Si vous cherchez la meilleure méthode pour télécharger une page web ou pour extraire automatiquement des contenus d’une page web précise, peut-être vous avez aussi besoin d’adopter des techniques d’extraction de données pour alimenter vos modèles analytiques ou une veille concurrentielle efficace, non ?
Cet article vous propose une compréhension des méthodes usuelles d’extraction de données, à illustrer comment télécharger une page web ou son contenu de manière automatisée efficacement pour vous aider à établir une recherche de base de données précise.
Qu’est-ce que l’extraction de données ?
L’extraction de données est le terme générique désignant le processus systématique de récupération, de transformation, de structuration d’informations provenant de sources diverses du numérique, notamment sur le web, en organisant l’information dont l’exploitation à des fins analytiques, décisionnelles, etc. est souhaitée, dans des formats exploitables, souvent à partir de contenus bruts, non structurés ou semi-structurés. À la différence des approches traditionnelles de collecte de données à l’aide de méthodes manuelles, l’extraction de données fondée aujourd’hui sur diverses solutions techniques automatisées ou semi-automatisées, s’appuie sur des algorithmes complexes d’analyse de contenu, de reconnaissance de structure, d’interprétation sémantique, qui permettent de traiter des données dynamiques telles que celles fournies par des pages web interactives, des flux en temps réel, des contenus multimédia, etc. en intégrant au besoin des outils avancés d’intelligence artificielle, de machine learning, de traitement du langage naturel.
Applications dans différents secteurs
- Recherche et académique
Les chercheurs exploitent l’extraction de données pour analyser rapidement d’importants corpus d’articles et de bases de données en ligne, efficacement et d’une manière guidée, pour synthétiser des informations et détecter automatiquement des tendances (pour l’entraînement de modèles de langage ou l’analyse de corpus par exemple).
- Marketing et analyse de marché
Les entreprises recourent à l’extraction automatique pour surveiller la réputation, analyser l’opinion publique, suivre la concurrence ou collecter des données sociales permettant l’élaboration des stratégies marketing orientées data.
- Business intelligence
L’intégration de données extraites dans des systèmes de BI permet de construire des dashboards, d’anticiper les tendances et d’optimiser la gestion opérationnelle, en temps ou quasi temps réel.
- Surveillance de marché et veille concurrentielle
Des acteurs économiques et des institutions gouvernementales recourent aux moyens de l’automatisation pour suivre l’évolution d’un secteur clé, identifier une opportunité et anticiper un risque en puisant dans un maelstrom d’informations disparates à forte volumétrie.
- Autres secteurs
L’agroalimentaire, la finance, la santé ou la cybersécurité exploitent aussi cette méthode à des fins d’analyse prédictive, de détection de fraude ou de gestion des risques dans tout environnement manipulant d’importants volumes de contenus numériques.
Comment obtenir du contenu à partir de pages web
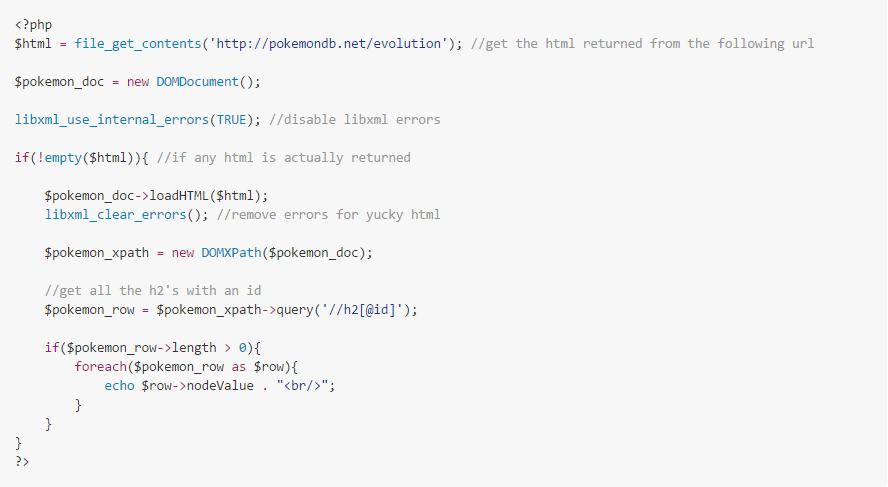
Pour les programmeurs ou les développeurs, l’utilisation de Python est le moyen le plus courant de construire un scraper/crawler web pour extraire du contenu web. Par exemple, le code de la capture d’écran ci-dessous peut être utilisé pour extraire des données d’un site Web public – pokemondb.net.
L’extraction automatique de données sans coder
Pour la plupart de personnes qui ne savent pas coder, il est préférable d’utiliser des outils d’extraction des pages Web pour en extraire un contenu spécifique. Vous trouverez ci-dessous quelques solutions utilisant Octoparse :
Extraire le contenu de la page web dynamique
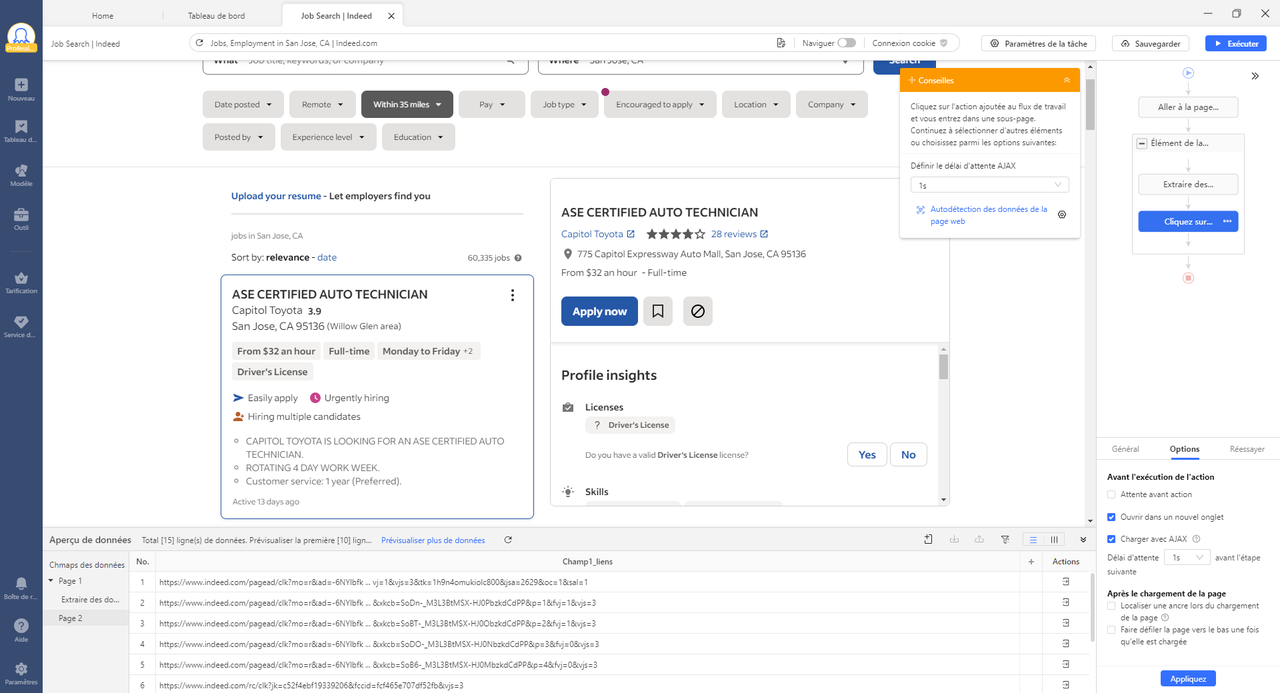
Les pages web peuvent être statiques ou dynamiques. Il est fréquent que votre site web cible applique la technique AJAX. Ajax permet à la page Web d’envoyer et de recevoir des données en arrière-plan sans interférer avec l’affichage de la page Web. Dans ce cas, vous pouvez activer l’option AJAX proposée par Octoparse pour extraire le contenu de pages Web dynamiques.
Extraire le contenu qui est caché de la page web
Avez-vous déjà voulu obtenir des données spécifiques d’un site Web, mais le contenu n’apparaît qu’après avoir déclenché un lien ou passé le curseur de la souris ? Par exemple, certaines informations de contact sur craigslist.org apparaissent après que vous ayez cliqué sur le bouton Répondre.
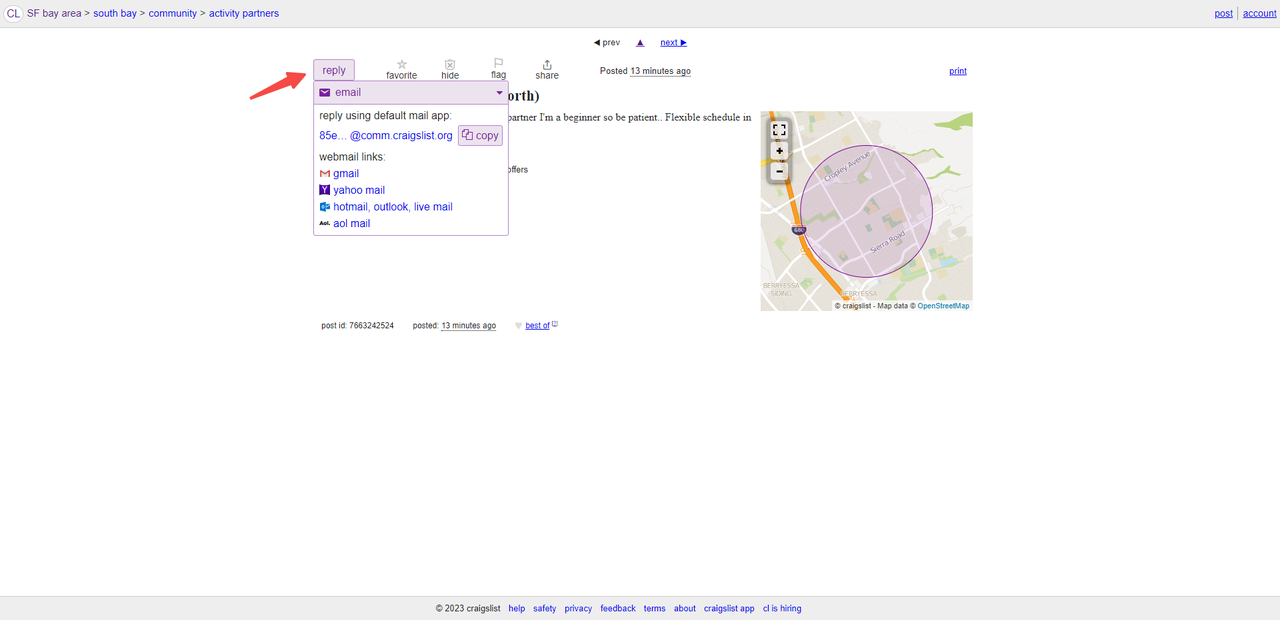
En fait, un tel contenu caché pourrait se trouver dans le code source HTML de cette page web. Octoparse peut extraire le texte entre le code source. Il est facile d’utiliser la commande “Cliquer sur le bouton” ou une commande “Survoler le texte sélectionné” dans le panneau “Conseil” pour réaliser l’action d’extraction.
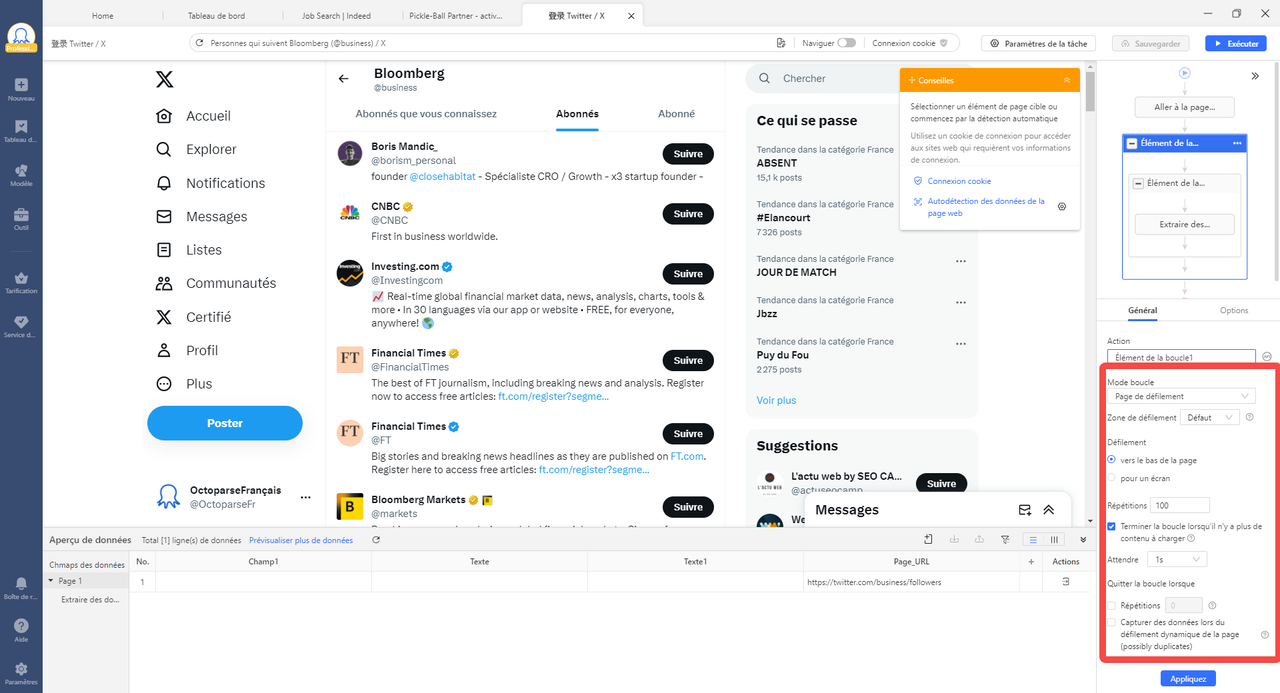
Extraire le contenu de la page web avec un défilement infini
Vous pouvez également remarquer que certains messages ne sont téléchargés qu’une fois que vous avez fait défiler la page Web jusqu’au bas, comme c’est le cas pour Twitter. Cela est dû au fait que les sites Web appliquent le défilement infini pour le chargement de contenu. Le défilement infini s’accompagne généralement d’AJAX ou de JavaScript pour que les requêtes se produisent lorsque vous atteignez la fin de la page Web. Dans ce cas, vous pouvez définir le délai d’attente d’AJAX, sélectionner la méthode de défilement infini et définir d’autres paramètres relatifs pour que le robot extrait le contenu selon vos besoins..
Extraire les hyperliens ou les URLs des images de la page web
Un site Web normal contient au moins un grand nombre de hyperliens et si vous souhaitez extraire tous les liens d’une page Web, vous pouvez utiliser Octoparse pour vous aider à extraire toutes les URL de l’ensemble du site.
Extracteur d’URL : Comment extraire toutes les URLs d’un site Web ?
Extraire le texte de la page web
Si vous souhaitez extraire le contenu situé entre les tags HTML tels que le tag <DIV> ou le tag <SPAN>. Octoparse vous permet d’extraire tout le texte entre le code source.
Récupérer des données d’un site Web vers Excel (Tutoriel 2025)
Télécharger les images ou d’autres fichiers de la page web
Octoparse permet non seulement de récupérer les textes, les contenus affichés sur des pages Web, mais également peut être utilisé pour télécharger les images ou d’autres fichiers sous formats de Excel, PDF, etc.
4 façons de télécharger toutes les images d’un site efficacement

Transformer les sites web vers Excel, CSV, Google Sheets ou base de données.
Auto-détecter les sites Web et extraire les données sans aucun codage.
Scraper les sites populaires en quelques clics avec les modèles pré-construits.
Ne se trouver jamais bloqué grâce aux proxies IP et à l’API avancée.
Service Cloud pour programmer le scraping de données.
FAQ
- Quelles fonctionnalités d’Octoparse permettent d’extraire des contenus complexes ou en grande quantité ?
Octoparse propose des fonctionnalités telles que l’auto-détection de la structure de page, l’extraction basée sur l’intelligence artificielle, la gestion des pages dynamiques avec AJAX/JavaScript, et la planification de tâches pour une extraction en masse. Le moteur de scraping intelligent peut automatiquement repérer les éléments souhaités, ce qui optimise la précision même sur des sites complexes ou fortement changeants.
- Peut-on automatiser la mise à jour et l’intégration des données extraites dans une base de données ?
Oui, Octoparse permet de planifier des tâches d’extraction automatique à intervalles réguliers. Les données exportées peuvent directement être connectées à des bases de données SQL, Google Sheets ou des outils analytiques via des connecteurs API, facilitant une intégration continue et en temps réel pour la veille stratégique ou l’analyse approfondie.
- Quelles sont les limites techniques d’Octoparse et comment les dépasser pour des grands volumes de données ?
Octoparse fonctionne efficacement pour la majorité des tâches de web scraping, mais peut rencontrer des limites en cas de sites très protégés. Pour dépasser ces limitations, il est conseillé d’utiliser Octoparse dans le Cloud pour bénéficier de ressources scalables, ou d’adopter une stratégie de crawl réparti sur plusieurs comptes ou instances.
- Quelles stratégies utiliser avec Octoparse pour contourner les CAPTCHAs ?
Octoparse propose des fonctionnalités de rotation d’IP, l’intégration de proxies, et la simulation de comportements humains pour contourner des systèmes anti-scraping comme les CAPTCHAs.
En conclusion
Octoparse peut extraire tout ce qui est affiché sur la page Web, et l’exporter vers des formats structurés comme Excel, CSV, HTML, TXT et d’autres bases de données. Je vous invite à télécharger Octoparse pour découvrir sa puissance tout en profitant de riches tutoriels.



