Doctolib centralise aujourd’hui plus de 70 millions de patients et près de 400 000 praticiens en France. Pour les équipes qui cherchent à accéder à ces données à grande échelle, le premier réflexe est souvent de chercher une API. Problème : l’accès officiel est fermé à tout le monde sauf aux partenaires agréés. Pour tous les autres, une alternative existe : le scraping no-code, accessible sans aucune compétence en programmation et opérationnel en moins de 30 minutes.
Dans cet article, on compare ces deux méthodes et on vous montre comment extraire des données médicales sur Doctolib en quelques étapes, en toute conformité avec le RGPD.
L’extraction de données médicales sur Doctolib, pour qui ?
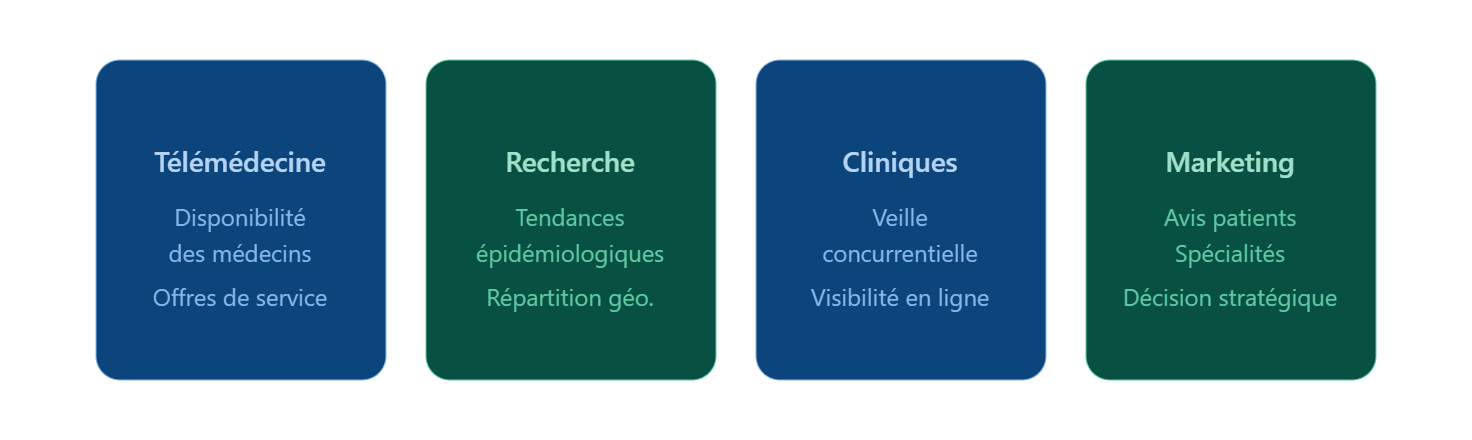
Les besoins en données issues de Doctolib concernent des profils très différents :
- Les entreprises de télémédecine et les plateformes de prise de rendez-vous cherchent à cartographier l’offre de soins disponible sur Doctolib, identifier les créneaux libres et ajuster leur couverture géographique en temps réel.
- Les chercheurs en santé publique et les analystes de marché utilisent ces données pour suivre les tendances épidémiologiques ou cartographier la répartition géographique des professionnels de santé sur le territoire français.
- Les médecins, cliniques et professionnels de santé s’appuient sur l’extraction de données pour analyser la visibilité de leurs concurrents et affiner leur stratégie de présence en ligne.
- Les équipes marketing et data analysts collectent des données sur la disponibilité, les spécialités et les avis patients pour affiner leur ciblage, benchmarker leur positionnement ou préparer une étude de marché.
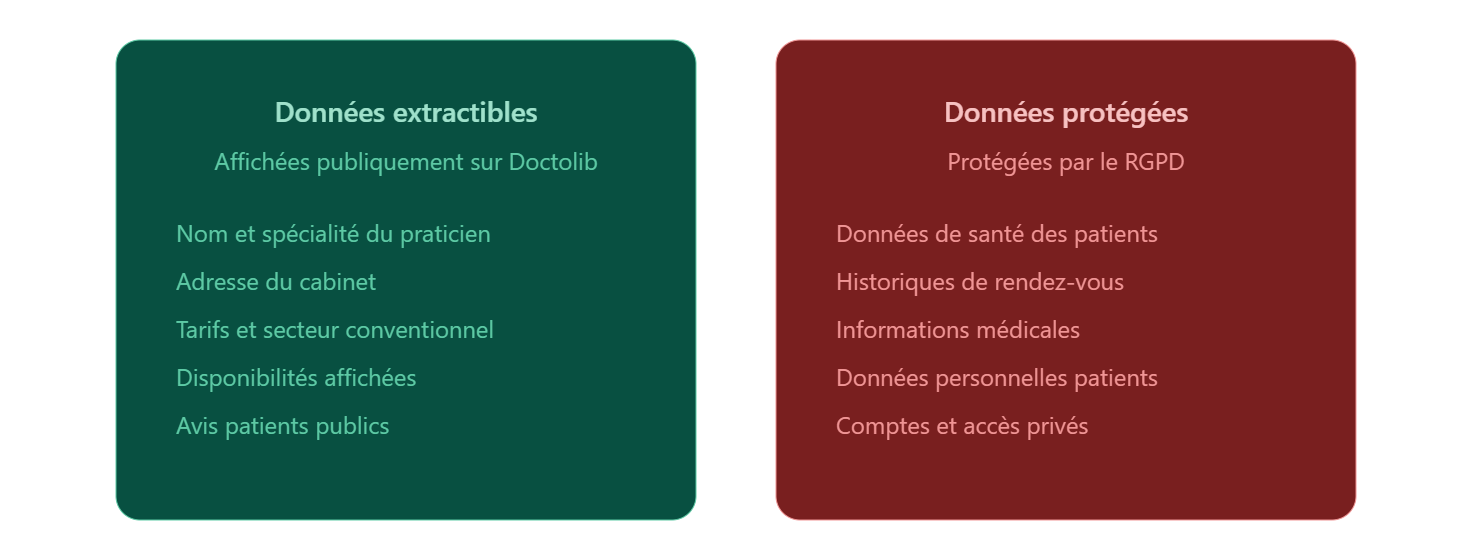
Quelles données peut-on extraire de Doctolib ?
En France, où la désertification médicale touche près de 30 % du territoire selon la DREES, l’accès à des données fiables sur les praticiens disponibles est un enjeu concret. Doctolib rend publiquement accessibles un grand nombre d’informations sur les praticiens et les établissements référencés. Concrètement, il est possible de collecter :
- Informations sur les praticiens : nom, spécialité, langues parlées, photo de profil, URL de la fiche
- Disponibilités : créneaux horaires ouverts à la réservation, délais moyens d’obtention d’un rendez-vous
- Tarifs et moyens de paiement : honoraires affichés, secteur conventionnel (1, 2 ou 3), modes de paiement acceptés
- Données sur les établissements : adresse, numéro RPPS, numéro SIREN, coordonnées GPS
- Avis patients : notes et commentaires publics laissés sur les fiches praticiens
Ces données sont affichées librement sur le site, ce qui les rend techniquement extractibles. La question de leur utilisation dans le respect du RGPD est traitée plus bas dans cet article.

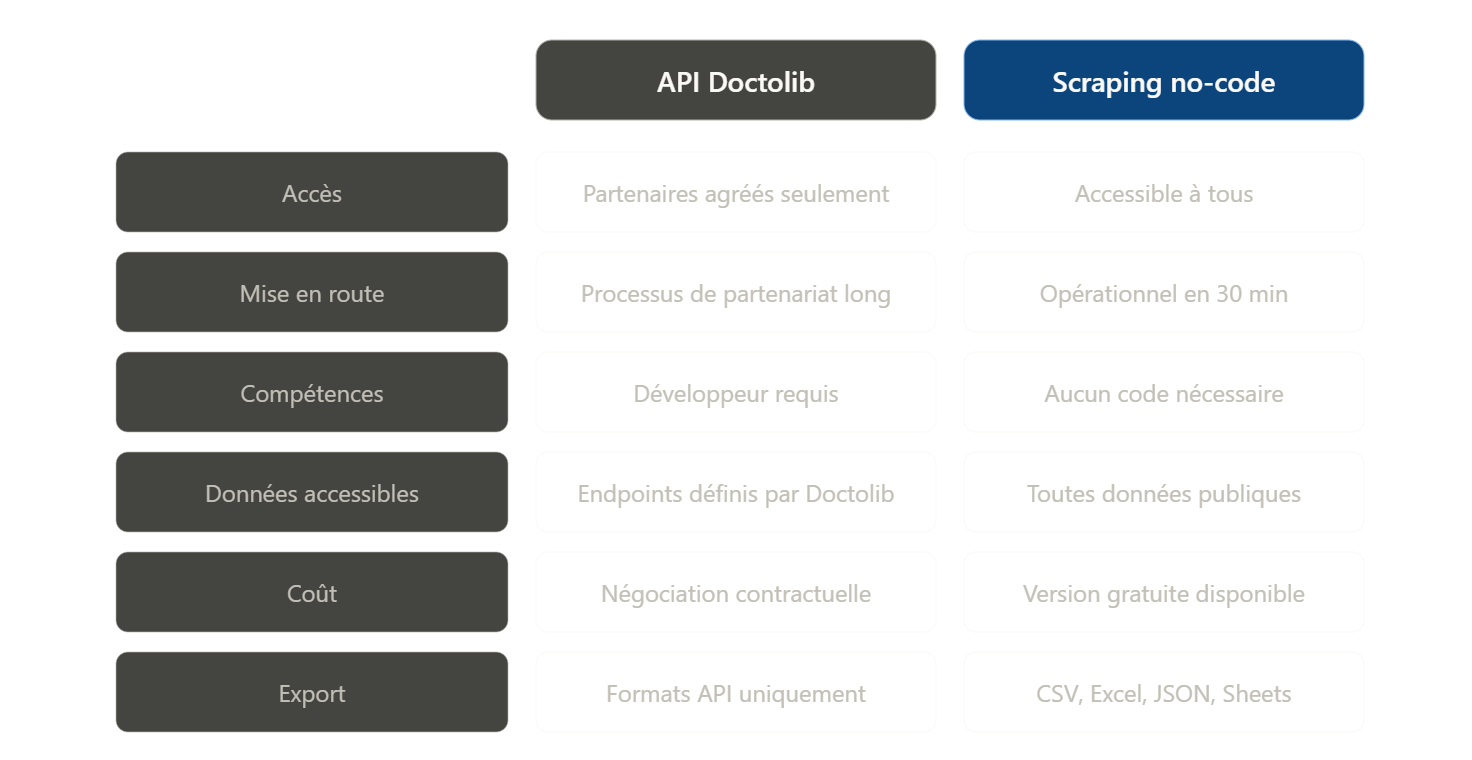
API Doctolib : ce que permet l’accès officiel
Doctolib propose une API officielle, mais son accès est réservé aux partenaires technologiques agréés : éditeurs de logiciels médicaux, systèmes d’information hospitaliers ou plateformes de coordination de soins. En dehors de ce cadre partenarial, il n’existe pas d’accès public à l’API Doctolib pour un usage individuel ou commercial.
Ce que permet l’API officielle pour les partenaires :
- Synchronisation des agendas avec des logiciels métiers (ex. : DMP, logiciels de cabinet)
- Accès structuré aux créneaux de disponibilité en temps réel
- Intégration dans des workflows de prise en charge patient
Doctolib met à disposition une documentation technique à destination de ses partenaires via son portail développeur, mais celle-ci n’est pas accessible publiquement sans accréditation préalable.
Pour les équipes qui ne sont pas partenaires Doctolib, l’API n’est donc pas une option accessible. Le scraping no-code représente alors l’alternative la plus pratique pour collecter des données publiques à grande échelle, sans passer par un processus de partenariat long et sélectif.
Créer l’extracteur de données médicales
Octoparse permet de mettre en place un extracteur de données sur Doctolib en quelques minutes, sans écrire une seule ligne de code. Voici les 4 étapes pour collecter les informations des praticiens en masse.
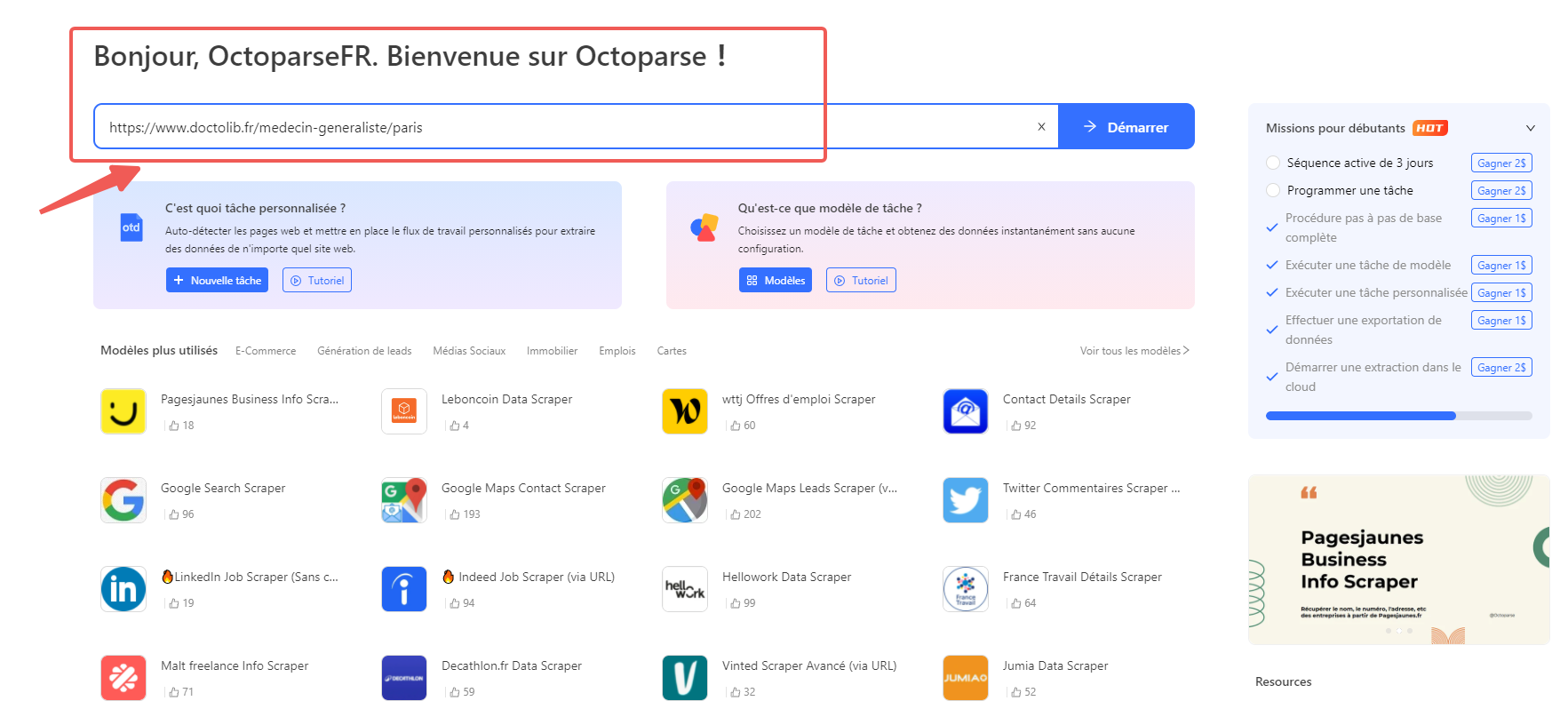
Étape 1 : Ouvrir Octoparse et cibler une page Doctolib
Le client Octoparse est disponible sur Windows et Mac : téléchargez-le gratuitement puis ouvrez-le sur votre ordinateur. Dans la barre de saisie, collez l’URL de la page Doctolib que vous souhaitez scraper. Par exemple, pour extraire les médecins généralistes à Paris, utilisez directement : https://www.doctolib.fr/medecin-generaliste/paris
Octoparse charge la page dans son navigateur intégré et se prépare à détecter les éléments à extraire.
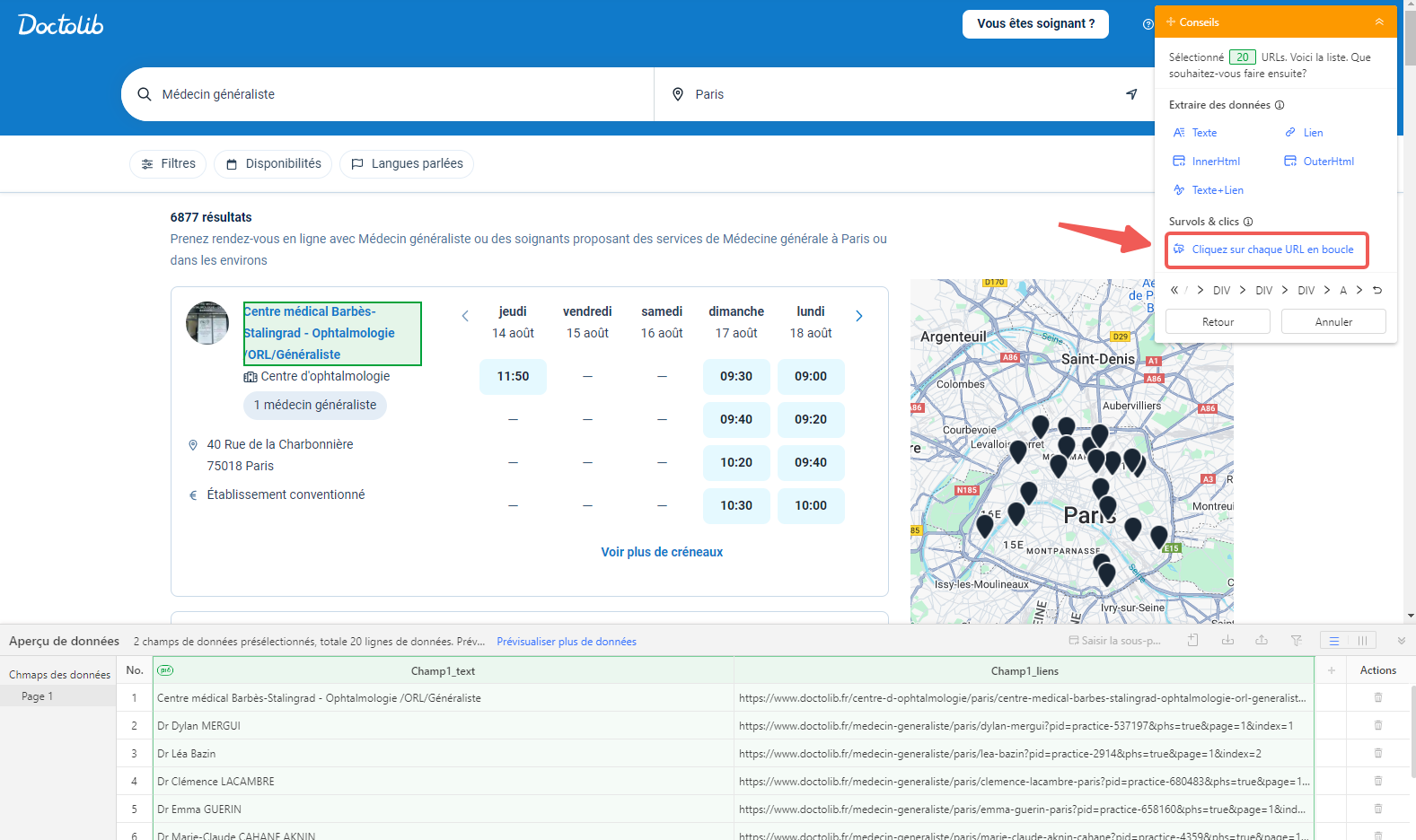
Étape 2 : Sélectionner les fiches praticiens et activer la navigation sous-page
Sur la page chargée, cliquez sur le nom d’un praticien puis sélectionnez “Choisir les éléments similaires“ pour que l’outil identifie automatiquement tous les éléments de même type. Dans le panneau de conseils, choisissez ensuite “Cliquer sur chaque URL en boucle“ : Octoparse ira visiter la fiche individuelle de chaque praticien pour en extraire les données détaillées (tarif, adresse, spécialité, etc.).
Étape 3 : Construire le flux d’extraction de données médicales
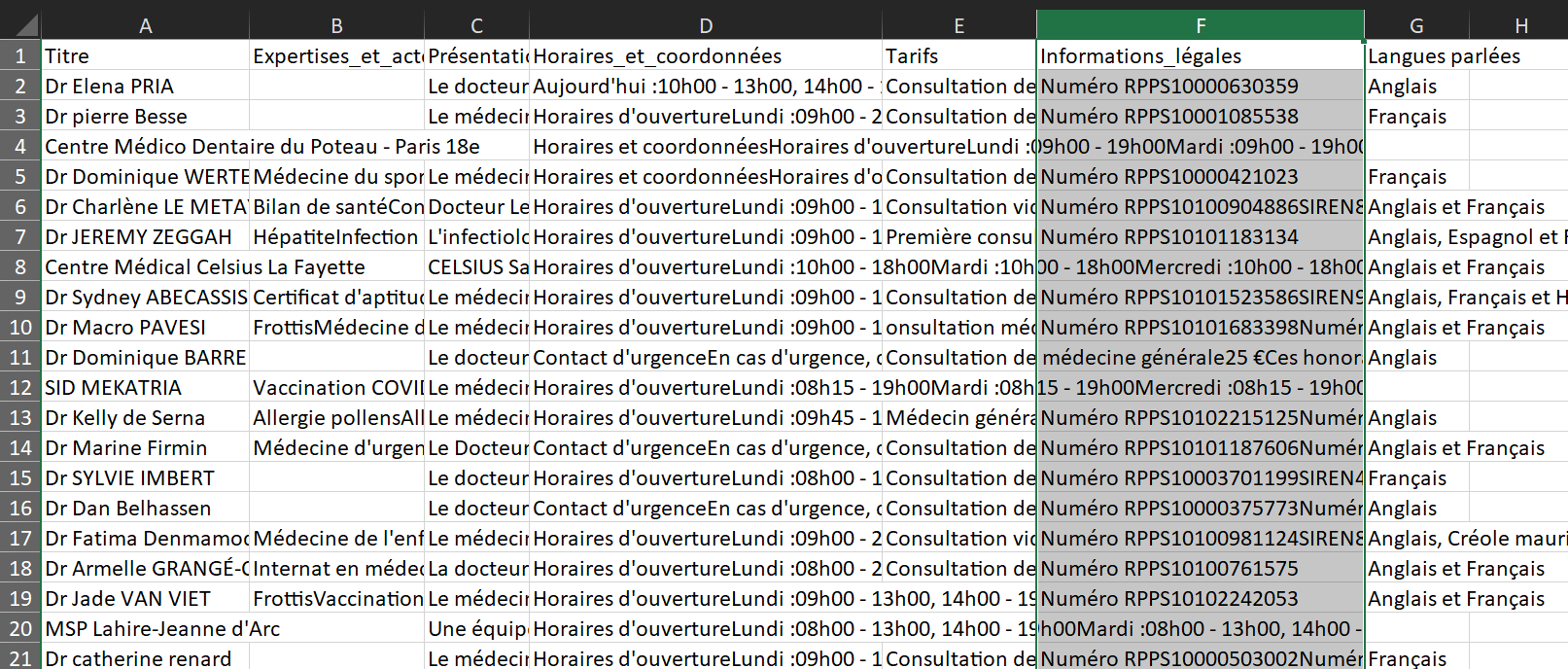
Les éléments sélectionnés apparaissent surlignés en vert dans l’interface. Cliquez sur chaque champ à extraire (nom, tarif, adresse, spécialité) pour les ajouter à votre flux de travail. L’aperçu des données en bas de l’écran vous permet de vérifier en temps réel ce qui sera collecté. Vous pouvez renommer les champs ou en supprimer selon vos besoins avant de lancer l’extraction.
Si les données affichées dans l’aperçu correspondent bien à ce que vous souhaitez collecter, vous êtes prêt pour la dernière étape.
Étape 4 : Paginer les résultats et exporter vers Excel ou CSV
Pour parcourir toutes les pages de résultats automatiquement, cliquez sur “Bouton page suivante“ dans le panneau de conseils. Octoparse passera d’une page à l’autre jusqu’à épuisement des résultats. Une fois la configuration terminée, lancez l’extraction et exportez vos données au format CSV ou Excel en un clic.
L’Auto-détection de données médicales
Pour aller encore plus vite, Octoparse propose une fonctionnalité d’auto-détection du contenu qui identifie automatiquement les données pertinentes sur la page sans configuration manuelle. Il suffit de coller l’URL cible : l’outil analyse la structure de la page et génère un flux d’extraction prêt à l’emploi.
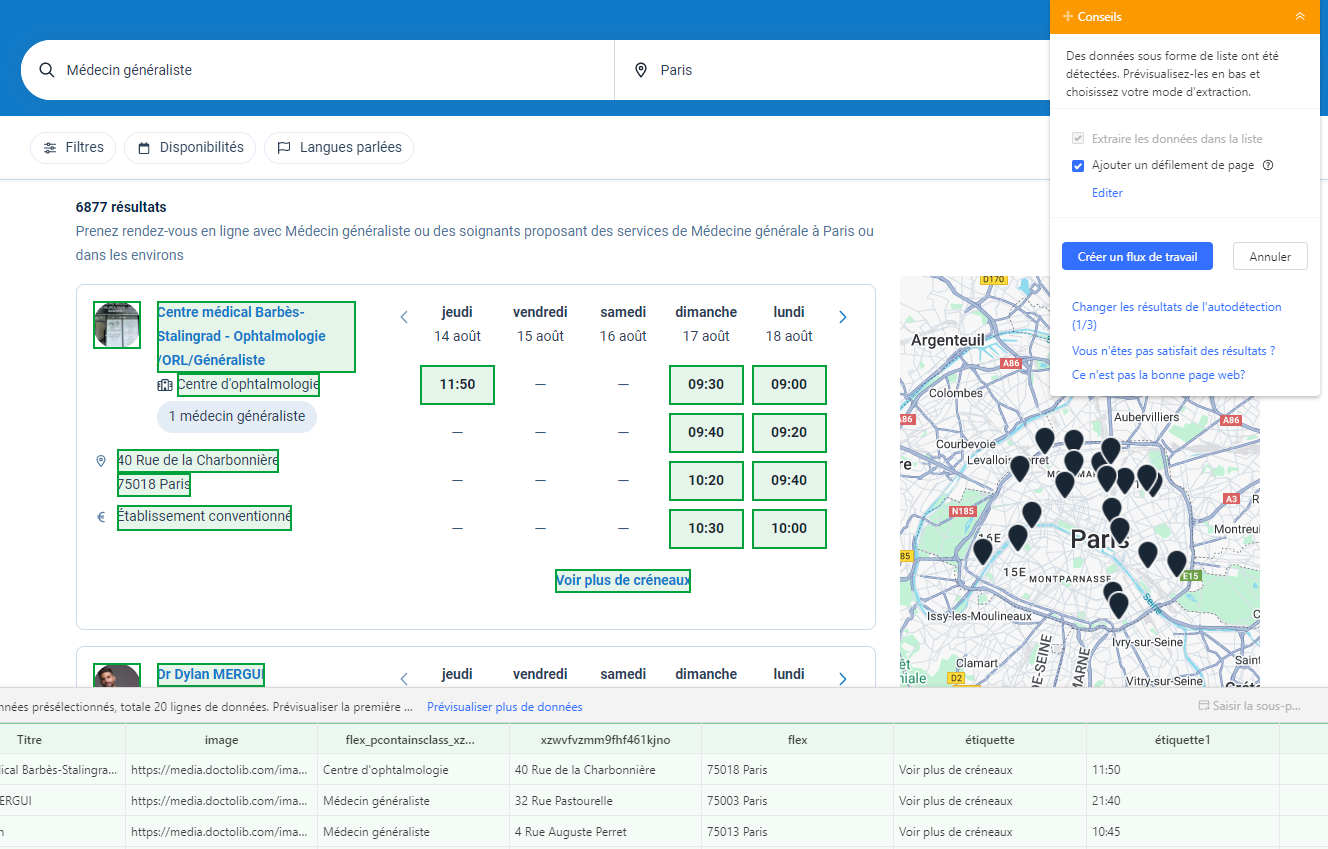
Cette approche est particulièrement adaptée aux collectes ponctuelles ou aux utilisateurs qui débutent avec le scraping. Pour des extractions plus complexes ou multi-pages, le mode manuel décrit plus haut offre davantage de contrôle sur les champs collectés.
Octoparse permet également de programmer des extractions récurrentes : vous pouvez planifier une collecte quotidienne ou hebdomadaire pour suivre en continu l’évolution des disponibilités, des tarifs ou des nouveaux praticiens référencés sur Doctolib.
Pour tester la fonctionnalité sur une page Doctolib, un essai gratuit de 14 jours est disponible sans carte bancaire.
Doctolib et RGPD : ce qu’il faut savoir avant de collecter des données
En France, la collecte de données personnelles est encadrée par le RGPD et les recommandations de la CNIL. Avant de lancer une extraction sur Doctolib, quelques points essentiels à garder en tête :
- Les données publiquement affichées sur Doctolib (nom du praticien, spécialité, adresse du cabinet, tarifs) sont accessibles à tous les internautes. Leur collecte à des fins d’analyse interne ou de veille concurrentielle est en principe admise, sous réserve de respecter le principe de minimisation des données du RGPD et de ne pas les utiliser à des fins de prospection commerciale non sollicitée.
- Les données personnelles des patients (historiques de rendez-vous, informations de santé) ne sont pas accessibles publiquement sur Doctolib et ne doivent en aucun cas faire l’objet d’une tentative d’extraction.
- L’usage commercial des données collectées doit respecter les conditions générales d’utilisation de Doctolib et les obligations du RGPD, notamment en matière de finalité et de durée de conservation.
Pour aller plus loin sur le cadre légal du scraping en France, les mêmes principes s’appliquent à Doctolib : le cadre juridique du scraping de données publiques en France y est analysé en détail, avec les conditions posées par la CNIL. La CNIL met à disposition un guide pratique sur la réutilisation de données publiques, consultable directement sur cnil.fr.

Collecter les données publiques de praticiens, tarifs et disponibilités depuis Doctolib vers Excel ou CSV.
Auto-détecter les éléments à extraire sur n’importe quelle page médicale sans configuration complexe.
Utiliser les modèles pré-construits pour lancer une extraction en quelques clics.
Contourner les blocages grâce aux proxies IP rotatifs et à l’API avancée.
Programmer des extractions récurrentes pour surveiller Doctolib en continu depuis le cloud.
Conclusion
L’API officielle de Doctolib reste inaccessible sans partenariat agréé. Pour les équipes qui ont besoin de données médicales publiques à grande échelle, le scraping no-code constitue l’alternative la plus directe, et la version gratuite d’Octoparse suffit largement pour démarrer.
Que ce soit pour une veille concurrentielle, une étude de marché ou l’alimentation d’un CRM médical, Octoparse s’adapte à la structure de Doctolib et à l’évolution de ses pages sans nécessiter de reconfiguration manuelle à chaque mise à jour du site. Pour ceux qui veulent aller plus loin, les paramètres d’export et les options de planification sont accessibles dès l’inscription sur octoparse.fr.
FAQ
- Peut-on scraper Doctolib légalement ?
La collecte de données publiquement affichées sur Doctolib (nom, spécialité, tarifs, adresse) est techniquement possible et en principe admise à des fins d’analyse interne ou de veille concurrentielle, sous réserve de respecter les obligations du RGPD. En revanche, toute extraction de données personnelles de patients ou une utilisation à des fins de démarchage non consenti expose à des sanctions au titre du RGPD. En cas de doute, consultez un juriste spécialisé en droit du numérique.
- L’API Doctolib est-elle accessible gratuitement ?
Non. L’API officielle de Doctolib est réservée aux partenaires technologiques agréés (éditeurs de logiciels médicaux, systèmes d’information hospitaliers). Il n’existe pas d’accès public ou en libre-service à cette API.
- Quels formats d’export sont disponibles avec Octoparse ?
Octoparse permet d’exporter les données extraites en CSV, Excel, JSON ou directement vers une base de données. L’export vers Google Sheets est également possible via l’API Octoparse.
- Faut-il des compétences en programmation pour scraper Doctolib avec Octoparse ?
Non. Octoparse est un outil no-code : la configuration de l’extracteur se fait entièrement en mode visuel, par clics. La fonctionnalité d’auto-détection permet même de générer un flux d’extraction automatiquement sans aucune configuration manuelle.
- Doctolib bloque-t-il les outils de scraping ?
Doctolib met en place des mesures techniques pour limiter les accès automatisés, notamment des limitations de débit et des mécanismes de détection de bots. Octoparse contourne ces restrictions grâce à la rotation de proxies IP et à la simulation d’un comportement de navigation humain. Pour des extractions volumineuses, il est conseillé de configurer des délais entre les requêtes afin de rester dans des limites raisonnables.
- Peut-on automatiser les extractions sur Doctolib ?
Oui. Octoparse propose un service cloud qui permet de programmer des extractions récurrentes (quotidiennes, hebdomadaires) sans laisser son ordinateur allumé. Les données sont collectées et disponibles à l’export dès la fin de chaque tâche planifiée.



