Vous avez probablement entendu parler de l’apprentissage automatique des milliers de fois, mais avez-vous une idée de ce que c’est vraiment? Eh bien, dans cet article, j’ai inclus les 8 termes clés les plus directement liés à ce sujet. Il n’y a rien d’extravagant ou de compliqué, et j’espère que toute personne intéressée par l’apprentissage automatique&machine learning pourra retirer quelques points utiles de la lecture de cet article.
1. Traitement du langage naturel(TLN ou NLP)
Le NLP est un concept très courant pour l’apprentissage automatique. Il a permis à un ordinateur de lire le langage humain et de l’incorporer dans toutes sortes de processus.
Les applications les plus connues de NLP comprennent:
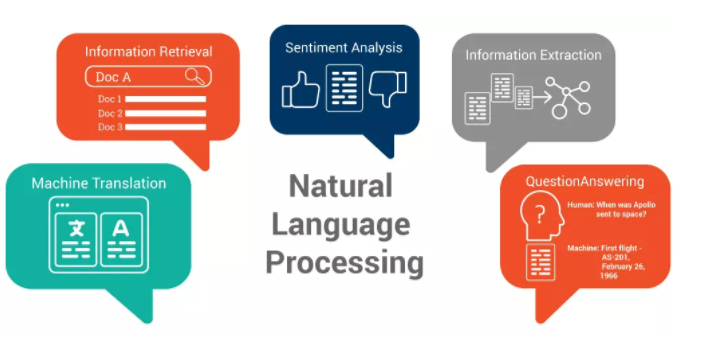
(a) Classification et tri de textes.
Il s’agit de classer des textes dans différentes catégories, ou de trier une liste de textes en fonction de leur pertinence. Par exemple, il peut être utilisé pour éliminer les spams (en analysant si les mails sont des spams ou non), ou dans le domaine des affaires, il peut également être utilisé pour identifier et extraire des informations relatives à vos concurrents.
(b) Opinion mining(Sentiment analysis)
Avec l’analyse des sentiments, un ordinateur sera capable de déchiffrer les sentiments, tels que la colère, la tristesse, la joie, etc. en analysant les chaînes de caractères. En fait, un ordinateur sera capable de dire si les gens se sentent heureux, tristes ou en colère au moment où ils tapent les mots ou les phrases. Cette méthode est largement utilisée dans les enquêtes de satisfaction de la clientèle pour analyser les sentiments des clients à l’égard d’un produit.
(c) Extraction d’informations(EI)
Elle est principalement utilisée pour résumer un long paragraphe en un texte court, un peu comme pour créer un résumé.
(d) Reconnaissance d’entités nommées
Supposons que vous ayez extrait un ensemble de données de profil désordonnées, telles qu’une adresse, un téléphone, un nom et bien d’autres encore, toutes mélangées les unes aux autres. Vous n’aimeriez pas pouvoir nettoyer ces données pour que elles soient toutes identifiées et associées aux types de données appropriés? C’est exactement comme cela que l’extraction d’entités nommées aide à transformer des informations désordonnées en données structurées.
(e) Reconnaissance vocale
Un excellent exemple: Siri pour Apple.
(f) La Natural language generation (NLG) et le natural language understanding (NLU)
La NLU consiste à utiliser l’ordinateur pour transformer des expressions humaines en expressions informatiques. Au contraire, la génération de langage naturel consiste à transformer des expressions informatiques en expressions humaines. Cette technologie est très couramment utilisée pour la communication entre humains et robots.
(g) Traduction automatique
La traduction automatique consiste à traduire automatiquement des textes dans une autre langue (ou dans des langues spécifiques).
2. Base de données
La base de données est un élément nécessaire à l’apprentissage automatique. Si vous souhaitez établir un système d’apprentissage automatique, vous devrez soit collecter des données à partir de ressources publiques, soit générer de nouvelles données. Tous les ensembles de données qui sont utilisés pour l’apprentissage automatique sont combinés pour former la base de données. En général, les scientifiques divisent les données en trois catégories :
Jeux d’entrainement: Les jeux de données d’entraînement sont utilisés pour l’entraînement des modèles. Grâce à l’entraînement, les modèles d’apprentissage automatique seront capables de reconnaître les caractéristiques importantes des données.
Jeux de validation: Les jeux de validation sont utilisés pour ajuster les coefficients des modèles, et pour comparer les modèles afin de sélectionner le meilleur. Les jeux de données de validation sont différents des jeux de données d’entraînement et ne peuvent pas être utilisés dans la section d’entraînement, sinon un surajustement pourrait se produire et avoir un effet négatif sur la génération de nouvelles données.
Jeux de test: Une fois le modèle confirmé, le jeu de test est utilisé pour tester les performances du modèle dans un nouveau dataset.
Dans l’apprentissage automatique traditionnel, le rapport entre ces trois types de jeux de données est de 50/25/25; toutefois, certains modèles n’ont pas besoin d’être beaucoup ajustés ou le jeu de données d’entraînement peut en fait être une combinaison d’entraînement et de validation (validation croisée), ce qui fait que le rapport entraînement/test peut être de 70/30.
3. Vision par ordinateur
La vision par ordinateur est un domaine de l’intelligence artificielle axé sur l’analyse et la compréhension des images et des données vidéo. Les problèmes que l’on rencontre souvent en vision par ordinateur sont les suivants :
Classification d’images: La classification d’images est une tâche de vision par ordinateur qui apprend à l’ordinateur à reconnaître certaines images. Par exemple, l’entraînement d’un modèle pour reconnaître des objets particuliers apparus à des endroits spécifiques.
Target detection: La reconnaissance automatique des cibles consiste à apprendre au modèle à détecter une classe particulière parmi une série de catégories prédéfinies, et à utiliser des rectangles pour les encercler. Par exemple, la détection de cible peut être utilisée pour configurer un système de reconnaissance des visages. Le modèle peut détecter toutes les matières prédéfinies et les mettre en évidence.
Segmentation d’images: La segmentation d’images est le processus qui consiste à diviser une image numérique en plusieurs segments (ensembles de pixels, également appelés super-pixels). Le but de la segmentation est de simplifier et/ou de modifier la représentation d’une image en quelque chose de plus significatif et de plus facile à analyser.
Test de signification: Une fois que les données d’un échantillon ont été collectées par le biais d’une étude d’observation ou d’une expérience, l’inférence statistique permet aux analystes d’évaluer les preuves en faveur ou en défaveur de certaines affirmations concernant la population dont l’échantillon a été tiré. Les méthodes d’inférence utilisées pour soutenir ou rejeter des affirmations basées sur des données d’échantillon sont connues sous le nom de test de signification statistique.

4. Apprentissage supervisé
L’apprentissage supervisé est une tâche de machine learning qui consiste à déduire une fonction à partir de données étiquetées. Un algorithme d’apprentissage supervisé analyse les données et produit une fonction déduite, qui peut être utilisée pour cartographier de nouveaux exemples. Un scénario optimal permettra à l’algorithme de déterminer correctement les étiquettes de classe pour des instances non vues. Donc, l’algorithme d’apprentissage doit être généralisé à partir des données d’apprentissage à des situations inconnues de manière “raisonnable”.
5. Apprentissage non-supervisé
L’apprentissage automatique non supervisé est la tâche d’apprentissage automatique qui consiste à déduire une fonction pour décrire une structure cachée à partir de données “non étiquetées”. Puisque les exemples donnés à l’apprenant ne sont pas étiquetés, il n’y a pas d’évaluation de la précision de la structure produite par l’algorithme pertinent – ce qui est une façon de distinguer l’apprentissage non supervisé de l’apprentissage supervisé et de l’apprentissage par renforcement.

6. Apprentissage par renforcement
L’apprentissage par renforcement s’apparente au processus de jeu avec les ordinateurs, et son objectif est d’entraîner les ordinateurs à effectuer des actions dans un environnement afin de maximiser certains types de récompense cumulative. Au cours de diverses expérimentations, l’ordinateur apprend plusieurs modèles de jeu et, dans un jeu, il peut utiliser le modèle optimal pour maximiser sa récompense.
Un exemple bien connu est Alpha Go, l’Alpha Go a battu le meilleur joueur d’échecs humain. Récemment, l’apprentissage par renforcement a également été appliqué aux enchères en temps réel.
7. Réseau neuronal
Les réseaux neuronaux sont des systèmes informatiques inspirés par les réseaux neuronaux biologiques qui constituent le cerveau des animaux. Tout comme dans le cerveau, où les neurones s’interconnectent et forment un réseau, les réseaux de neurones artificiels (ANN) sont constitués de nombreuses couches. Chaque couche est un assemblage d’une série de neurones. Un ANN peut traiter des données de manière consécutive, ce qui signifie que seule la première couche est connectée aux entrées, mais avec l’augmentation du nombre de couches, un ANN devient plus compliqué. Lorsque les couches deviennent très grandes, le modèle devient un modèle d’apprentissage profond. Il est difficile de définir un réseau ANN avec un certain nombre de couches. Il y a 10 ans, les ANN avec seulement 3 couches étaient assez profonds, maintenant nous avons généralement besoin de 20 couches.
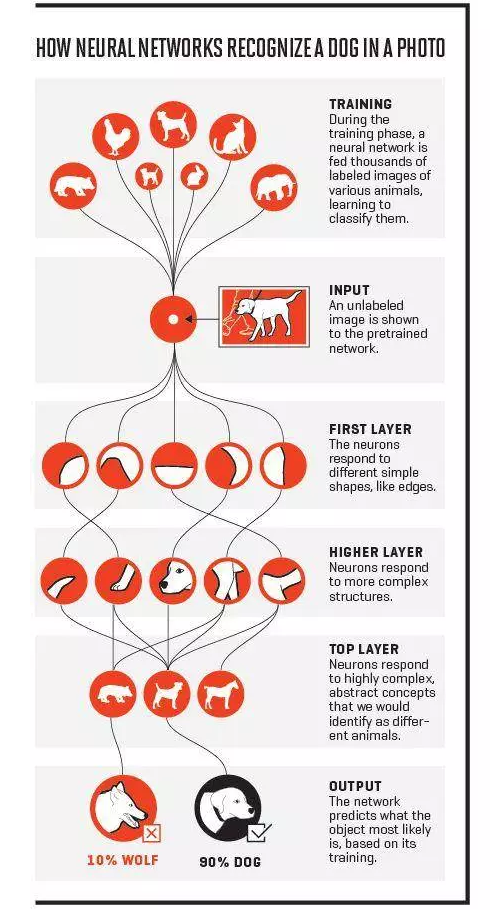
- Réseau neuronal convolutif – il a permis de grandes avancées dans le domaine de la vision par ordinateur.
- Réseau de neurones récurrents- créé pour traiter des données avec des caractéristiques de séquence, comme du texte et des cours de bourse.
- Couche entièrement connecté- c’est le modèle le plus simple utilisé pour traiter des données statiques/tabulaires.
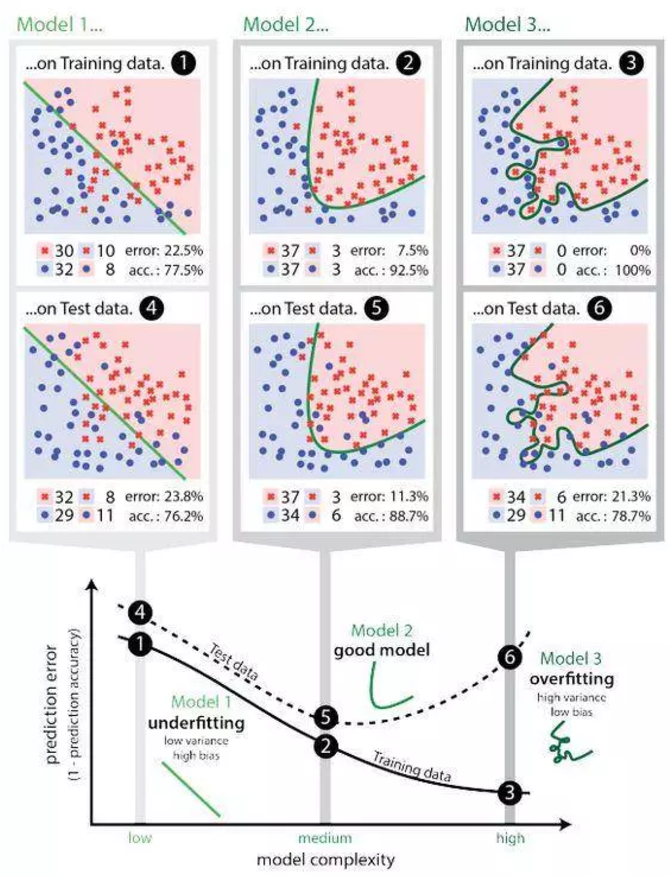
8. Surajustement(Overfitting)
L’overfitting est “la production d’une analyse qui correspond trop étroitement ou exactement à un ensemble particulier de données, et peut donc échouer à s’adapter à des données supplémentaires ou à prédire des observations futures de manière fiable”. En d’autres termes, lorsqu’un modèle apprend à partir de données insuffisantes, une déviation se produit, ce qui peut avoir un effet négatif sur le modèle.
Il s’agit d’un problème courant mais critique.
Lorsque l’ajustement excessif se produit, cela signifie généralement que le modèle prend des bruits aléatoires comme entrée de données, et les considère comme un signal important à ajuster, et c’est pourquoi le modèle peut se comporter moins bien avec de nouvelles données (il y a aussi des déviations dans les bruits aléatoires). Cela se produit souvent dans certains modèles compliqués tels que les réseaux neuronaux ou les modèles de gradient d’accélération.