiques, le JavaScript est probablement utilisé.
Il est le plus souvent utilisé comme une partie des navigateurs web. Sa mise en oeuvre permet aux scripts côté client (client side script en anglais) de s’intergir avec l’utilisateur, de contrôler le navigateur, de faire la communication asynchrone, de modifier le contenu des documents affichés. JavaScript est également utilisé pour la programmation côté serveur, pour développer des jeux et créer des appplications de bureau et mobiles.
Ajax
Ajax, abréviation de Asynchronous JavaScript and XML, est un ensemble de techniques de développement Web qui permet à une page Web de mettre à jour des parties de contenu sans avoir à recharger toute la page.
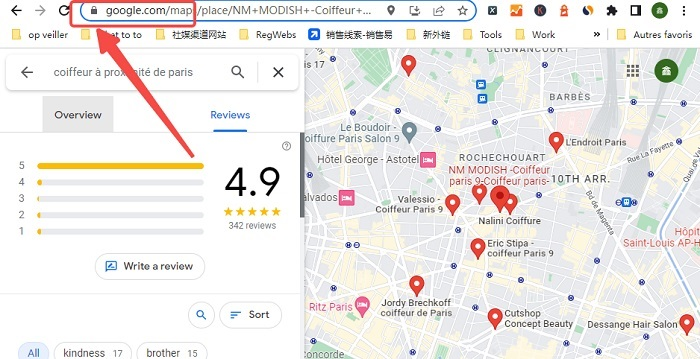
En effet, si votre but est d’extaire des données, vous n’avez pas besoin d’en savoir beaucoup sur Ajax. Il vous suffit de déterminer si le site à scraper utilise Ajax ou non. De nombreux sites Web appliquent beaucoup d’Ajax, comme Google, Amazon et eBay. Si un site applique Ajax, on peut remarquer que l’URL de la page ne sera pas modifié lors de la mises à jour d’une nouvelle partie de contenu.
Ce n’est pas du tout difficile de décider s’il s’agit d’Ajax ou pas. Les pages Ajax ont deux caractéristiques distinctives : elles ne rechargent pas la page entière et de nouvelles données apparaissent partiellement sur la page après qu’on clique dessus. “elles ne rechargent pas la page entière” veur dire que : il n’y a pas de signe de rechargement, soit après un clic, cet onglet ne tourne pas.
Solution pour scraper les pages JavaScript
En ce qui concerne la gestion d’Ajax et de JavaScript pendant le web scraping, les choses deviennent parfois assez compliquées, surtout si vous êtes un novice en informatique. J’ai reçu beaucoup de questions sur le scraping AJAX et JavaScript ces derniers temps et j’ai compilé les questions le plus souvent posées :
- Comment puis-je extraire le contenu qui se défile infiniment sur un site AJAX ?
- Comment scraper les données et cliquer sur le bouton de chargement ou le bouton de “Suivant” ?Octoparse peut-il extraire le contenu dynamique de sites Web utilisant AJAX ?
- Puis-je extraire des données d’un site Web avec pagination ?
- Puis-je extraire des données de sites Web qui chargent dynamiquement des données (comme Twitter) ?
- Puis-je crawler un site web qui charge du contenu en utilisant Javascript ?
Parfois, si on découvre que un site chargement son contenu avec AJAX, il pense que ce site ne peut être scrapé. Si vous vous lancez maintenant dans le Python et la construction d’un web scraper, cela ne va pas être facile. Donc, pour ceux qui sont à la recherche d’un moyen simple de scraper les pages en JavaScript rapidement, des applications tierces semblent un bon choix.
Les jours sont passés où vous devez utiliser Python, Ruby ou d’autres langages pour faire le web scraping. Octoparse est là, est un bon outil pour scraper les sites Web qui mettent en oeuvre JavaScript. Ce qui semble beaucoup fascinant, c’est que Octoparse n’exige aucune connaissance en codage.
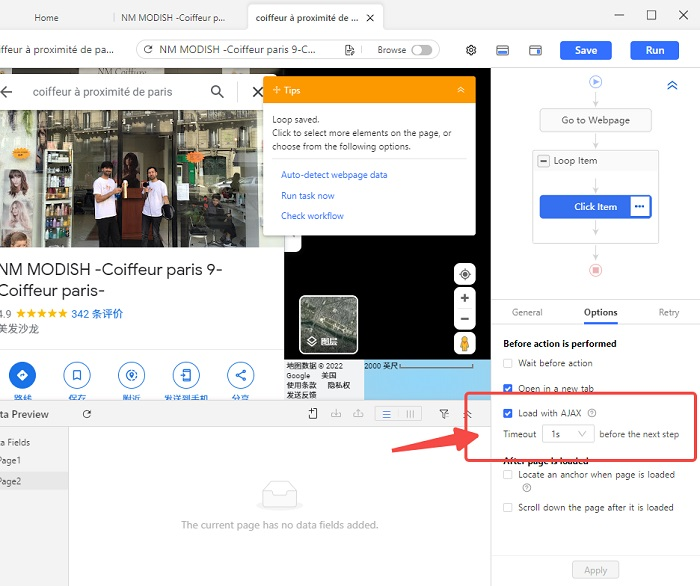
Dans Octoparse, le rechargement est utilisé comme un signal pour exécuter le clic. Si une page recharge son contenu après un clic, le robot va exécuter l’action suivante à la fin du rechargement. Mais si une page avec AJAX qui ne se recharge pas, Octoparse ne reçoit pas le signal de procéder à l’action suivante, et donc bloqué. C’est pourquoi il est nécessaire de configurer un timeout AJAX pour les actions de “click item” ou “click to paginate”. Il y a deux façons de gérer l’AJAX dans Octoparse.
- Détection automatique d’AJAX
Octoparse configure AJAX timeout automatiquement si une page AJAX est détectée. Si vous voulez un délai d’attente plus long ou plus court, il vous suffit de cliquer sur le menu déroulant pour choisir ce qui vous convient.
2. Configuration manuelle d’AJAX
Au cas où Octoparse ne parvient pas à détecter AJAX, il est également possible de faire des configurations manuellement. Il suffit de cliquer la case de “Click” ou de “Click to paginate” dans le workflow pour trouver les paramètres relatifs dans le panneau de “Options”.
Une version totalment grauite est disponible dans Octoparse ! Allez faire des essais !



