Le 21e siècle est celui d’une explosion d’informations. Dans la fin de protéger les lecteurs d’être avalés par les informations non pertinentes, certains se lancent dans la création d’agrégateur de nouvelles de niche pour faciliter la recherche et la consultation des nouvelles de leur industrie. Cependant, au milieu d’un certain domain, les informations sont toujours d’un nombre volumineux, c’est là où la classification de texte en NLP vient à la rescousse. Par conséquent, un agrégateur d’actualités doit non seulement rassembler les flux d’actualités les plus récents, mais aussi les placer sous la bonne catégorie.
Compte tenu de la masse d’informations qui s’accumulent chaque jour, on a besoin d’une solution automatisée – web scraping pour l’extraction de nouvelles et classification automatique (NLP) pour la catégorisation de nouvelles. Sinon, il est tout simplement impossible pour un être humain de gérer des informations volumineuses.
Cet article va concentrer sur comment obtenir les données pour créer un agrégateur, et surtout sur comment profiter de la classification de texte pour optimiser l’agrégateur.
Agrégateur de nouvelles, c’est quoi
Selon Wikipédia, un agrégateur d’informations est “un logiciel client ou une application Web qui regroupe des syndications de contenu tels que des journaux en ligne, des blogs, des podcasts et des blogs vidéo (vlogs) en un seul endroit pour en faciliter la consultation”.
Le lecteur RSS en est un exemple classique. Les agrégateurs de nouvelles ont évolué depuis 1999 si l’on considère le RSS comme un début. Un agrégateur de nouvelles prend désormais de nouvelles formes comme Google News, Feedly et Flipboard. Des fonctionnalités sophistiquées ont été développées pour offrir au public une meilleure expérience utilisateur.
Les agrégateurs de nouvelles sont assez populaires dans notre jour où l’information explose. Grâce à un agrégateur, vous pouvez facilement consulter toutes les nouvelles de votre centre d’intérêt, ou votre industrie sur une seule plateforme, au lieu de les chercher durement sur Internet. Voilà un petit exemple de l’agrégation de contenu où l’éditeur choisit les bons articles sur le sujet de création de sites Internet et pui les y affiche. L’opération humaine est suffisante pour les petits projets. Mais quand il s’agit d’un grand sujet qui concerne un grand nombre d’articles et de sources, il faut avoir recours à des solutions d’automation. On verra l’automation dans l’extraction de nouvelles avec le web scraping et celle dans la catégorisation de nouvelles avec la classification de texte en NLP.
Comment obtenir les données pour créer un agrégateur
Pour créer un agrégateur de nouvelles, la première question à laquelle il faut répondre consiste à comment extraire efficacement les nouvelles d’actualités de différentes sources. Trios méthodes sont souvent indiqués : API, web scraping, service de données.
Mais dans notre cas qui est la création d’un agrégateur, le service de données ne semble pas être une bonne option. Les actualités évoluent rapidement et sont diffusées à grande échelle. Nous avons besoin d’une solution plus rapide et plus rentable.
API pour accéder aux donnée
API est l’abréviation pour Application Programming Interface qui est un accès offert par le propriétaire du site. Avec l’API connectée, les informations accordées peuvent être acquises directement auprès du client ou de l’application.
Toujours confus ? Essayez cette introduction.
Quand utiliserez-vous l’API pour extraire des informations pour votre site d’agrégation ? Voici une checklist :
☑ Vous êtes un développeur expérimenté, capable de gérer des connexions API et de les maintenir.
☑ La source d’actualités offre un service API au public.
☑ L’API offre les flux d’actualités dont vous avez besoin pour votre site web.
☑ Vous ne recueillez pas de données à partir d’une multitude de sources.
A travers cette liste de contrôle ci-dessus, on peut déjà voir les inconvénients de l’utilisation de l’API.
Toutes les sources ne proposent pas une API et, dans la plupart des cas, une API n’offre que des informations limitées au public. Comme chaque API est proposée par différents fournisseurs, les moyens de s’y connecter diffèrent. Si vous vous approvisionnez en données auprès de 50 publications, vous devrez construire un pipeline de données 50 fois et les maintenir à l’avenir.
C’est trop. Bien sûr, si vous avez une équipe de développement qui est consacrée à la collecte de données, cela peut être une option.
Web scraping pour extraire les données
Contrairement aux API, le web scraping collecte des données à partir du fichier HTML. Puisque vous extrayez les données incluses déjà dans le code source HTML, il n’y a pas de limites pré-définies par les propriétaires. Donc vous pouvez obtenir la plupart des données que vous voyez dans le navigateur grâce au web scraping, qu’il s’agit des métadonnées ou de l’article complet.
Pour être honnête, je ne suis pas un expert sur des sujets comme le web scraping en Python ou le web scraping avec PHP. L’écriture de scripts pour gratter des données web nécessite de solides compétences et des efforts dans la création et la maintenance des robots de scraping.
Ce que je veux partager, c’est une façon sans code. Il s’agit d’utiliser un outil de scraping web no-code comme Octoparse. Ce genre d’outils de web scraping nocode facilite le processus de création d’un scraper et nous libère de nombreux défis auxquels nous risquons de faire face si nous effectuons le web scraping nous-mêmes avec des langages de programmation.
Dans notre cas d’agrégateur de nouvelles, les données doivent être mises à jour fréquemment. Donc il faut choisir un outil qui est équipé des fonctionnalités telles que la planification des tâches pour le scraping automatique des données, l’intégration à la base de données. Octoparse est un outil très puissant capable de répondre à tous vos besoins. Utiliser le plan gratuit pour la première découverte ou demander un essai de 14 jours du plan premium et l’équipe de support d’Octoparse vous accompagnera tout au long du parcours.
Tutoriel étape par étape : Comment extraire les métadonnées et l’article complet des nouvelles dans la fin de créer un agrégateur ?
Classification de texte avec NLP
La classification ou la catégorisation des textes est un sujet important pour les agrégateurs ambitieux. En classant les nouvelles sous différentes catégories, vous faciliterez davantage la lecture. Chaque site qui fait des contenus se préoccupe de classer ses articles, sans parler les agrégateurs qui ont pour but de gérer un grand nombre d’articles. S’il s’agit d’un nombre volumineux d’articles, les classer manuellement devient impossibile, c’est là où on introduit la classification de texte avec NLP pour tout automatiser. La classification de textes consiste à étiqueter chaque texte avec une ou plusieurs classes (catégories) prédéfinies par le biais d’un algorithme d’apprentissage automatique (Machine Learning / Deep Learning).
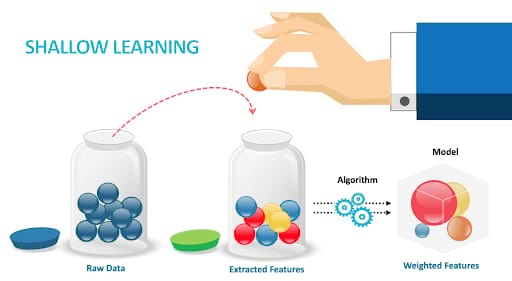
Apprentissage superficiel : du manuel à l’automatisé
Au début, les nouvelles étaient triées manuellement. Les éditeurs parcouraient à l’œil nu une multitude de nouvelles et d’articles, sélectionnaient ceux qui étaient qualifiés et les rangeaient dans les catégories désignées. Le travail manuel est inutilement lent et source d’erreurs. Avec l’évolution de l’apprentissage automatique et du traitement automatique des langues, les éditeurs disposent de solutions plus automatisées pour classer les informations.
Des années 1960 aux années 2010, l’apprentissage superficiel a dominé les modèles de classification de texte, tels que Naive Bayes (NB), Méthode des k plus proches voisins (KNN). Les caractéristiques doivent être définies par les scientifiques des données et, lorsque cela est fait parfaitement, l’algorithme aidera à prédire les catégories d’informations sur la base de ces caractéristiques.
Note : Selon Christopher Bishop, une caractéristique [feature] est connue comme une propriété individuelle mesurable ou une caractéristique d’un phénomène observé.
Apprentissage profond
Depuis les années 2010, les modèles d’apprentissage profond ont prévalu (tels que CNN, GCN, ReNN) et ils sont maintenant plus largement appliqués pour classer du texte dans les applications NLP que les modèles d’apprentissage superficiel.
Pourquoi ?
La principale différence qui distingue les modèles d’apprentissage profond de ceux de l’apprentissage superficiel est que les méthodes d’apprentissage profond sont capables d’apprendre des caractéristiques, en dérivant leurs caractéristiques directement des données, alors que l’apprentissage superficiel s’appuie sur les humains pour les définir.
Les méthodes d’apprentissage profond ne sont pas destinées à surpasser les modèles d’apprentissage superficiel. Vous pouvez choisir une méthode qui s’adapte à vos ensembles de données et cela peut dépendre de la façon dont vous voulez que les textes soient classés.
Le traitement de contenu, est-il légal ?
Il s’agit d’une question sérieuse. Personne ne veut créer un site web au risque d’enfreindre la loi et d’aller en prison. Et il est également complexe d’y répondre. Voici quelques réflexions à partager, et si vous êtes préoccupé par la question de la légalité, consultez votre conseiller juridique lorsque vous aurez décidé de votre modèle commercial.
- Jetez un coup d’œil au RGPD.
RGPD, il s’agit de la loi sur la protection des données mise en œuvre par l’UE. Vous devez être prudent lorsque vous récupérez des données personnelles de résidents de l’UE.
« Une donnée à caractère personnel ou DCP (couramment « données personnelles » ) correspond en droit français à toute information relative à une personne physique identifiée ou qui peut être identifiée, directement ou indirectement, par référence à un numéro d’identification ou à un ou plusieurs éléments qui lui sont propres »
Si vous récupérez des données personnelles de citoyens de l’UE, il vaut mieux vous assurer que vous avez une raison légale de le faire, par exemple, avec un consentement accordé ou un contrat signé. Sinon, vous le faites dans l’intérêt public.
- Vérifiez si vous êtes en conformité avec la loi américaine sur les droits d’auteur [U.S. Copyright Law].
Si vous scrapez des données appartenant à un citoyen ou à une entité des États-Unis, faites attention à l’utilisation équitable de ces données. Quatre aspects sont mentionnés dans la loi:
- Objectif et caractère de l’utilisation, y compris si l’utilisation est commerciale ou à des fins éducatives sans but lucratif.
- Nature de l’œuvre protégée par le droit d’auteur : L’utilisation d’une œuvre plus créative ou imaginative (telle qu’un roman, un film ou une chanson) est moins susceptible de soutenir l’utilisation équitable que l’utilisation d’une œuvre factuelle (telle qu’un article technique ou une nouvelle).
- La quantité et la substantialité de la partie utilisée concernant l’œuvre protégée par le droit d’auteur dans son ensemble.
- L’effet de l’utilisation sur le marché potentiel ou la valeur de l’œuvre protégée par le droit d’auteur.
Certains projets de web scraping se situent dans une zone grise et il n’est pas facile de répondre par oui ou par non à cette question. Il existe de nombreux facteurs liés à la légalité et si vous êtes intéressé, certains cas réels dans l’histoire peuvent vous apporter un éclairage supplémentaire sur cette question.
Conclusion
La création d’une entreprise demande bien sûr beaucoup d’efforts. Mais elle est accessible lorsque l’on dispose de quelques connaissances de base et de moyens pour y parvenir. Pour créer un site web d’agrégateur de nouvelles, vous pouvez commencer avec le web scraping pour l’extraction de données et les techniques NLP pour le traitement des données.
Octoparse répondra toujours à tous vos besoins en matière de données Web. Si vous voulez essayer la magie du web scraping, téléchargez Octoparse ici.