Vous cherchez à extraire des données TripAdvisor (notes, avis, tarifs concurrents) mais vous ne savez pas par où commencer ? Ou vous avez déjà essayé : votre script Python s’est bloqué après 200 requêtes, votre extension Chrome ne dépasse plus la page 3, l’API officielle a rejeté votre candidature.
Dans les deux cas, le problème est le même : choisir la mauvaise méthode coûte plus cher que l’outil lui-même, en temps perdu, en données manquantes et en maintenance non prévue.
Pourquoi TripAdvisor est difficile à scraper
Pour choisir le bon outil, il est utile de comprendre d’abord pourquoi TripAdvisor résiste mieux aux scrapers que la plupart des plateformes de voyage. La plateforme combine quatre mécanismes de protection que requests + BeautifulSoup ne peuvent pas contourner.
- JavaScript challenge : pourquoi requests ne suffit plus
La plupart des pages TripAdvisor nécessitent l’exécution de JavaScript pour afficher leur contenu. Un appel HTTP simple renvoie une page vide ou un CAPTCHA. Un navigateur headless complet est indispensable.
- Browser fingerprinting : comment TripAdvisor identifie les bots
TripAdvisor génère une empreinte de chaque navigateur qui accède à la plateforme : user-agent, résolution d’écran, plugins installés, canvas fingerprint, comportement de la souris. Une session automatisée non configurée est détectée en quelques requêtes.
- Contenu dynamique : les données ne sont pas dans le HTML initial
Les avis, tarifs et classements sont chargés via des appels API asynchrones après le rendu initial de la page. Même avec un navigateur headless, il faut attendre le chargement complet des données avant d’extraire.
- CAPTCHA et rate limiting : le mur au-delà de 300 requêtes
Au-delà d’un certain rythme de requêtes, TripAdvisor déclenche des CAPTCHAs ou bloque temporairement l’IP. Les proxies datacenter sont inefficaces : la plateforme les identifie et les rejette. Seuls les proxies résidentiels donnent des résultats fiables à volume élevé.
Ce que ça implique concrètement : tout outil qui prétend scraper TripAdvisor via requests ou BeautifulSoup seul ne fonctionne plus en 2026. La vraie question n’est pas technique mais économique : quel est le coût total (développement + maintenance + proxies) par rapport à la valeur des données obtenues ? C’est ce que ce comparatif vous permet de calculer.
Comparatif des 3 méthodes : tableau de synthèse
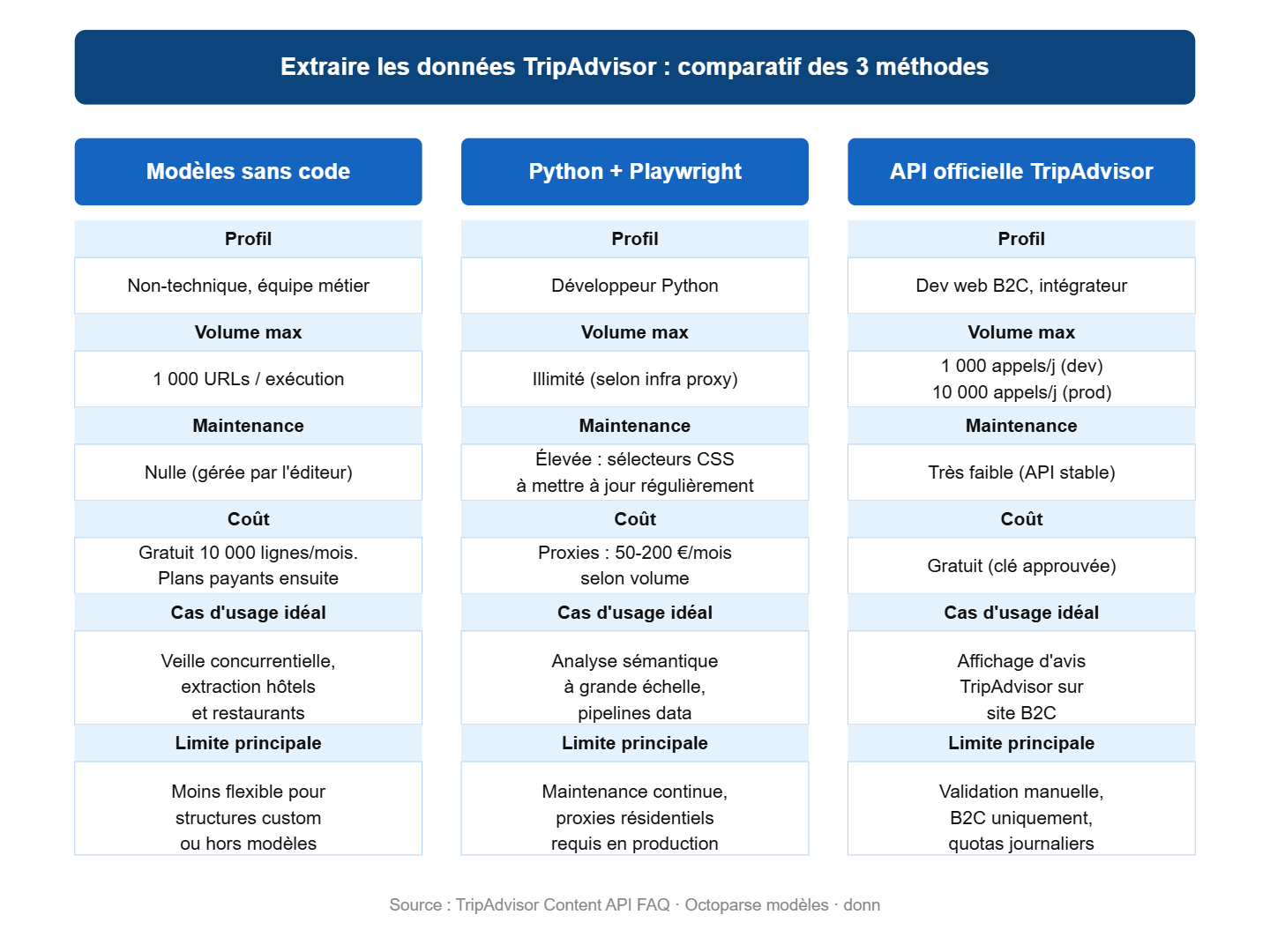
Voici la matrice de décision pour identifier la méthode adaptée à votre situation :

ALT : Matrice de décision scraper TripAdvisor 2026 : quelle méthode choisir selon votre situation, volume de données, besoin de maintenance et profil technique
Option 1 : les modèles sans code (profil non-technique, volume faible à moyen)
Les modèles d’extraction sans code sont la solution la plus rapide pour des équipes sans développeur. Aucune configuration, aucune maintenance de sélecteurs CSS, aucune gestion de proxy à prévoir.
Comment ça fonctionne
Un modèle préconfiguré pointe vers un type de page TripAdvisor précis (résultats hôtels, listing restaurants, fiche détail). Vous fournissez les URLs cibles, l’outil gère l’exécution dans le cloud, contourne les protections anti-bots, et vous livre les données en CSV ou Excel. Si TripAdvisor modifie la structure de ses pages, c’est l’éditeur qui met à jour les sélecteurs, pas vous.
C’est l’approche la plus directe pour l’extraction d’avis TripAdvisor à grande échelle, sans avoir à configurer un data extractor TripAdvisor sur mesure.
Les 3 modèles TripAdvisor disponibles
Trois modèles couvrent les cas d’usage les plus courants. Choisissez celui qui correspond à votre cible.
TripAdvisor Hotel Info Scraper
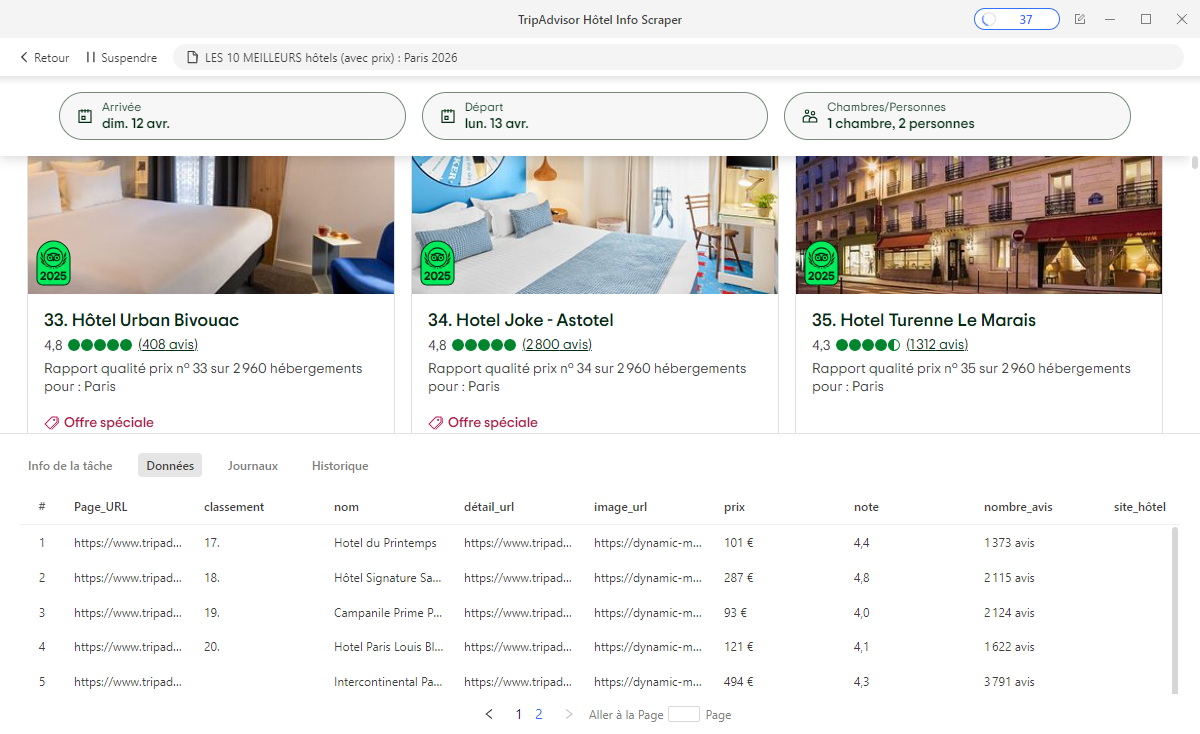
Extrait les données hôtelières depuis les pages de résultats TripAdvisor : classement, nom, note globale, sous-notes, prix affiché, nombre d’avis, URL de fiche détail. Jusqu’à 1 000 URLs par exécution, sans frais sur le plan gratuit.
https://www.octoparse.fr/template/tripadvisor-hotel-info-scraper
Le plan gratuit permet jusqu’à 10 000 lignes de données par mois et jusqu’à 1 000 URLs par exécution. Pour des volumes supérieurs ou une exécution cloud planifiée, des plans payants prennent le relais. Un essai de 14 jours sur les fonctionnalités cloud est inclus sans engagement.
TripAdvisor Restaurant Scraper (listing)
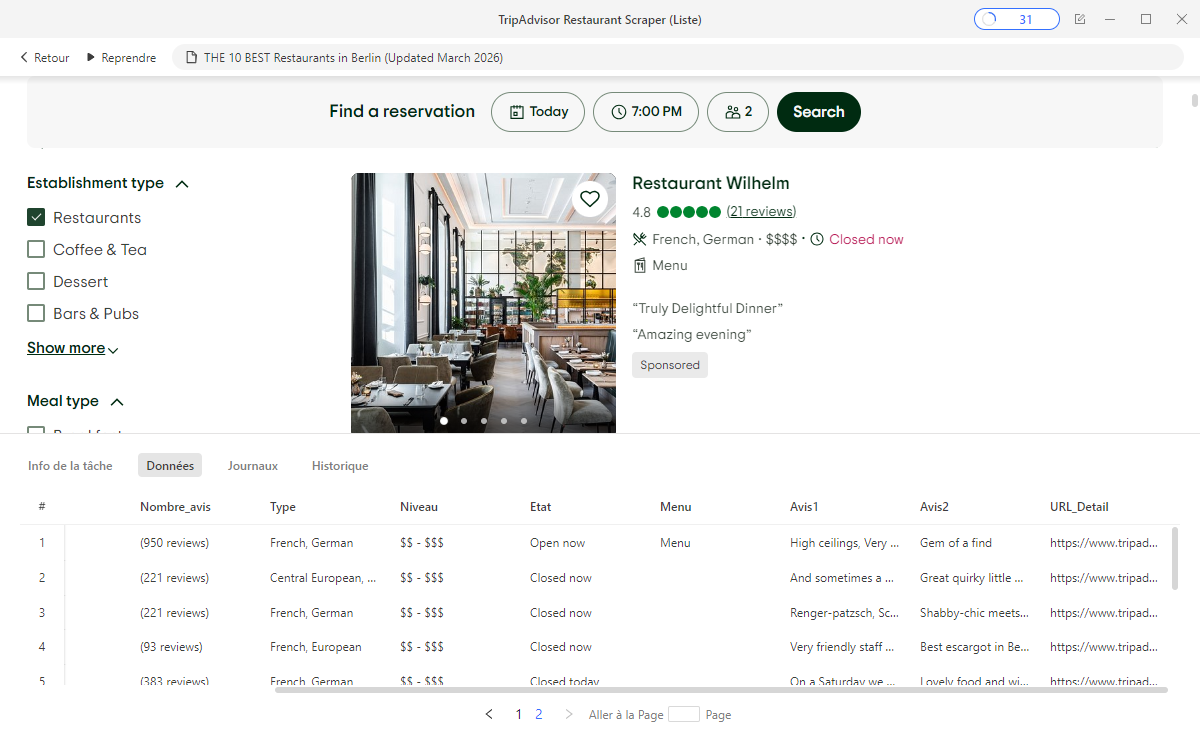
Cible les pages de résultats de restaurants : nom, note, type de cuisine, fourchette de prix, URL de fiche. Adapté pour constituer rapidement une base de données de restaurants sur une destination.
https://www.octoparse.fr/template/tripadvisor-restaurant-scraper-listing
TripAdvisor Restaurant Scraper (fiche détail)

Entre dans chaque fiche restaurant pour extraire les données complètes : coordonnées, horaires, avis clients, équipements, informations de contact. Utile pour enrichir une base de données restauration sur une zone géographique.
https://www.octoparse.fr/template/tripadvisor-restaurant-scraper-detail

Modèles hôtels et restaurants préconfigurés : prêts en 3 clics, sans paramétrage ni code.
Gestion native des protections anti-bots : JavaScript challenge, browser fingerprinting, CAPTCHA, rotation d’IP.
Export vers Excel, CSV, Google Sheets ou directement dans votre base de données.
Exécution cloud planifiable : vos données arrivent automatiquement selon votre fréquence, sans intervention manuelle.
Auto-détection de la structure des pages pour les établissements hors modèles standards.
Ce que cette méthode ne couvre pas
Les modèles sont optimisés pour les structures de pages les plus courantes. Pour des besoins très spécifiques (pages de destination sans template, formats de données personnalisés, intégration directe dans un pipeline de données), Python ou l’API seront plus adaptés. Si vous hésitez entre les deux, la matrice de décision ci-dessus permet de trancher en moins d’une minute.
Option 2 : Python + Playwright (profil développeur, volume élevé)
Vous avez un développeur dans votre équipe, ou vous êtes vous-même à l’aise avec Python ? C’est la méthode à privilégier.
Pour les équipes avec un profil technique et des besoins de volume supérieurs à 10 000 établissements, Python avec Playwright est la solution la plus flexible. Elle demande plus de temps de configuration initiale, mais offre un contrôle total sur les données extraites.
Pourquoi Playwright plutôt que Selenium en 2026
Selenium reste utilisable mais présente des signaux d’automatisation que TripAdvisor détecte facilement (flag navigator.webdriver, comportement headless reconnaissable). Playwright avec un mode stealth est plus difficile à identifier. La bibliothèque puppeteer-extra-stealth a été abandonnée en février 2025, ce qui laisse Playwright et SeleniumBase UC Mode comme alternatives principales.
Structure de base d’un scraper TripAdvisor avec Playwright
Les sélecteurs CSS TripAdvisor (classes générées dynamiquement) changent régulièrement. La méthode la plus robuste consiste à intercepter les appels API réseau via page.on(“response”) plutôt que de cibler des attributs HTML instables. Un guide technique complet avec les sélecteurs validés est disponible dans le guide de scraping TripAdvisor.
Les limites réelles de Python en production
En production, quatre problèmes reviennent systématiquement :
- Sélecteurs CSS instables : TripAdvisor modifie régulièrement ses classes CSS. Un script fonctionnel aujourd’hui peut être cassé dans 2 à 6 semaines. Prévoyez du temps de maintenance récurrent.
- Proxies résidentiels obligatoires au-delà de quelques centaines de requêtes : les proxies datacenter classiques sont bloqués. Les services résidentiels coûtent entre 50 et 200 €/mois selon le volume.
Les fournisseurs accessibles depuis la France avec facturation en euros : Bright Data (plans à partir de 500 Go/mois, tarification à la consommation), Oxylabs (réseau résidentiel, à partir de 15 $/Go), IPRoyal (proxies résidentiels rotatifs, à partir de 3 $/Go). Pour des volumes modérés (moins de 10 000 requêtes/mois), les proxies datacenter de OVHcloud suffisent si TripAdvisor ne les a pas encore bloqués sur votre plage IP.
- Gestion des CAPTCHAs : même avec Playwright stealth, des CAPTCHAs apparaissent au-delà d’un certain rythme. Des services de résolution automatique (2Captcha, CapSolver) sont nécessaires pour une production stable.
- Comportement humain à simuler : TripAdvisor utilise en 2026 des modèles de machine learning pour détecter les patterns d’automatisation. Des pauses aléatoires, des mouvements de souris simulés et une navigation non-linéaire réduisent le taux de blocage.
Coût réel d’un scraper Python TripAdvisor en production : comptez 3 à 5 jours de développement initial, puis 2 à 4 heures de maintenance mensuelle pour adapter les sélecteurs aux changements de TripAdvisor. À cela s’ajoutent les coûts de proxies résidentiels selon votre volume.
Option 3 : la TripAdvisor Content API, gratuite et stable, mais réservée aux sites B2C
Parmi les trois méthodes, la TripAdvisor Content API est la seule dont l’usage est encadré par un accord contractuel direct avec TripAdvisor, ce qui la rend techniquement stable et juridiquement claire pour les sites B2C approuvés. Elle est conçue pour un cas d’usage précis : afficher des avis et notations TripAdvisor sur un site web grand public. Si ce n’est pas votre cas d’usage, les options 1 ou 2 seront plus adaptées.
Ce que la TripAdvisor Content API permet d’extraire
La TripAdvisor Content API donne accès aux données suivantes via des appels HTTP structurés :
- Informations sur les établissements : nom, adresse, coordonnées GPS, catégorie, photos
- Notes et avis : note globale, sous-notes, et avis clients via pagination (jusqu’à 100 avis par appel, limit + offset)
- Recherche géographique : établissements autour d’une coordonnée GPS, dans un rayon défini
- Disponible dans 29 langues, données actualisées en temps réel
Les limites que la documentation officielle mentionne peu
| Limite | Détail |
| Quota développement | 1 000 appels/jour pendant la phase de test |
| Quota production | 10 000 appels/jour après validation manuelle du site |
| Avis par requête | 100 avis maximum par appel, navigation par pagination (limit + offset) |
| Accès à l’historique | Limité aux avis récents ; l’export complet de l’historique n’est pas prévu par l’API |
| Restriction B2C | Réservé aux sites grand public uniquement. Usage B2B refusé. |
| Validation manuelle | TripAdvisor examine chaque candidature. Délai : 2 à 6 semaines. |
| Logo obligatoire | Affichage du logo TripAdvisor et lien retour vers la fiche établissement requis. |
| Pas de veille concurrentielle | L’API ne permet pas d’extraire les données à des fins de comparaison ou d’analyse de marché. |
Comment obtenir une clé API TripAdvisor
- Rendez-vous sur le portail développeurs TripAdvisor : developer-tripadvisor.com/content-api/
- Créez un compte et remplissez le formulaire de candidature en détaillant précisément votre cas d’usage. Les candidatures vagues sont refusées.
- TripAdvisor examine votre site, votre volume de trafic et la pertinence de l’intégration. Les projets orientés consommateurs ont plus de chances d’être approuvés.
- Une clé de développement (1 000 appels/jour) est fournie pour les tests. La clé production (10 000 appels/jour) est débloquée après validation de votre intégration.
Pour tester l’API avant de faire votre candidature, un exemple d’appel complet en Python :
Pour la veille concurrentielle, l’analyse de marché ou l’extraction en masse d’avis TripAdvisor, l’API officielle n’est pas adaptée. Les modèles sans code ou Python couvrent ces besoins sans les contraintes de candidature et de limitation de volume.
Légalité du scraping TripAdvisor en France
La légalité du scraping est souvent mal comprise, y compris par des équipes qui l’utilisent au quotidien. Voici la situation juridique en France, telle qu’elle se présente en 2026.
Ce qui est légal
L’extraction de données publiques accessibles sans authentification est légale en France, dans le cadre fixé par le RGPD et les recommandations de la CNIL sur la collecte de données publiques en ligne. La jurisprudence européenne (arrêt Ryanair vs PR Aviation, CJUE 2015) a confirmé que les données publiques peuvent être extraites à condition de respecter les droits des bases de données.
- Les données publiques TripAdvisor (notes, avis, tarifs affichés, classements) peuvent être extraites automatiquement.
- L’extraction à des fins de veille concurrentielle, d’analyse de marché ou de recherche est couverte.
- Le fichier robots.txt de TripAdvisor indique les sections non souhaitées : le respecter réduit les risques de litige.
Ce qui est interdit
- Contourner des mesures techniques de protection expressément mises en place pour bloquer l’accès (art. L122-6-2 CPI).
- Extraire des données personnelles identifiables (profils d’utilisateurs, emails) sans base légale RGPD.
- Revente des données TripAdvisor ou utilisation commerciale contraire aux CGU.
- Usage de l’API officielle pour des finalités non autorisées par TripAdvisor.
Depuis le 17 février 2024, le DSA (Digital Services Act) oblige TripAdvisor à publier des rapports de transparence sur la modération de ses contenus. En France, l’Arcom supervise le respect du DSA. La DGCCRF reste compétente pour les pratiques commerciales liées aux avis (faux avis, pratiques trompeuses).
FAQ : questions fréquentes sur les scrapers TripAdvisor
- Est-ce légal de scraper TripAdvisor ?
Oui, pour les données publiques (notes, avis, tarifs affichés, classements) dans le cadre des recommandations CNIL et du RGPD. Respectez le fichier robots.txt et n’extrayez pas de données personnelles identifiables sans base légale. L’usage de l’API officielle est soumis à validation et aux CGU TripAdvisor.
Deux précisions utiles pour les équipes françaises : les tribunaux français ont déjà sanctionné des pratiques de collecte de données issues de plateformes d’avis lorsqu’elles impliquaient des données personnelles sans base légale RGPD. La distinction à retenir : les notes et classements agrégés ne sont pas des données personnelles ; les profils d’utilisateurs nommément identifiables y sont soumis et nécessitent une base légale explicite. Par ailleurs, la DGCCRF surveille activement ce secteur depuis 2024, en lien avec le DSA. Un avis juridique est recommandé pour tout usage commercial à grande échelle.
- Combien coûte l’API TripAdvisor ?
La TripAdvisor Content API est gratuite, mais l’accès est soumis à validation manuelle par TripAdvisor. Seuls les sites B2C qualifiés obtiennent une clé. Le quota est de 1 000 appels/jour en phase de développement et 10 000 appels/jour après validation de la production.
Pour les besoins de veille ou d’analyse de marché non couverts par l’API officielle, les modèles sans code sont disponibles gratuitement jusqu’à 10 000 lignes/mois.
- Python + requests suffit-il pour scraper TripAdvisor ?
Non. En 2026, TripAdvisor utilise du contenu chargé dynamiquement (JavaScript), du browser fingerprinting et des CAPTCHA qui bloquent systématiquement les appels HTTP simples via requests ou urllib. Un navigateur headless avec configuration anti-détection (Playwright ou SeleniumBase UC Mode) est indispensable.
- Quelle est la meilleure alternative à Python pour scraper TripAdvisor sans coder ?
Les modèles sans code préconfigurés pour TripAdvisor (hôtels, restaurants listing, fiche détail) permettent d’extraire les données en 3 clics, sans gérer les protections anti-bots. L’exécution cloud automatise la récurrence. C’est la solution la plus rapide pour des équipes sans développeur.
- Comment automatiser l’extraction régulière des données TripAdvisor (veille hebdomadaire) ?
Pour une veille concurrentielle automatisée, deux niveaux selon votre profil. Sans code : les modèles en mode cloud permettent de planifier une extraction quotidienne ou hebdomadaire avec livraison directe en CSV ou dans votre outil d’analyse. Avec Python : configurez un cron job ou un orchestrateur (Airflow, Prefect) pour déclencher votre script selon votre fréquence cible. Le mode cloud évite de gérer l’infrastructure serveur et la rotation IP. Pour la restauration ou l’hôtellerie, une extraction hebdomadaire suffit généralement pour détecter les mouvements de classement significatifs.
- Les modèles TripAdvisor fonctionnent-ils toujours si le site change de structure ?
Oui. Les modèles sont maintenus et mis à jour par l’équipe technique en cas de changement de structure côté TripAdvisor. C’est l’avantage concret par rapport à un script maison : la maintenance des sélecteurs est prise en charge par l’éditeur, sans action requise de votre part.
- Scraper TripAdvisor est-il utilisé en France par des professionnels ?
Oui, principalement par trois profils : les revenue managers d’hôtels qui suivent les tarifs concurrents, les équipes marketing qui analysent les avis à grande échelle, et les agences de développement touristique qui constituent des bases de données d’établissements par destination. L’extraction de données TripAdvisor est désormais intégrée aux pratiques courantes de veille et d’analyse dans le secteur hôtellerie-restauration.
En résumé : quelle méthode choisir ?
Le choix dépend d’un seul critère : ce que vous avez en interne.
- Vous n’avez pas de développeur et vous avez besoin de données rapidement : les modèles sans code TripAdvisor. Prêts en 3 clics, zéro maintenance, exécution cloud planifiable. Adapté pour la veille concurrentielle hôtels et restaurants jusqu’à quelques milliers d’établissements.
- Vous avez un profil technique et des besoins de volume élevé ou des cas d’usage spécifiques hors modèles : Python avec Playwright. Flexibilité maximale, mais prévoyez du temps de maintenance et un budget proxies résidentiels.
- Vous construisez un site B2C et voulez afficher des avis TripAdvisor officiellement : l’API officielle TripAdvisor Content API. Gratuite, stable, mais accès soumis à validation manuelle et réservé aux sites B2C.
Si vos données sont extraites et que vous cherchez maintenant à les exploiter (comprendre l’algorithme de classement, analyser vos avis, structurer votre veille), l’article sur les données TripAdvisor couvre ces points avec les cas d’usage par secteur.
Pour les scripts Python complets, la gestion des proxies et des configurations anti-bots testées en production, le guide de scraping TripAdvisor couvre les implémentations complètes, proxies inclus, avec les points de blocage à anticiper.



