Extraire le texte d’un fichier HTML est littéralement la même chose que copier et coller les informations d’une page Web dans un bloc-notes. Cela peut sembler simple, mais imaginez que vous deviez extraire du texte de milliers de fichiers HTML (pages Web), ce ne serait pas aussi amusant. En fait, l’extraction de texte des pages Web a de nombreux usages pratiques, pour n’en citer que quelques-uns :
- Télécharger les blogs des pages web
- Téléchargez tous les articles d’actualité d’un site Web spécifique
- Extraire des informations sur les produits, telles que l’SKU, le modèle et la description, de sites de e-commerce comme Amazon et eBay
- Extraire uniquement le texte de la page Web, sans les tableaux, les images ou d’autres formes de données
- Nettoyez un fichier HTML désordonné pour n’inclure que le contenu lisible du fichier
Comment le texte est intégré à un fichier HTML
Quelle que soit la raison pour laquelle vous souhaitez extraire le texte d’un fichier HTML, il est utile d’en savoir un peu plus sur la façon dont les textes ou les différents types de données sont intégrés dans un fichier HTML avant de commencer à travailler.
Le principal élément d’un fichier HTML est un tableau d’éléments dans lequel sont intégrés tous les types de données, y compris le texte. Ces éléments sont organisés d’une certaine manière pour constituer la structure d’une page Web.
Voici un exemple tiré d’un des exercices HTML de W3School :
Vous pouvez voir ce qui est ci-dessus comme un élément. <p> and </p> comme les balises (la première marque une début et la seconde une fin). Text est souvent enveloppé entre les balises telles que <p>, <span> et <h>, etc.
Comprendre la structure d’un fichier HTML serait utile si vous souhaitez uniquement extraire un élément de données particulier du fichier HTML (ou de la page web). et c’est exactement là que Xpath entre en jeu – un langage d’interrogation permettant de sélectionner des éléments dans un document XML/HTML.
Comment extraire des textes du HTML
Il y a deux choses que vous pouvez essayer pour récupérer le texte des fichiers HTML.
Langage de programmation
Pour ces documents HTML simple, les personnes ayant des connaissances de base en codage choisiraient d’écrire un programme pour supprimer toutes les balises HTML et ne conserver que le texte dans les fichiers HTML, en utilisant une expression régulière ou XPath. Il existe plusieurs langages de programmation largement utilisés, tels que C#, Java, Python, JS, PHP, Go et NodeJs, qui sont disponibles pour les programmeurs informatiques.
Certains de ces langages ont leur propre analyseur syntaxique pour le HTML qui est disponible gratuitement. Vous en saurez plus sur ces analyseurs syntaxiques en cliquant ici.
https://en.wikipedia.org/wiki/Comparison_of_HTML_parsers
Tester et déboguer vos codes peut prendre un certain temps, ce qui est à prévoir si vous avez une quelconque expérience du codage.
Outils d’Extraction de Données sur le Web
Il existe de nombreux outils d’extraction Web performants, tels qu’Octoparse, qui vous permettent de récupérer presque tout ce qui se trouve sur la page Web, y compris le texte, les liens, les images, etc. Vous pouvez convertir tout ce que vous obtenez dans un format de données structuré.
Aucun codage requis, c’est donc une bonne option pour ceux qui n’ont aucune expérience du codage. Dans la plupart des cas, vous n’avez pas besoin d’écrire des expressions régulières ou XPath, mais ce sera toujours un plus si vous voulez répondre à des exigences de données plus sophistiquées. Octoparse, étant donné qu’il est conçu pour les non-codeurs, est doté d’une interface conviviale qui vous permet d’interagir facilement avec les pages Web. Il est facile de gérer et d’exporter les données sans IDE.
Exemple d’extraction HTML
Si vous êtes encore un nouveau venu dans un langage de programmation mais que vous souhaitez télécharger des informations à partir de pages Web avec empressement, un outil de scraping Web peut vous être extrêmement utile. L’algorithme d’auto-détection d’Octoparse facilite le scraping de données pour les non-codeurs. Pour la plupart des pages Web, vous pouvez le faire en trois étapes simples.
- Entrez l’URL ciblé
- Lancer l’auto-détection
- Exécutez la tâche d’extraction de données
Je prends cette page comme exemple : https://techcrunch.com/
Supposons que vous souhaitiez récupérer les blogs de Techcrunch (ou de tout autre site Web similaire), il suffit d’entrer l’URL dans Octoparse et de lancer l’autodétection. Vous obtiendrez un scraper qui vous aidera à obtenir les données structurées comme ci-dessous :
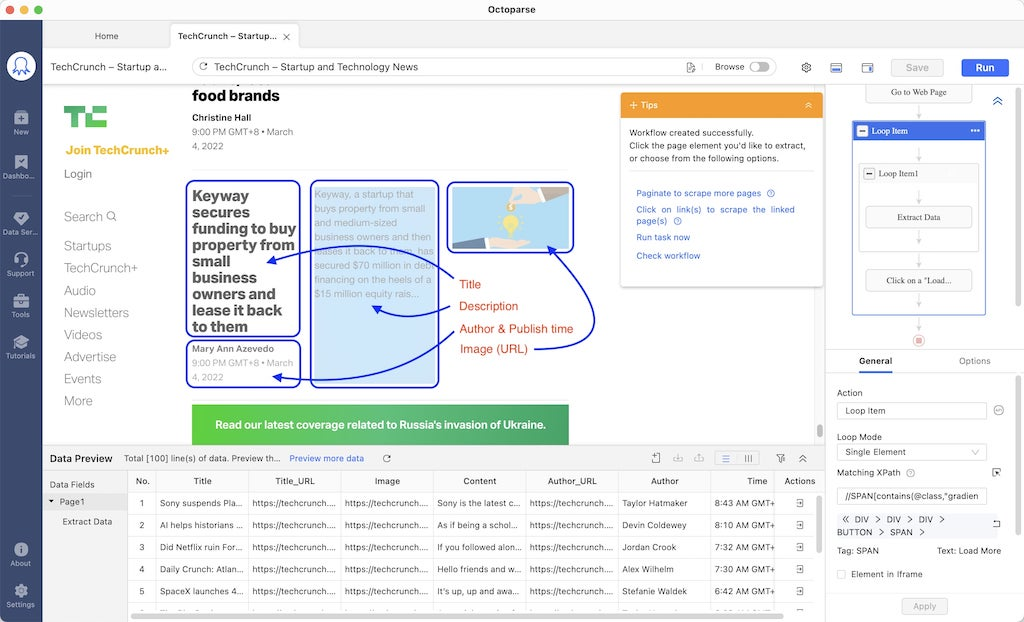
En cliquant sur le bouton “Enregistrer”, vous avez un scraper à votre disposition. Vous pouvez lancer le scraper chaque fois que vous avez besoin des données ou le programmer pour qu’il vous transmette régulièrement des données.
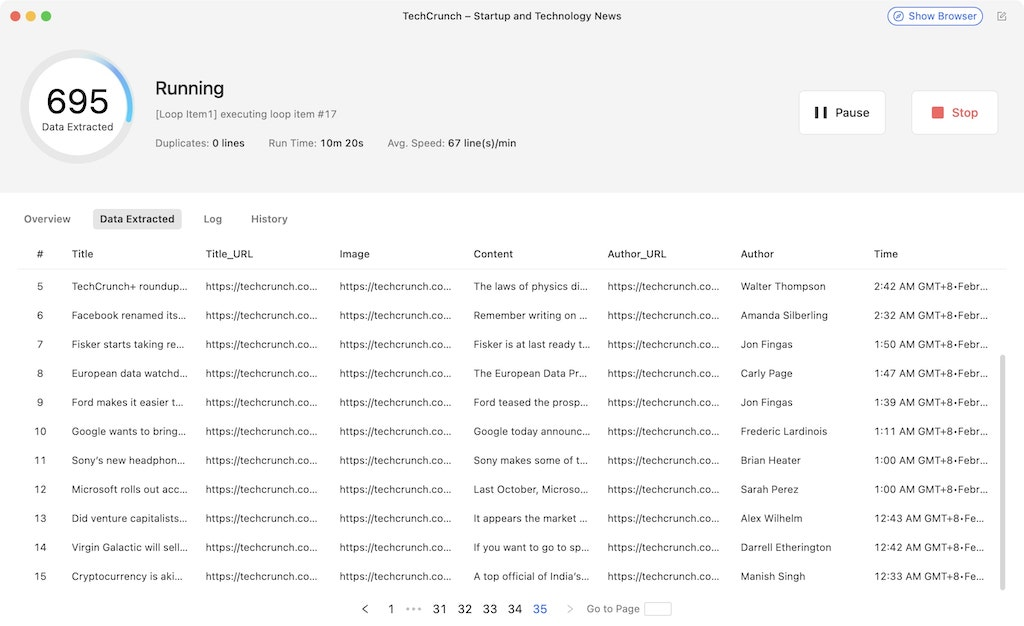
Si vous optez pour des exécutions locales, vous pourrez voir le processus fonctionner en temps réel. Une fois la tâche terminée, vous pouvez télécharger les données dans Excel, CSV ou JSON. Avec l’aide d’Octoparse, l’extraction de données de fichiers HTML peut être aussi simple que cela.
Téléchargez Octoparse dès maintenant et essayez-le vous-même. Suivez ce tutoriel étape par étape pour obtenir les données dont vous avez besoin sur n’importe quel site Web.



