Les CAPTCHA sont l’une des techniques anti-scraping les plus utilisées par les propriétaires de sites Web. Résoudre les CAPTCHA est l’un des principaux défis auxquels sont confrontés les professionnels de web scraping. Lisez cet article pour comprendre les différents genres de CAPTCHAs et verrez comment résoudre les CAPTCHAs lors du web scraping pour que l’extraction de données va comme sur des roulettes. En outre, je voudrais vous recommander un outil no-code de web scraping qui propose un service de résolution de captcha intégré, facilitant le web scraping des non-codeurs.
Qu’est-ce que CAPTCHA ?
CAPTCHA est un acronyme pour “Completely Automated Public Turing test to tell Computers and Humans Apart”. Il s’agit d’un test de sécurité utilisé pour vérifier si l’utilisateur est un humain ou un programme informatique (bot). Les CAPTCHA sont généralement présentés sous forme de codes ou de puzzles qui doivent être résolus avant qu’un utilisateur puisse accéder à un site Web ou effectuer une action en ligne.
Il y a plusieurs sortes de CAPTCHA. reCaptcha est la plus populaire. Elle vient de Google et peut être facilement intégrée dans un site Web. NuCaptcha, hCaptcha sont d’autres CAPTCHA avancées.
Types de CAPTCHAs les plus courants
1. Captcha normal
C’est le CAPTCHA le plus largement utilisé. Une image déformée contient du texte mais est lisible par les humains. Pour résoudre le CAPTCHA normal, il faut entrer le texte déformé dans la zone de texte.
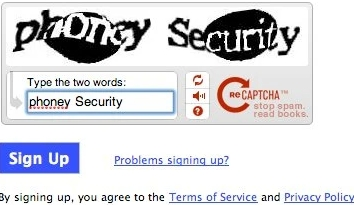
2. Captcha textuel
TextCaptcha n’est pas très populaire, mais il est idéal pour les utilisateurs malvoyants. Ce n’est pas basé sur une image, mais purement du texte. Un exemple CURL de TextCaptcha :
$ curl http://api.textcaptcha.com/myemail@example.com.json
{ “q” : “Si demain est samedi, quel jour sommes-nous aujourd’hui ?”
“a”:[“f6f7fec07f372b7bd5eb196bbca0f3f4”,
“dfc47c8ef18b4689b982979d05cf4cc6”] }
CAPTCHA : Si demain est samedi, quel jour est aujourd’hui ?
SOLUTION : Vendredi.
3. Captcha clé
KeyCaptcha est un autre type de service d’intégration de CAPTCHA où vous devez résoudre une énigme.

4. Click Captcha
Les CAPTCHAs d’image qui relèvent des puzzles basés sur la classification sont des Click CAPTCHAs. reCaptcha, ASIRRA, Ghost Captcha de Snapchat sont des exemples populaires de CAPTCHAs de clic basés sur la classification.

5. Rotate Captcha
Ce sont des énigmes CAPTCHA basées sur l’orientation de l’image. Dans les CAPTCHA à rotation, vous devez cliquer une ou plusieurs fois pour faire pivoter une image afin qu’elle remplisse les conditions de vérification. La condition de vérification la plus populaire est d’obtenir un objet dans le “right way up”. FunCaptcha est l’un des fournisseurs d’intégration “rotate CAPTCHA”, mais il semble cassé. RVerify.js est une bibliothèque javascript open-source pour vérifier l’orientation des images.
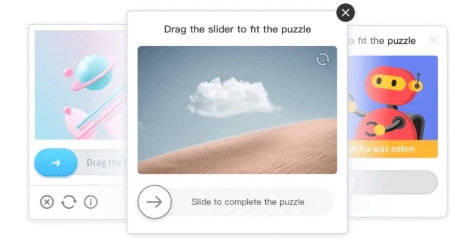
6. GeeTest CAPTCHA
Les CAPTCHAs de GeeTest sont intéressants, ici vous devez déplacer une pièce du puzzle, souvent en faisant glisser un curseur, ou vous devez sélectionner certaines images dans un ordre particulier.
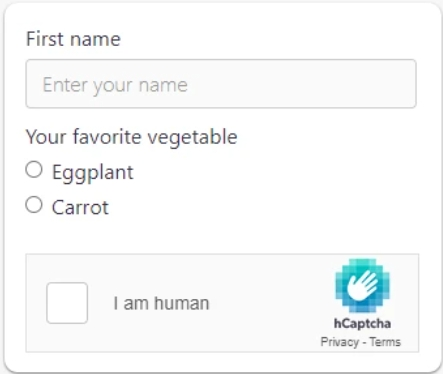
7. hCaptcha
hCaptcha est très similaire à reCaptcha. La seule différence est que lorsque nous utilisons hCaptcha, plusieurs entreprises peuvent tirer parti de l’étiquetage des données que les UTILISATEURS effectuent sur les sites Web lorsqu’ils cliquent sur un site. Avec reCaptcha, seulement Google bénéficie de l’étiquetage des données par les utilisateurs.
8. Capy Puzzle
Similaire à keyCaptcha, Capy Puzzle est un service CAPTCHA basé sur des puzzles. CAPY.ME est un service permettant d’intégrer des puzzles de copie dans des sites Web.

Comment résoudre ou contourner les reCAPTCHAs lors du scraping ?
Que vous utilisez un outil de web scraping no-code de type pointer-cliquer, ou que vous faites le web scraping avec des codes de Python, Java, or Javascript, il est totalement possible de résoudre ou contourner tous genres de CAPTCHAs.
Il y a deux approches populaires pour résoudre les CAPTCHAs :
Des services de résolution de CAPTCHAs
Presque tous les services de résolution de CAPTCHA sur le marché partagent la même approche :
1 – L’utilisateur s’inscrit sur leur site Web et obtient un token et des informations d’identification après avoir payé le montant, ou tout cela peut être gratuit si un essai est disponible.
2 – Implémenter leur API/plugin en utilisant le langage de votre choix (Python, PHP, Java, JS, etc.).
3 – Envoyer vos CAPTCHAs à leur API.
4 – Recevoir les CAPTCHAs résolus dans la réponse de l’API.
Il existe plusieurs services de résolution de captcha sur le marché, dont certains sont remarquables :
- DeathByCaptcha
- AZCaptcha
- ImageTyperZ
- EndCaptcha
- BypassCaptcha
- CaptchaTronix
- AntiCaptcha
- 2Captcha
- CaptchaSniper
Résoudre les CAPTCHAs avec l’OCR
C’est une approche programmatique pour résoudre les CAPTCHAs. OCR signifie reconnaissance optique de caractères ou lecteur optique de caractères. Elle permet de convertir un texte dactylographié, manuscrit ou imprimé en texte codé par une machine. Il existe des outils OCR disponibles sur le marché qui peuvent être utilisés pour résoudre les captchas automatisés.
Il est important de noter que certains sites ont des protections en place pour empêcher l’utilisation d’outils OCR pour résoudre les captchas. Il est donc important de vérifier les règles du site avant de l’utiliser.
Octoparse permet de résoudre les CAPTCHAs lors du web scraping
Le suivant est un méthode totalement no-code, surtout destiné aux gens non informatiques qui rencontrent des captchas dans leur projet d’extraction de données.
Octoparse a lancé le service de résolution de CAPTCHAs pour améliorer l’efficacité de l’extraction de données. C’est une fonctionnalité intégrée et les utilisateurs peuvent l’ajouter dans son flux de travail de scraping au cas où il y a un CAPTCHA. Octoprase peut actuellement gérer automatiquement les trois types de Captcha : hCaptcha, ReCaptcha V2, et ImageCaptcha.
Pour les grands projets, l’équipe d’Octoparse propose le service de personnaliser des modèles JavaScript pour contourner les CAPTCHA/reCAPTCHA.
Les étapes à suivre pour résoudre les CAPTCHAs dans Octoparse
On a à ajouter l’étape de résoudre le captcha dans le flux de travail. Voilà les étapes. hCaptcha et ReCaptcha V2 peuvent être résolus de manière similaire, alors qu’il est plus compliqué de mettre en place une résolution pour traiter ImageCaptcha.
Comment résoudre hCaptcha et Recaptcha V2
- Cliquer sur ‘+’ dans le workflow et puis Sélectionner “Solve CAPTCHA“
2. Sélectionner hCaptcha/ReCaptcha V2 comme type de CAPTCHA
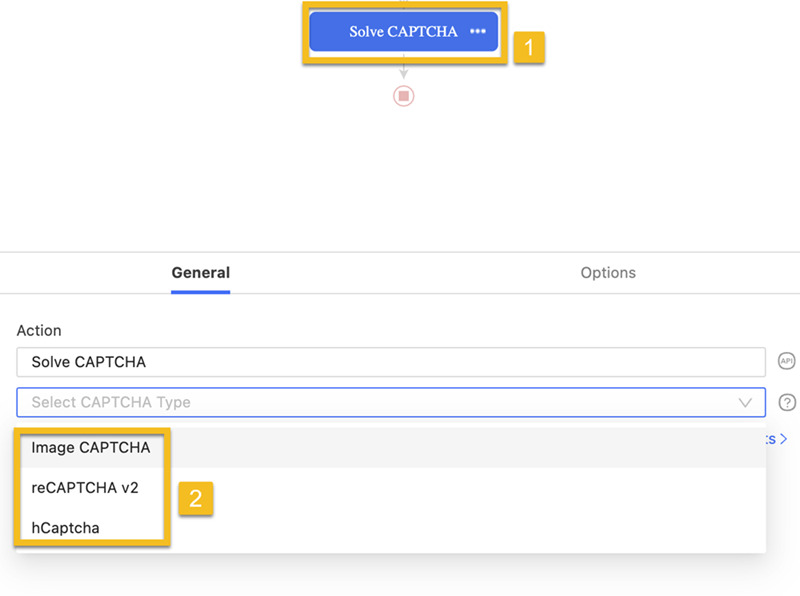
Remarque : hCaptcha et ReCaptcha ne seront pas résolus automatiquement jusqu’à ce que une exécution réelle de données commence. Ainsi, vous devez activer le mode de navigation et le résoudre manuellement dans la configuration de tâche.
Comment résoudre Image Captcha
Image Captcha peut utiliser des mots ou des phrases connus ou des combinaisons aléatoires de chiffres et de lettres. Certains ImageCaptcha incluent également des variations dans la capitalisation.

Pour suivre le guide et tester notre solution, vous pouvez utiliser ce URL: https://democaptcha.com/demo-form-eng/image.html
Trois étapes générales :
A. Sélectionnez la zone de saisie et la zone d’image pour le Captcha
- Cliquez sur le champ de saisie du Captcha et puis sélectionner Résoudre le Captcha dans le panneau Conseils
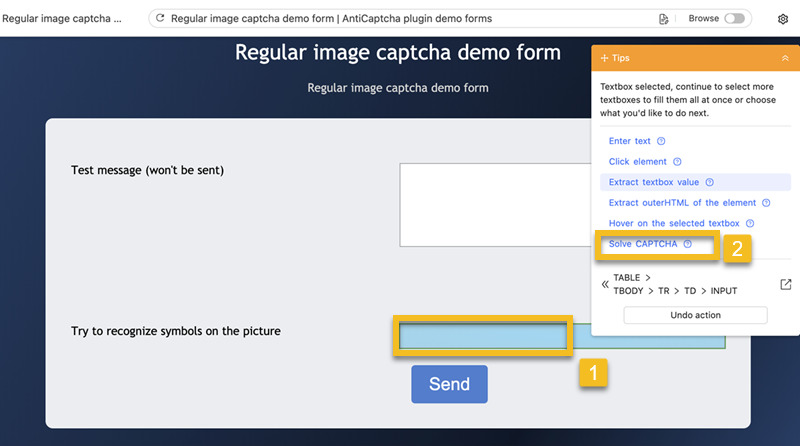
- Cliquez sur la boîte à images
- Cliquez sur le bouton Connexion/Soumettre/Confirmer pour continuer (parfois, il peut s’agir d’autres boutons, comme “Send” dans ce cas précis)
- Cliquez sur Confirmer dans le panneau des conseils
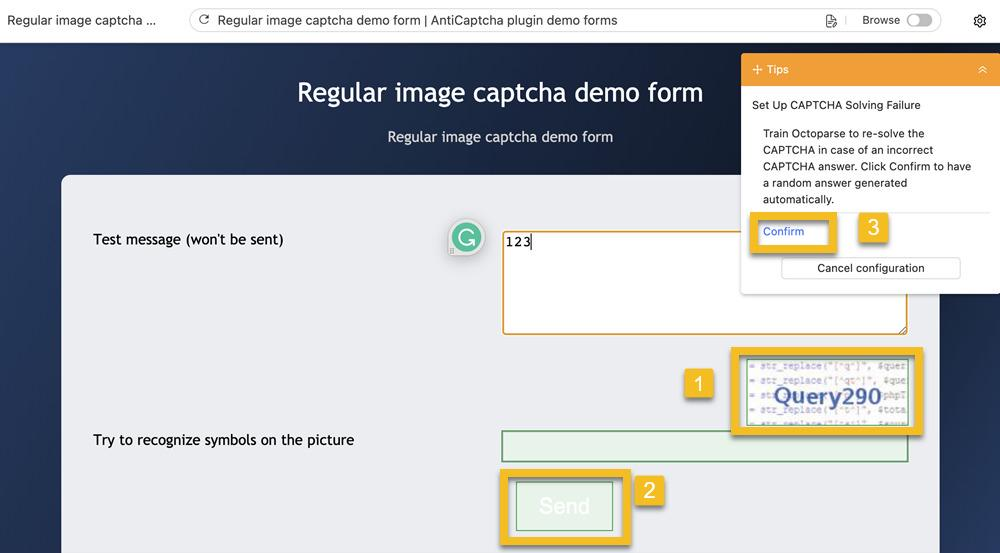
B. Configurer un échec de résolution de Captcha
Maintenant, nous devons entraîner Octoparse à résoudre le Captcha en mettant en place un échec de résolution.
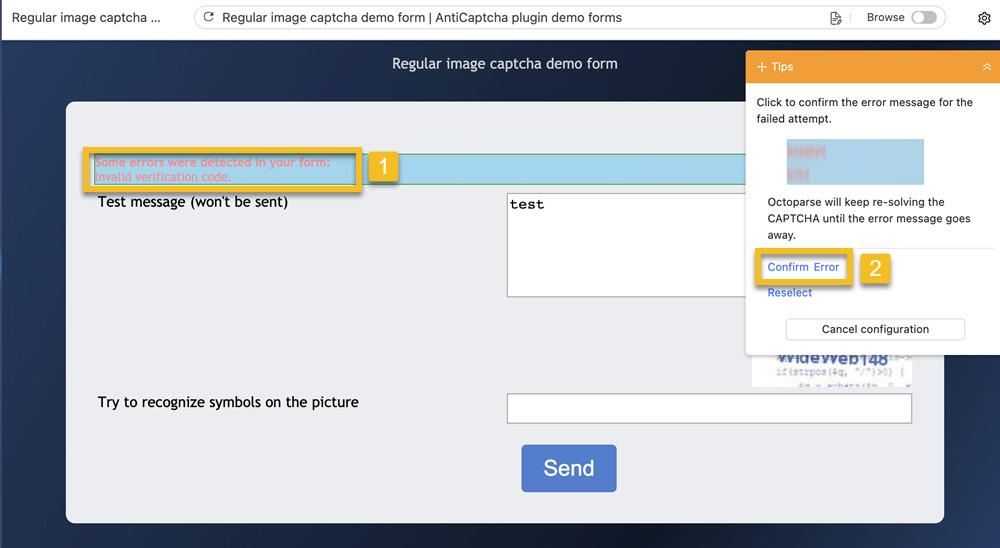
- Cliquez sur le message d’erreur (dans ce cas – Des erreurs ont été détectées dans votre formulaire : Code de vérification invalide)
- Cliquez sur Confirmer l’erreur dans le panneau Conseils
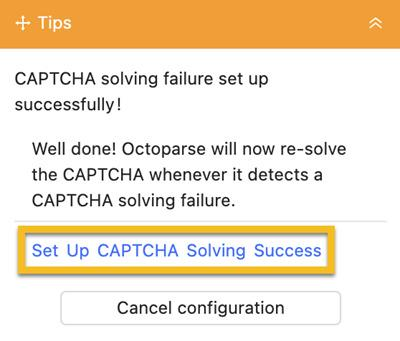
C. Configurer un succès de résolution de Captcha
- Cliquez sur Set Up CAPTCHA Solving Success pour passer à la dernière étape
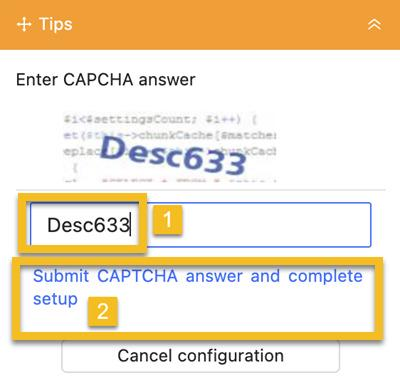
- Entrez le texte affiché dans la boîte à images
- Cliquez sur Soumettre la réponse CAPTCHA et terminez la configuration
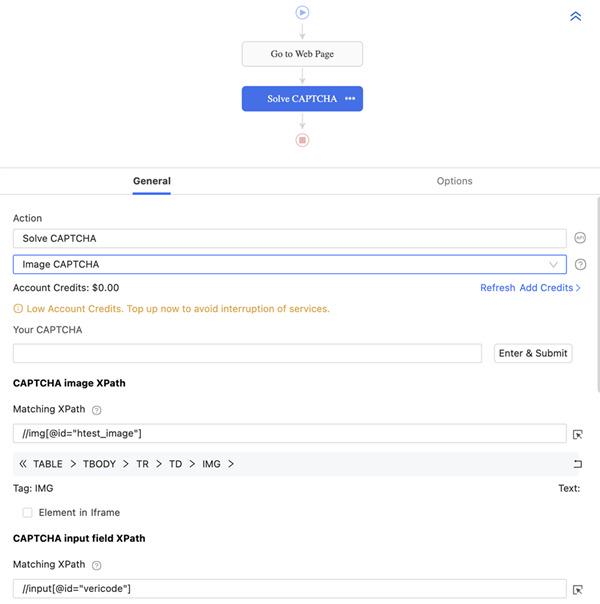
e Captcha d’image a maintenant été résolu. L’étape Résoudre CAPTCHA sera ajoutée au flux de travail et vous pouvez également modifier les paramètres sous le flux de travail.
Conseils pour éviter que les CAPTCHA n’interrompent votre scraping
- Utilisez des proxies IP rotatifs, des agents utilisateurs rotatifs et effacez vos cookies.
Octoparse vous propose des solutions pour les configurer. Normalement, le site Web détecte un service intégré de détection anti-scraping lorsque la même IP commence à attaquer les serveurs de manière agressive. Si vous utilisez des milliers de proxys et que vous les faites tourner, vous pouvez éviter les CAPTCHAs.
- Respectez le fichier Robots.txt.
Ce fichier contient les règles relatives aux préférences du site Web. Par exemple, les règlements indiquent si le site Web vous permet de le scrapper ou non. Si oui, quelles sont les URL que vous ne devez pas récupérer, et ainsi de suite.
- Utilisez des navigateurs sans tête
L’utiliser si vous écrivez votre scraper web. Des outils comme Octoparse s’en chargent automatiquement, car ce sont des browsers intelligents.
Essayez d’utiliser des headers et des referrers dans vos requêtes au serveur si vous n’utilisez pas un navigateur complet.
- Enregistrer des cookies
Pour l’extraction de données – derrière les logins, enregistrez les cookies. C’est ainsi que l’on peut faire dans Octoparse.
- Faites attention aux pièges invisibles du pot de miel sur les sites Web.
Ce sont les éléments ou les liens qui ne sont pas visibles, donc si vous avez écrit un crawler qui gratte ces liens, le site Web sait qu’il s’agit d’un bot car les humains ne peuvent pas cliquer sur ce lien en utilisant un navigateur normal comme Chrome ou Firefox.
- Maintenez des délais aléatoires entre les requêtes consécutives.
En particulier, lorsque vous sollicitez le site Web avec les mêmes adresses IP de manière répétitive.
- Utilisez les services de résolution des CAPTCHAS
En conclusion
Dans cet article, nous avons découvert différents types de CAPTCHAs, différentes approches pour résoudre les reCaptcha, la prévention des CAPTCHAs, et nous avons également parlé de la résolution des CAPTCHAs dans Octoparse. Pour vous rappeler encore une fois que, pour les grands projets, nous proposons la personnalisation de modèles Javascript pour intégrer les meilleurs services de résolution de CAPTCHA dans Octoparse. Contactez notre équipe pour toute demande de scraping. Bon scraping sans CAPTCHA !



