L’essentiel en 30 secondes
Pour extraire les liens d’une page web, vous avez 3 options selon votre profil :
- 🎯 No-code (le plus simple) : Octoparse, gratuit, sans installation complexe
- ⚡ Extension Chrome (instantané) : Link Klipper, idéal pour une extraction rapide ponctuelle
- 🐍 Bibliothèque Python (pour développeurs) : Beautiful Soup, le plus flexible et personnalisable
Découvrez ci-dessous les 14 meilleurs extracteurs de liens testés en 2026, classés par type d’usage et niveau technique.
Quand a-t-on besoin de trouver des liens de site ?
Extraire tous les liens d’une page web est une opération courante pour les analystes SEO, les développeurs et les équipes marketing : audit de maillage interne, campagne de netlinking, veille concurrentielle ou simple archivage. Encore faut-il choisir le bon outil selon son niveau technique et son cas d’usage.
Dans cet article, nous avons testé et comparé 14 extracteurs de liens, des extensions Chrome gratuites aux bibliothèques Python, en passant par des plateformes no-code capables d’aspirer les liens d’un site entier. Pour chaque outil, vous trouverez ses points forts, ses limites et le profil d’utilisateur auquel il correspond.
Comment extraire les liens d’une page web en 3 étapes
Avant de plonger dans la liste détaillée des outils, voici la méthode la plus rapide et accessible (sans coder) pour extraire tous les liens d’une page web. Cette méthode s’applique à n’importe quel site, qu’il s’agisse d’un blog, d’un site e-commerce ou d’un annuaire en ligne.
Étape 1 : Choisir un extracteur adapté à votre niveau
Pour démarrer rapidement, Octoparse est l’outil recommandé : gratuit, sans code, compatible Windows et Mac. Téléchargez-le gratuitement et lancez votre première extraction en quelques minutes. Si vous préférez une solution dans le navigateur, une extension Chrome comme Link Klipper suffit pour une extraction ponctuelle.
Étape 2 : Coller l’URL et sélectionner les liens à extraire
Lancez Octoparse, collez l’URL de la page cible dans la barre de recherche intégrée, puis cliquez sur “Démarrer“. L’outil charge la page automatiquement. Cliquez ensuite sur n’importe quel lien visible : Octoparse détecte intelligemment tous les liens similaires sur la page. Dans le panneau de conseils à droite, sélectionnez “Extraire l’URL du lien” pour récupérer les hyperliens (et non le texte d’ancrage). Cette méthode fonctionne aussi bien pour les liens internes que pour les liens externes, y compris ceux chargés en JavaScript.
Étape 3 : Lancer l’extraction et exporter les résultats
Cliquez sur “Exécuter” pour lancer l’extraction de liens. Vous pouvez exécuter le scraping localement ou dans le cloud selon votre plan. Une fois terminé, exportez vos données au format Excel, CSV, JSON ou directement vers Google Sheets en un clic.
💡 Astuce : pour extraire les liens de plusieurs pages d’un coup (par exemple toutes les pages d’un même domaine) consultez notre guide complet sur l’aspirateur de site web. Pour récupérer également le texte, les prix ou les images en plus des liens, Octoparse propose des modèles préconfigurés.
Vous préférez une autre approche ? Découvrez ci-dessous les 14 meilleurs extracteurs classés par type : extensions Chrome, bibliothèques Python, plateformes professionnelles, pour choisir l’outil qui correspond à votre niveau technique et à votre budget.
14 meilleurs outils pour aspirer les URLs
Outils no-code du scraping de données
Octoparse
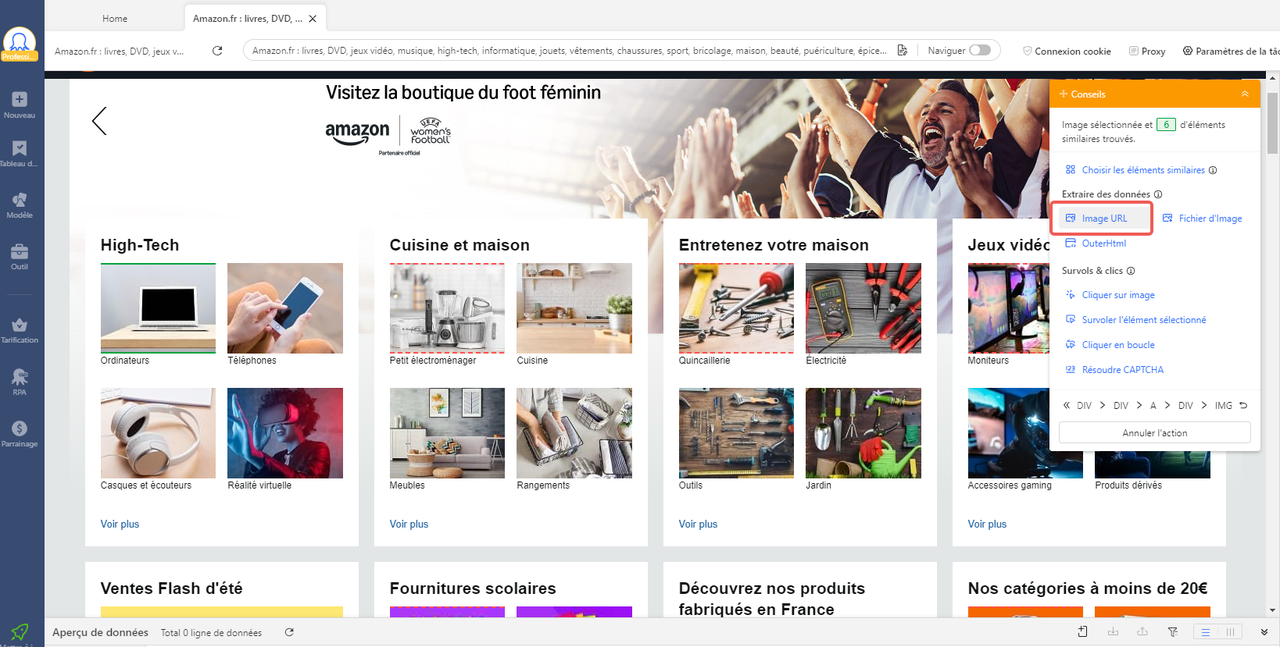
Octoparse est un extracteur de liens no-code, gratuit et complet, conçu pour collecter des URLs en masse sans écrire la moindre ligne de code. Disponible sur Windows et Mac, il combine la simplicité d’une extension Chrome avec la puissance d’un véritable scraper professionnel capable de traiter des sites complexes.
Pour extraire les liens d’une page, il suffit de cliquer sur n’importe quel lien visible, puis de sélectionner “Extraire l’URL du lien” dans le panneau de conseils. Octoparse détecte automatiquement tous les liens similaires et les extrait en quelques secondes.
Au-delà des liens classiques, Octoparse peut également récupérer :
- les URL d’images pour télécharger des visuels en masse
- les liens internes et externes d’un site complet
- les liens cachés chargés en JavaScript, impossible à récupérer avec une simple extension Chrome
- du contenu associé (texte, tableaux, prix, avis) en une seule passe d’extraction
Pour aller plus loin dans l’exploitation de vos données extraites, vous pouvez également extraire les données complètes d’un site web : texte, prix, avis et images grâce aux modèles préconfigurés d’Octoparse, notamment pour Amazon, Google Maps et LinkedIn.
Points forts : version gratuite suffisante pour démarrer, exécution dans le cloud, exports Excel/CSV/JSON/Google Sheets, modèles préconfigurés pour les principaux sites.
Points d’attention : la version gratuite limite le nombre de tâches mensuelles ; pour un scraping intensif, un plan payant est nécessaire.
👉 Idéal pour : les analystes SEO, les équipes commerciales en génération de leads, les e-commerçants en veille concurrentielle, et tous ceux qui veulent extraire des liens en masse sans coder.

Extraire tous les liens d’une page web et exporter vers Excel, CSV, Google Sheets ou base de données.
Détecter et récupérer automatiquement les URLs — liens internes, externes et liens cachés en JavaScript.
Scraper les liens des sites populaires en quelques clics avec les modèles pré-construits.
Ne jamais se trouver bloqué grâce aux proxies IP rotatifs et à l’API avancée.
Planifier l’extraction de liens dans le cloud, sans supervision.
WebHarvy
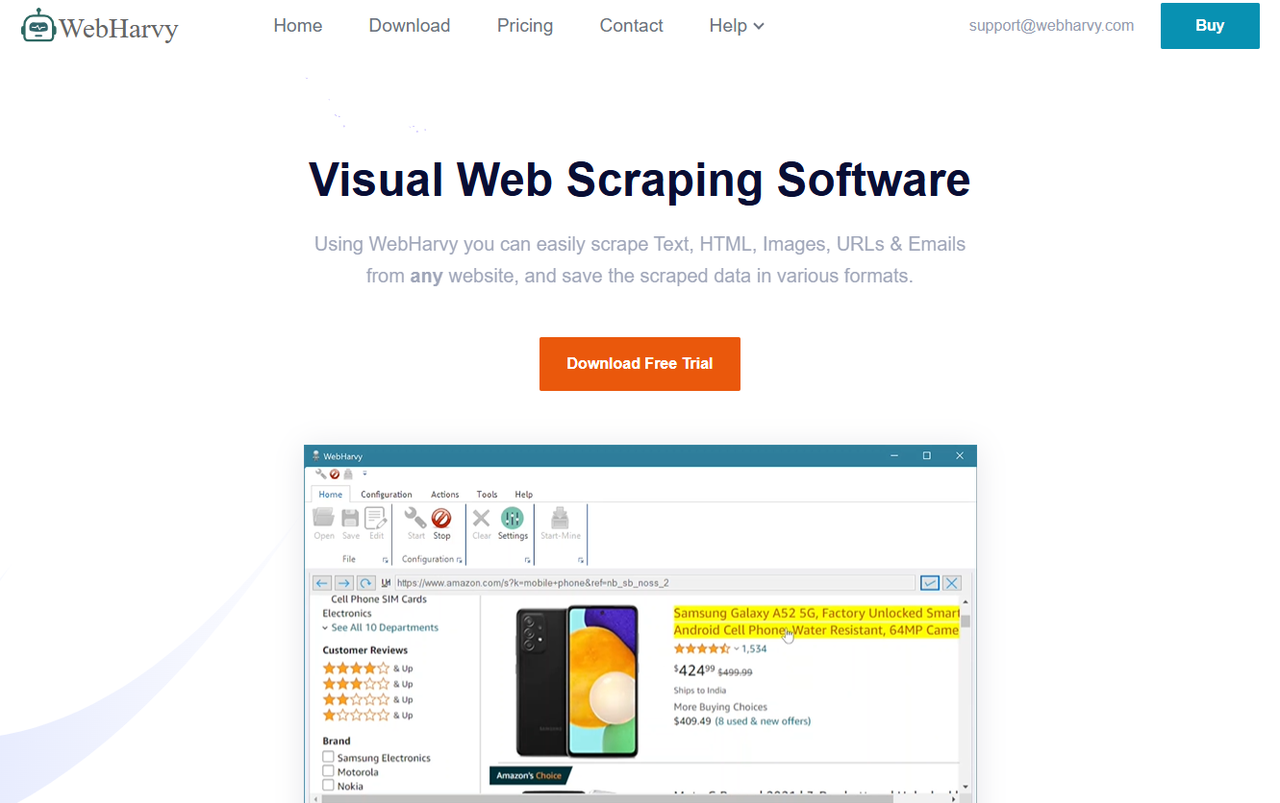
WebHarvy est un logiciel de scraping web par pointer-cliquer qui permet d’extraire des données, y compris des URLs, sans écrire de code. Pour récupérer des liens, vous pouvez utiliser son expression régulière intégrée afin d’identifier les hyperliens directement dans le code HTML sans avoir à en écrire une vous-même.
L’outil gère la pagination automatique, le contenu chargé en JavaScript, et exporte vers CSV, Excel ou XML. WebHarvy fonctionne uniquement sur Windows et se vend sous forme de licence à usage unique (à partir de 129 $), ce qui convient aux utilisateurs qui préfèrent éviter un abonnement mensuel.
Points forts : paiement unique, pas d’abonnement, interface visuelle intuitive.
Points d’attention : Windows uniquement, pas de version cloud, support limité comparé aux plateformes SaaS.
👉 Idéal pour : les utilisateurs Windows qui veulent un outil installé en local avec un paiement unique.
Content Grabber
Content Grabber est un logiciel d’extraction de données à grande échelle. Il permet d’aspirer un site entier ou des pages spécifiques de façon automatisée, ce qui est utile pour collecter rapidement de grandes quantités de liens structurés. Son interface de scripting en C# ou VB.NET offre une personnalisation poussée de chaque tâche d’extraction.
C’est l’un des outils les plus puissants pour les projets complexes, mais son tarif, plusieurs centaines d’euros par licence, le réserve aux entreprises avec des besoins récurrents et un budget conséquent.
Points forts : extraction à très grande échelle, personnalisation avancée via scripting, gestion de volumes importants.
Points d’attention : courbe d’apprentissage élevée, prix prohibitif pour les petites structures, pas de version gratuite.
👉 Idéal pour : les grandes entreprises et agences qui ont besoin d’un scraping automatisé, planifié et à très grande échelle.
Extensions Chrome pour aspirer des liens
Link Grabber
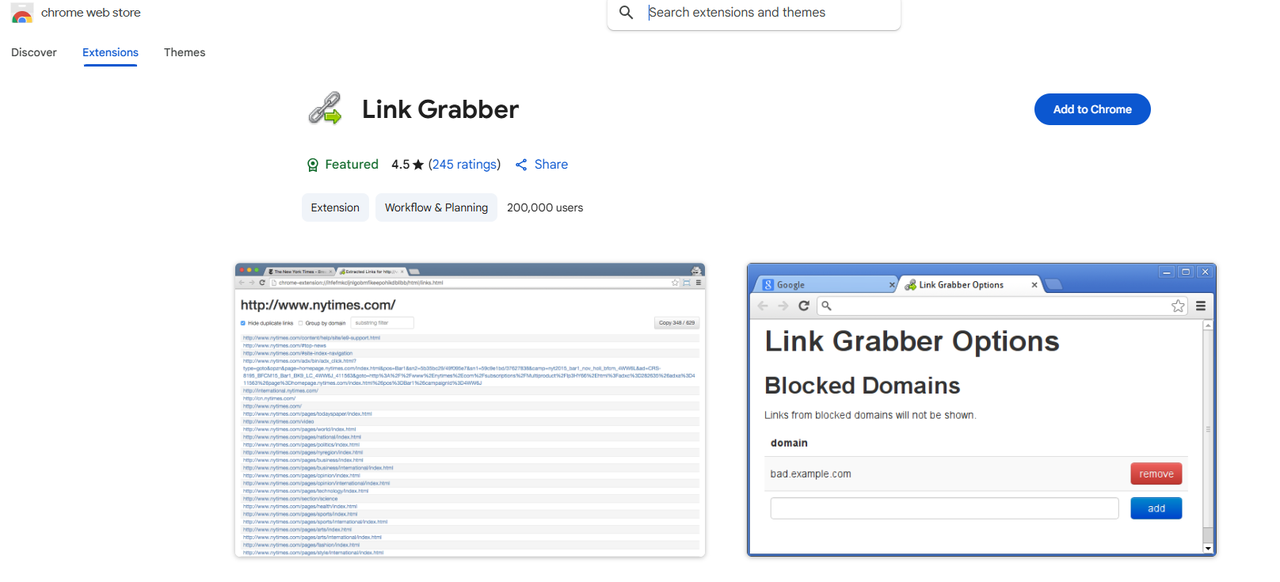
Link Grabber est une extension Chrome spécialisée dans l’extraction de liens hypertextes depuis les pages HTML. Une fois installée depuis le Chrome Web Store, un clic sur son icône suffit pour récupérer instantanément tous les liens de la page active.
L’extension permet de filtrer les liens par correspondance de chaîne de caractères et de les regrouper par domaine, ce qui facilite le nettoyage des données extraites. Entièrement gratuite, sans inscription requise. Sa limite : Link Grabber ne récupère que des liens, pas d’autres types de données.
Points forts : gratuit, installation en un clic, filtrage par domaine.
Points d’attention : fonctionne uniquement sur la page active, pas de pagination, pas d’export structuré.
👉 Idéal pour : une extraction ponctuelle et rapide de liens sur une seule page, sans besoin de données complémentaires.
Link Klipper

Link Klipper est l’un des extracteurs de liens les plus utilisés du Chrome Web Store, avec plus de 200 000 utilisateurs actifs et une note moyenne supérieure à 4,5/5. Il permet d’extraire tous les liens d’une page et de les exporter en quelques clics.
Son atout principal : la sélection manuelle d’une zone précise de la page (un menu, une liste de produits, un sitemap, un annuaire), plutôt que d’extraire tous les liens indistinctement. Cela permet de cibler exactement les liens utiles et d’éviter le bruit (liens de footer, mentions légales, etc.).
Points forts : extraction ciblée par zone, très populaire, gratuit.
Points d’attention : export uniquement en CSV, fonctionne page par page uniquement.
👉 Idéal pour : les utilisateurs qui font fréquemment de l’extraction ciblée sur des zones spécifiques de pages web.
Outils basés sur la programmation
Beautiful Soup (Python)
Beautiful Soup est une bibliothèque Python qui permet d’extraire des données depuis des fichiers HTML et XML. Elle gère correctement le HTML mal formaté et propose une API intuitive pour naviguer dans la structure d’un document et en récupérer tous les liens.
Installation rapide : pip install beautifulsoup4 requests
Voici un exemple de code pour extraire les liens d’une page :
Entièrement open source, Beautiful Soup bénéficie d’une communauté Python active depuis plus de 15 ans. C’est souvent le premier choix pour des projets de scraping de petite à moyenne envergure, jusqu’à quelques milliers de pages. Sa limite principale : elle ne gère pas le JavaScript dynamique nativement.
Points forts : gratuit, open source, très bien documenté, flexible.
Points d’attention : nécessite des connaissances en Python, ne rend pas le JavaScript dynamique.
👉 Idéal pour : les développeurs Python débutants ou intermédiaires qui scrapent principalement des pages HTML statiques.
Scrapy (Python)
Scrapy est un framework Python d’exploration et de récupération de données web, conçu pour le scraping à grande échelle. Il prend en charge le crawling distribué, la gestion de la concurrence, des cookies, des limites de débit, et propose des pipelines d’export vers CSV, JSON ou base de données.
Installation rapide : pip install scrapy
Exemple de code pour extraire les liens avec Scrapy :
Contrairement à Beautiful Soup, Scrapy fonctionne en mode asynchrone et peut traiter plusieurs pages en parallèle, atteignant des débits de plusieurs milliers de pages par minute. La courbe d’apprentissage est plus raide, mais les performances sont incomparables sur des projets industriels.
Points forts : performances élevées, crawling asynchrone, architecture modulaire.
Points d’attention : courbe d’apprentissage élevée, ne gère pas nativement le JavaScript dynamique.
👉 Idéal pour : les développeurs Python expérimentés qui mènent des projets de scraping à grande échelle, des millions de pages.
Selenium (multi-langues)
Selenium est à l’origine un outil d’automatisation web pour tester des applications, disponible en Python, Java, JavaScript, C# et Ruby. Il peut aussi être utilisé pour extraire des liens depuis des sites lourdement chargés en JavaScript (single-page applications, contenu dynamique, infinite scroll), là où Beautiful Soup et Scrapy atteignent leurs limites.
Installation rapide (Python) : pip install selenium webdriver-manager
Exemple de code pour extraire les liens avec Selenium :
Selenium simule un vrai navigateur, ce qui facilite le débogage et la gestion des pages nécessitant une connexion ou des interactions complexes. En contrepartie, il est nettement plus lent que Beautiful Soup ou Scrapy et consomme davantage de ressources.
Points forts : gère le JavaScript dynamique, simulation de navigateur réel, multi-langages.
Points d’attention : lent pour les extractions à grande échelle, consommation élevée en RAM et CPU.
👉 Idéal pour : les développeurs qui doivent extraire des liens depuis des sites complexes avec JavaScript dynamique ou login obligatoire.
Les plateformes pour l’application variée
Bright Data

Bright Data est l’une des plateformes leaders de collecte de données web pour les entreprises B2B. Elle met à disposition plusieurs outils : Web Scraper IDE, Datasets, SERP API, Web Unlocker, et un réseau de plus de 72 millions d’IP résidentielles pour contourner les blocages géographiques.
Son URL Scraper permet de collecter des liens depuis des sites e-commerce, des médias sociaux, des portails immobiliers et d’autres sources à grande échelle. La plateforme garantit une conformité RGPD et CCPA stricte.
Points forts : infrastructure à grande échelle, conformité RGPD/CCPA, réseau de proxies résidentiels massif.
Points d’attention : tarifs élevés (à partir de 500 $/mois pour un usage sérieux), complexité de prise en main, réservé aux grandes structures.
👉 Idéal pour : les grandes entreprises avec des besoins de scraping massif et des contraintes légales strictes.
Apify
Apify est une plateforme cloud de scraping orientée développeurs. Elle propose un catalogue d’Actors, des modules préconfigurés pour certains sites populaires, ainsi qu’un SDK Node.js et Python pour construire des scrapers sur mesure.
La prise en main demande une familiarité avec le code : manipulation de scripts JavaScript ou Python, configuration de chaînes d’extraction, compréhension du modèle de crédits à l’usage. La qualité des Actors varie selon les développeurs tiers qui les publient.
Points forts : marketplace d’Actors, SDK flexible, infrastructure cloud gérée.
Points d’attention : tarification à l’usage difficile à anticiper, certains Actors facturés en supplément, nécessite un développeur en interne.
👉 Idéal pour : les équipes techniques avec un développeur disponible, qui ont besoin d’un Actor spécifique déjà disponible sur la marketplace.
Netpeak Spider
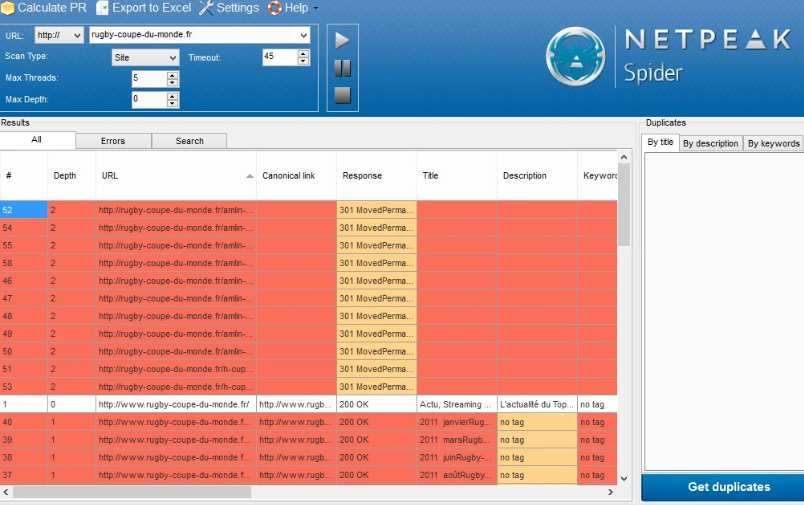
Netpeak Spider est un crawler SEO de bureau conçu spécifiquement pour les audits techniques et l’analyse de structure de liens. Il détecte les liens cassés, analyse les redirections, identifie les pages orphelines et calcule le PageRank interne. Il fournit également des données précieuses pour le netlinking : liens internes et externes, anchor text, attributs nofollow/dofollow, profondeur de chaque page.
Compatible Windows uniquement, il analyse jusqu’à 200 paramètres SEO par page. La version d’essai est limitée à quelques centaines d’URL par crawl, les plans payants démarrent à environ 19 $/mois.
Points forts : spécialisé SEO, analyse complète des liens internes/externes, détection des liens cassés.
Points d’attention : Windows uniquement, pas adapté à l’extraction de données en dehors du contexte SEO.
👉 Idéal pour : les consultants SEO et les équipes qui veulent auditer la structure de liens d’un site web.
ParseHub
ParseHub est une plateforme de scraping avec interface graphique par pointer-cliquer, capable d’extraire des liens et du contenu depuis des sites complexes chargés en JavaScript. Ses algorithmes de détection automatique identifient les patterns de données sur une page, ce qui réduit le temps de configuration. Il gère la pagination automatique, le scraping conditionnel et l’extraction depuis des fichiers PDF.
Disponible sur Windows, Mac et Linux. La version gratuite est limitée à 200 pages par crawl, les plans payants démarrent à environ 189 $/mois. Exports vers CSV, Excel, JSON ou via API.
Points forts : interface visuelle intuitive, gestion du JavaScript dynamique, multi-plateformes.
Points d’attention : prix élevé pour les plans payants, version gratuite très limitée.
👉 Idéal pour : les utilisateurs non techniques qui doivent scraper des sites complexes avec beaucoup de JavaScript.
HTTrack
HTTrack est un logiciel open source gratuit qui télécharge une copie complète d’un site web pour consultation hors ligne. Il reconstruit la structure relative des liens : tous les liens internes du site copié pointent vers les fichiers locaux, ce qui rend la version offline parfaitement navigable. Référence depuis plus de 25 ans pour cette tâche, avec une communauté active et une documentation abondante.
Sa limite principale : HTTrack ne gère pas les sites fortement chargés en JavaScript. Disponible sur Windows, Linux et BSD.
Pour comparer HTTrack à d’autres outils similaires, notre guide sur les aspirateurs de site web fait le point sur les meilleures options.
Points forts : entièrement gratuit, open source, reconstruit fidèlement la structure des liens.
Points d’attention : ne gère pas le JavaScript dynamique, pas d’export structuré des données.
👉 Idéal pour : la copie hors ligne d’un site web complet, particulièrement pour les sites en HTML statique.
GNU Wget
GNU Wget est un utilitaire en ligne de commande gratuit et open source pour télécharger du contenu depuis Internet. Préinstallé sur la plupart des systèmes Linux et macOS, il permet d’aspirer un site entier ou une liste d’URLs en gérant la reprise des téléchargements en cas d’interruption.
Exemple pour télécharger un site en mode récursif :
wget –recursive –no-clobber –page-requisites –html-extension –convert-links –domains exemple.com –no-parent https://www.exemple.com
Wget gère les protocoles HTTP, HTTPS et FTP, les cookies, l’authentification et les limites de bande passante. Léger et scriptable, il s’intègre parfaitement dans des pipelines de production.
Points forts : gratuit, léger, scriptable, gestion fine via ligne de commande.
Points d’attention : pas d’interface graphique, pas de gestion du JavaScript dynamique, réservé aux utilisateurs à l’aise avec le terminal.
👉 Idéal pour : les administrateurs système et développeurs qui automatisent des téléchargements dans des scripts shell.
Comparatif des 14 extracteurs de liens : tableau récapitulatif
Pour choisir l’extracteur de liens adapté à votre profil, voici une synthèse comparative des 14 outils présentés dans cet article. Deux critères principaux structurent la lecture : votre niveau technique (sans code ou avec code) et votre budget (gratuit, licence unique ou abonnement mensuel). Pour chaque outil, vous trouverez également le cas d’usage principal qui justifie son choix.
| Outil | Type | Prix | Sans code | Idéal pour |
|---|---|---|---|---|
| 🏆 Octoparse | Desktop + Cloud | Gratuit + plans payants | ✅ Oui | Tous profils, extraction massive |
| WebHarvy | Desktop (Windows) | Licence unique (~129 $) | ✅ Oui | Utilisateurs Windows, paiement unique |
| Content Grabber | Desktop pro | Licence pro (centaines €) | Partiellement | Grandes entreprises, projets complexes |
| Link Grabber | Extension Chrome | Gratuit | ✅ Oui | Extraction simple et ponctuelle |
| Link Klipper | Extension Chrome | Gratuit | ✅ Oui | Extraction ciblée par zone |
| Beautiful Soup | Bibliothèque Python | Gratuit (open source) | ❌ Non | Développeurs Python débutants |
| Scrapy | Framework Python | Gratuit (open source) | ❌ Non | Scraping à grande échelle |
| Selenium | Multi-langues | Gratuit (open source) | ❌ Non | Sites JavaScript dynamiques |
| Bright Data | Plateforme cloud B2B | À partir de ~500 $/mois | Partiellement | Très grandes entreprises, RGPD strict |
| Apify | Plateforme cloud | À partir de 49 $/mois | Partiellement | Équipes techniques avec développeur |
| Netpeak Spider | Crawler SEO desktop | À partir de ~19 $/mois | ✅ Oui | Audits SEO et analyse de structure |
| ParseHub | Cloud + Desktop | À partir de ~189 $/mois | ✅ Oui | Sites complexes en JavaScript |
| HTTrack | Logiciel open source | Gratuit | ✅ Oui | Copie hors ligne d’un site complet |
| GNU Wget | Utilitaire en ligne de commande | Gratuit (open source) | ❌ Non | Automation via terminal et scripts |
Comment lire ce tableau
Sans code = ✅ Oui : vous pouvez utiliser l’outil immédiatement, sans aucune connaissance en programmation.
Sans code = Partiellement : l’outil propose une interface visuelle pour les usages basiques, mais certaines fonctionnalités avancées nécessitent de coder ou de maîtriser des concepts techniques.
Sans code = ❌ Non : connaissances en programmation requises : Python, JavaScript, ligne de commande ou équivalent
Si vous hésitez encore, la section suivante vous guide selon votre profil et votre cas d’usage concret.
Quel extracteur choisir si vous hésitez ?
Si vous cherchez un point de départ qui combine simplicité (sans code), prix accessible (version gratuite pour démarrer), polyvalence (liens, images, contenus) et capacité à monter en charge, Octoparse s’impose comme le point de départ le plus solide. Vous pouvez tester la version gratuite en quelques minutes et passer à un plan payant uniquement si vos besoins le justifient.
Pour des besoins plus spécifiques (scraping massif B2B, audit SEO technique, copie hors ligne), reportez-vous au tableau ci-dessus pour identifier l’outil le plus adapté.
Quel extracteur de liens choisir selon votre besoin ?
Le tableau comparatif vous donne une vue d’ensemble, mais le choix concret dépend de votre profil et de votre cas d’usage. Voici une grille de décision rapide pour vous orienter en quelques secondes.
Vous êtes débutant et n’avez jamais fait de scraping
Privilégiez un outil sans code avec une courbe d’apprentissage minimale :
- Pour démarrer en 5 minutes : Octoparse, avec son interface visuelle, modèles préconfigurés pour Amazon, Google Maps, LinkedIn, version gratuite pour vos premiers tests. Créez votre compte gratuitement et commencez sans carte bancaire.
- Pour une extraction ponctuelle sur une seule page : Link Klipper, extension Chrome, aucune installation lourde, résultat immédiat
Vous êtes développeur et préférez coder
Choisissez selon la taille de votre projet :
- Petits projets (moins de 10 000 pages) : Beautiful Soup, simple, bien documenté, parfait pour débuter en scraping Python
- Projets industriels (millions de pages) : Scrapy, framework asynchrone conçu pour la production
- Sites lourdement chargés en JavaScript : Selenium, avec simulation de navigateur réel
Vous avez des besoins SEO (audit, netlinking, veille)
- Audit technique d’un site : Netpeak Spider, spécialisé SEO, identifie les liens cassés, les redirections et les pages orphelines
- Extraction de liens et données concurrentielles (prix, avis, contenu) : Octoparse, avec des modèles préconfigurés pour les principaux sites e-commerce. Pour une veille complète sur Google Maps, consultez nos modèles Google Maps
Vous voulez télécharger une copie hors ligne d’un site
- Site classique en HTML : HTTrack, référence open source pour la copie offline depuis 25 ans
- Automation via scripts : GNU Wget, léger, en ligne de commande
Vous êtes une grande entreprise avec des contraintes RGPD strictes
- Scraping massif (millions d’URLs/mois) : Bright Data, avec un réseau de 72 millions d’IP résidentielles, conformité RGPD/CCPA
- Alternative avec budget maîtrisé : Octoparse en plan Premium ou Enterprise, tarification prévisible, support dédié. Consultez les tarifs sur notre page dédiée.
Vous gérez des sites complexes avec beaucoup de JavaScript
- Sans coder : ParseHub, détection automatique des patterns, interface graphique intuitive
- En codant : Selenium, pour un contrôle total via simulation de navigateur, compatible Python, Java et JavaScript
Pour la majorité des cas d’usage
Si vous voulez un outil polyvalent qui couvre 80 % des besoins sans apprendre plusieurs solutions différentes, Octoparse reste l’option la plus équilibrée : sans code, gratuit pour démarrer, capable de monter en charge, compatible avec tous les types de sites.
Pour extraire les données complètes d’un site web au-delà des seuls liens (texte, prix, images), Octoparse propose également des modèles dédiés, notamment pour les recherches sur les réseaux sociaux.
Techniques pour optimiser le scraping de données
Pour maximiser l’efficacité de l’extraction de liens, quelques bonnes pratiques s’imposent quelle que soit la solution retenue.
Commencez par définir précisément le périmètre : liens internes uniquement, liens externes, ou les deux ? Liens d’une seule page ou d’un domaine entier ? Cette clarté en amont évite de traiter des volumes inutiles.
Utilisez les filtres disponibles dans votre outil pour exclure les liens non pertinents : liens de footer, mentions légales, ancres de navigation. Sur les sites volumineux, privilégiez un crawling progressif par sections plutôt qu’une extraction globale en une seule passe.
Pour les sites chargés en JavaScript, vérifiez que votre outil rend bien le DOM dynamique avant d’extraire : une extension Chrome basique retournera des résultats incomplets sur ce type de pages. Octoparse, Selenium et ParseHub sont les options adaptées dans ce cas.
Enfin, espacez vos requêtes pour ne pas surcharger le serveur cible, et consultez le fichier robots.txt du site avant toute extraction à grande échelle.
FAQ : Extracteur de liens
- Comment extraire tous les liens d’une page web ?
La méthode la plus simple est d’utiliser un outil sans code comme Octoparse : collez l’URL de la page cible, cliquez sur n’importe quel lien visible, sélectionnez “Extraire l’URL du lien” dans le panneau de conseils, puis exportez les résultats en CSV ou Excel. Cette opération prend moins de 5 minutes pour une page standard. Pour les développeurs, des bibliothèques Python comme Beautiful Soup permettent de récupérer tous les liens en quelques lignes de code.
- Quel est le meilleur extracteur de liens gratuit en 2026 ?
Pour une utilisation gratuite et sans code, Octoparse est l’option la plus complète : sa version gratuite permet d’extraire des liens en masse, avec des modèles préconfigurés et un support multi-plateformes (Windows + Mac). Pour une extraction ponctuelle dans le navigateur, Link Klipper et Link Grabber (extensions Chrome) sont également gratuits. Côté code, Beautiful Soup et Scrapy sont des bibliothèques Python entièrement open source.
- Comment extraire les liens d’un site web sans coder ?
Trois solutions principales existent sans aucune connaissance en programmation : (1) un logiciel sans code comme Octoparse ou WebHarvy, qui propose une interface visuelle par pointer-cliquer ; (2) une extension Chrome comme Link Klipper, idéale pour une extraction ponctuelle ; (3) une plateforme cloud avec interface graphique comme ParseHub. Octoparse reste le plus polyvalent des trois pour les utilisateurs débutants, car il combine simplicité et capacité à gérer des sites complexes.
- Peut-on extraire les liens de plusieurs pages d’un coup ?
Oui, mais cela nécessite un outil capable de gérer la pagination automatique ou le crawling récursif. Les extensions Chrome basiques (Link Grabber, Link Klipper) ne fonctionnent que sur la page active. En revanche, Octoparse, Scrapy, HTTrack ou GNU Wget peuvent parcourir un site entier et extraire les liens de toutes les pages en une seule passe.
- Quelle différence entre liens internes et liens externes ?
Les liens internes pointent vers d’autres pages du même domaine (par exemple, un lien d’un article de blog vers une page produit du même site). Les liens externes pointent vers des pages d’autres domaines. La distinction est importante en SEO : les liens internes structurent l’architecture d’un site et distribuent le PageRank, tandis que les liens externes (entrants ou sortants) influencent l’autorité globale du site. La plupart des extracteurs de liens permettent de filtrer par type (internes ou externes), notamment Netpeak Spider pour les audits SEO et Octoparse pour les besoins polyvalents.
- Est-il légal d’extraire les liens d’un site web ?
En général, extraire des liens publiquement accessibles est légal dans la plupart des pays, y compris en France et dans l’Union européenne. Cependant, plusieurs règles doivent être respectées : (1) consulter le fichier robots.txt du site cible et respecter ses directives, (2) lire les conditions d’utilisation (CGU) du site, (3) ne pas surcharger le serveur (espacer les requêtes), (4) ne pas extraire de données personnelles sans base légale au sens du RGPD. Pour un usage commercial intensif, il est recommandé de consulter un juriste spécialisé.
- Comment extraire tous les liens d’un site web entier, pas seulement d’une page ?
Les extensions Chrome comme Link Grabber ou Link Klipper ne fonctionnent que sur la page active. Pour extraire les liens de toutes les pages d’un domaine en une seule opération, il vous faut un outil capable de gérer la pagination automatique ou le crawling récursif. Octoparse, Scrapy, HTTrack et GNU Wget permettent de parcourir un site entier et d’en extraire tous les liens en une seule passe.
- Peut-on extraire des liens depuis un site chargé en JavaScript ?
Oui, mais tous les outils ne le gèrent pas. Les extensions Chrome basiques et HTTrack ne rendent pas le DOM dynamique : elles retourneront des résultats incomplets sur les sites en JavaScript. Les outils adaptés sont Octoparse (no-code, détecte les liens JavaScript automatiquement), Selenium (simulation de navigateur réel) et ParseHub (détection automatique des patterns dynamiques). Si vous utilisez Python, Beautiful Soup seul ne suffit pas : associez-le à Selenium ou Playwright pour les pages dynamiques.
En conclusion
L’extraction de liens est un levier essentiel pour de nombreuses activités : analyse SEO, génération de leads B2B, veille concurrentielle, audit technique, ou simple archivage. Avec les 14 outils présentés dans cet article, du sans-code grand public aux frameworks Python avancés, vous disposez désormais d’une vision complète des solutions disponibles en 2026.
Pour la majorité des utilisateurs, Octoparse est le point de départ le plus efficace : il vous permet d’extraire des liens en quelques clics, sans installation complexe ni connaissances techniques, et reste suffisant pour 80 % des besoins courants. Pour les cas plus spécifiques (scraping à très grande échelle, audit SEO spécialisé, copie hors ligne), reportez-vous au comparatif et au guide de décision plus haut dans l’article.
Un compte gratuit suffit pour démarrer. Créez le vôtre et extrayez vos premiers liens en moins de 5 minutes, sans carte bancaire.



