Avec plus d’un milliard d’avis répartis sur 8 millions d’établissements dans le monde, TripAdvisor est devenu la référence incontournable pour les données hôtelières, les avis clients et les comparatifs de prix dans le secteur du voyage. Pour les équipes qui travaillent dans l’hôtellerie, la restauration ou le tourisme (chargés de revenue management, responsables marketing, analystes data), y accéder manuellement représente un frein opérationnel réel : copier-coller des centaines d’avis un à un, relever des tarifs concurrents page par page, suivre sa e-réputation sans outil dédié alors que les avis s’accumulent chaque jour.
Ce guide présente trois méthodes concrètes de scraping TripAdvisor pour automatiser cette collecte, avec des exemples de code fonctionnels et des modèles prêts à l’emploi, selon votre niveau technique.
TripAdvisor autorise-t-il le scraping ? Ce que dit la CNIL
La question revient systématiquement avant de se lancer, et la réponse mérite d’être précise. Oui, le scraping de données publiques sur TripAdvisor est légal en France, à condition de respecter un cadre strict. La CNIL a publié le 19 juin 2025 deux fiches pratiques encadrant le recours au web scraping, initialement dans le contexte de l’IA. Elle y confirme que l’intérêt légitime (article 6.1.f du RGPD) peut constituer une base légale pour la collecte de données publiquement accessibles, à condition de respecter le principe de minimisation, d’exclure les données sensibles et de tenir compte des restrictions techniques du site (robots.txt, CGU). Ces principes encadrent plus largement toute collecte automatisée de données publiques : même dans un contexte commercial, l’intérêt légitime peut être invoqué dès lors que les conditions de minimisation, d’exclusion des données sensibles et de respect des restrictions techniques sont respectées.
Ce que vous pouvez scraper légalement
TripAdvisor rend publiques de nombreuses données directement exploitables :
- Noms, adresses et coordonnées d’établissements (hôtels, restaurants, campings)
- Notes globales et sous-notes (propreté, service, rapport qualité/prix, localisation)
- Texte intégral des avis clients, date et langue de publication
- Prix indicatifs affichés sur les pages de résultats
- Photos, classements, URL de fiches établissement
Ce que vous ne pouvez pas faire
- Collecter des données personnelles identifiables sans base légale valide (noms d’utilisateurs pseudonymisés en lien avec des données réelles, emails)
- Contourner des protections techniques (CAPTCHA, authentification) : cela constitue une infraction pénale en France, passible de sanctions au titre de l’article 323-1 du Code pénal
- Réutiliser ou revendre une portion substantielle de la base de données TripAdvisor (protection du droit sui generis, art. L341-1 du CPI)
- Enfreindre les CGU de TripAdvisor, qui interdisent explicitement l’extraction automatique à des fins commerciales sans autorisation préalable
Respecter le fichier robots.txt de TripAdvisor va au-delà de la bonne pratique technique : la CNIL en fait une condition explicite pour que le traitement reste dans les attentes raisonnables des personnes concernées.
Quelles données peut-on récupérer sur TripAdvisor ?
TripAdvisor couvre plus de 40 catégories d’établissements. Voici les principaux types de données TripAdvisor à récupérer, avec leurs cas d’usage concrets pour les équipes françaises.
Données hôtelières
- Nom, adresse, catégorie étoiles, équipements disponibles
- Note globale et sous-notes détaillées (propreté, service, localisation, rapport qualité/prix)
- Tarifs affichés et comparaisons concurrentielles
- Photos, URL de fiche détail, coordonnées de contact, site web de l’établissement
Cas d’usage typiques : veille sur les prix hôtels TripAdvisor pour les équipes revenue management, benchmarking multi-destinations, enrichissement de bases CRM avec des données de marché actualisées.
La veille concurrentielle TripAdvisor est d’autant plus efficace lorsque l’extraction est automatisée et récurrente : les tarifs évoluent fréquemment et une capture hebdomadaire suffit généralement à détecter les mouvements de prix des concurrents directs.
En France, des groupes comme Accor, B&B Hotels ou Logis de France utilisent déjà des outils d’agrégation de données pour piloter leur positionnement tarifaire sur TripAdvisor par rapport aux indépendants locaux.
Avis clients
- Texte intégral de l’avis, note attribuée, date de publication
- Langue de rédaction, profil du voyageur (solo, famille, couple, affaires)
- Réponses de la direction (précieuses pour analyser la gestion de la e-réputation concurrentielle)
Cas d’usage typiques : analyse sémantique de la satisfaction client, détection automatisée des points de friction, pilotage de la e-réputation sur plusieurs établissements simultanément.
Sur le volet e-réputation, les données d’avis TripAdvisor servent aussi à repérer les signaux négatifs avant qu’ils ne se traduisent par une perte de classement : un enjeu particulièrement concret pour les groupes hôteliers qui gèrent plusieurs établissements simultanément.
Restaurants et campings
- Restaurants : type de cuisine, fourchette de prix, horaires d’ouverture, nombre d’avis, note globale
- Campings : type d’hébergement, équipements, saisonnalité. Catégorie particulièrement dynamique en France, premier pays européen en capacité d’hébergement de plein air avec 7 460 campings aménagés et 140 millions de nuitées enregistrées en 2024 selon l’INSEE
Cas d’usage typiques : construction de comparateurs locaux, guides touristiques territoriaux, études de marché pour acteurs du tourisme.
Données de vols et activités
- Tarifs indicatifs de vols affichés via TripAdvisor
- Activités, excursions et attractions touristiques (notes, fourchette de prix, disponibilité)
Cas d’usage typiques : agences de voyages en ligne souhaitant enrichir leurs comparateurs, études de destination pour décideurs tourisme, veille sur les tendances d’attractivité régionale.
Les défis techniques du scraping TripAdvisor : pourquoi ça bloque (et comment y remédier)
TripAdvisor est l’un des sites les plus protégés du secteur touristique. Si vous lancez une requête requests.get() directement en Python, vous obtiendrez soit une page vide, soit un blocage immédiat. Comprendre les mécanismes en place vous évitera des heures de débogage inutiles.
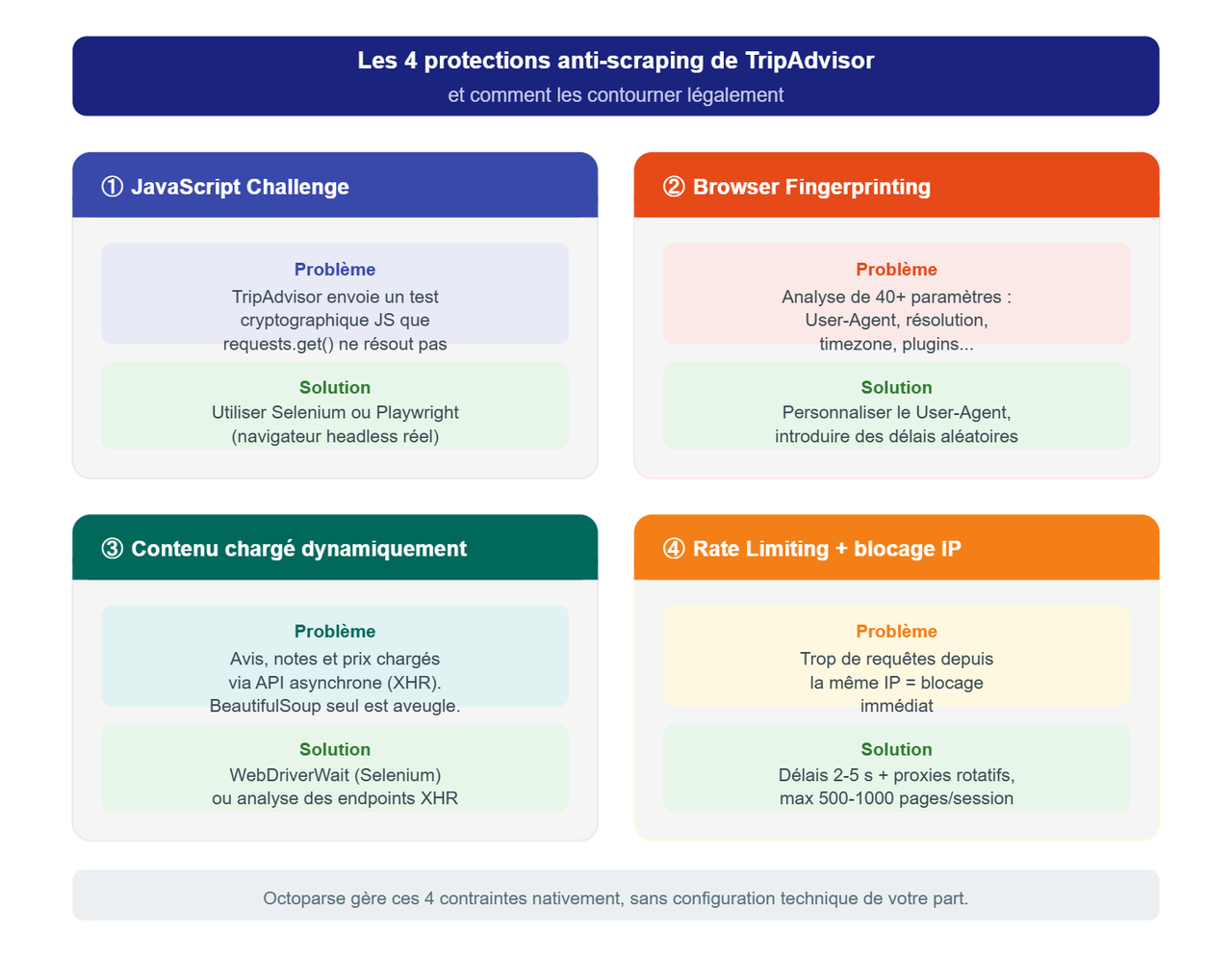
- JavaScript Challenge
Lorsqu’une requête lui paraît suspecte, TripAdvisor envoie à votre client un challenge cryptographique JavaScript qu’un vrai navigateur doit résoudre avant d’accéder au contenu. Un script Python classique échoue systématiquement à cette étape. Solution : utiliser Selenium ou Playwright, qui pilotent un vrai navigateur et résolvent ces challenges automatiquement.
- Browser Fingerprinting
TripAdvisor analyse en temps réel des dizaines de paramètres de votre session : version du moteur de rendu, résolution d’écran, polices installées, timezone, patterns de navigation. Un navigateur headless mal configuré est instantanément identifiable. Solution : personnaliser le User-Agent, désactiver les flags de détection d’automatisation de Selenium, et introduire des comportements aléatoires (pauses variables entre les requêtes, simulation de scroll).
- Contenu chargé dynamiquement
La majorité des données TripAdvisor (avis, notes, prix) sont chargées via des appels API asynchrones après le rendu initial de la page. BeautifulSoup seul ne les capturera pas. Solution : attendre le chargement complet via WebDriverWait de Selenium, ou, pour les développeurs expérimentés, analyser les requêtes XHR via les outils de développement du navigateur pour identifier les endpoints de données non protégés
- Rate limiting et blocage d’IP
Au-delà d’un certain volume de requêtes depuis la même adresse IP, TripAdvisor déclenche un blocage. Solution : introduire des délais aléatoires entre les requêtes (2 à 5 secondes), limiter le volume à 500-1 000 pages par session, et utiliser des proxies résidentiels rotatifs pour les extractions à grande échelle.
Pour les équipes sans profil technique, ces quatre points sont gérés automatiquement par des outils comme Octoparse, qui intègre nativement le rendu JavaScript, la rotation d’IP, la gestion des CAPTCHA et la planification cloud.
Méthode 1 : scraper TripAdvisor sans code avec les modèles Octoparse
Octoparse est un outil de web scraping no-code utilisé par plus de 3 millions d’utilisateurs dans le monde. La bibliothèque de modèles prêts à l’emploi couvre TripAdvisor avec plusieurs extracteurs spécialisés, selon que vous ciblez des hôtels ou des restaurants, chacun maintenu à jour par l’équipe technique.
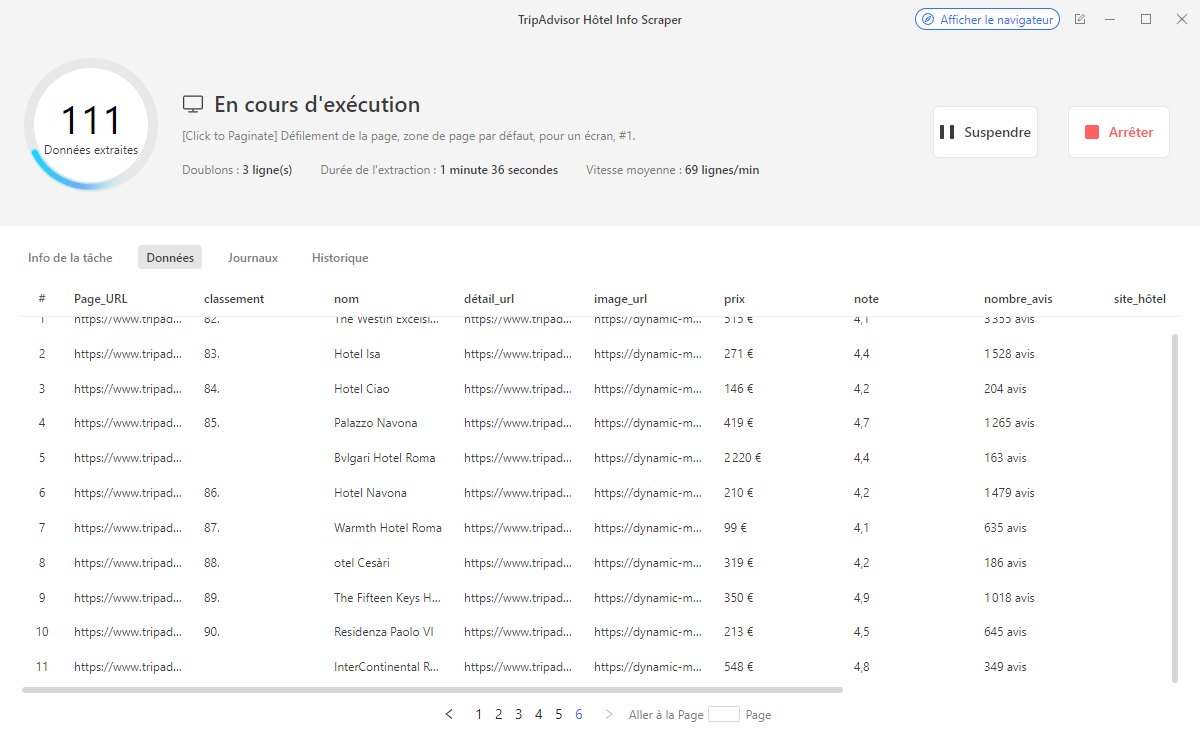
Modèle 1 : TripAdvisor Hôtel Info Scraper
Ce modèle extrait les informations hôtelières à partir des URLs de pages de résultats TripAdvisor. Pour chaque hôtel identifié, vous récupérez : classement, nom, URL de la fiche détail, image, prix, note, nombre d’avis, site officiel et un extrait de commentaire client. Jusqu’à 1 000 URLs en entrée par exécution, sans frais.
https://www.octoparse.fr/template/tripadvisor-hotel-info-scraper
Comment l’utiliser :
Étape 1 : cliquer sur « Essayez-le ! »
Étape 2 : saisir vos URLs TripAdvisor (jusqu’à 1 000 par exécution)
Étape 3 : cliquer sur « Exécuter » et sélectionner le mode d’exécution. Export disponible en Excel, CSV ou JSON.
Voici un aperçu des données extraites sur une page de résultats hôtels TripAdvisor : chaque ligne correspond à un établissement, avec son classement, sa note, son prix affiché et l’URL directe vers sa fiche détail.
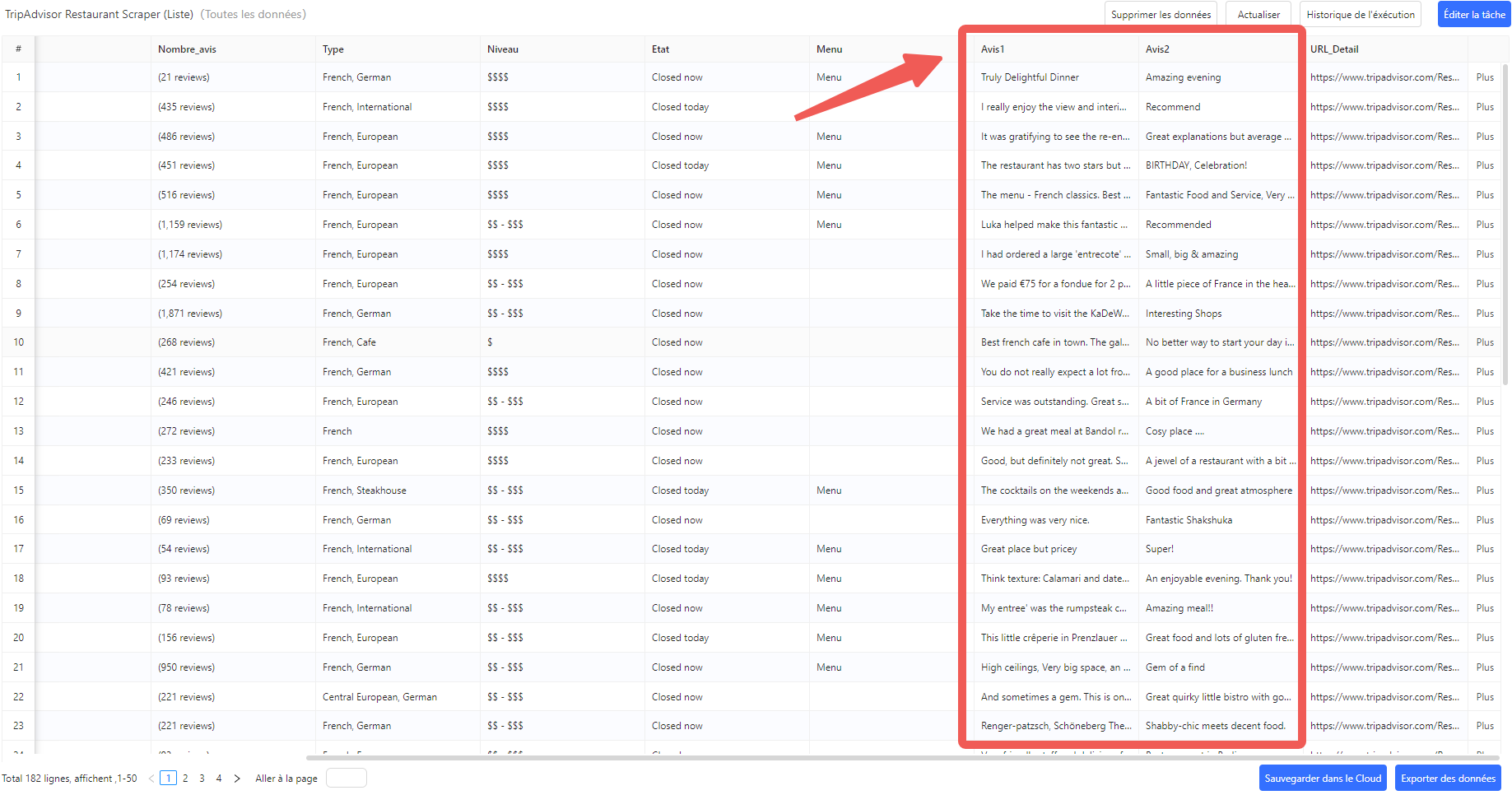
Modèle 2 : TripAdvisor Restaurant Scraper (Liste)
Ce modèle cible les pages de résultats de restaurants (listing) pour extraire en une fois les données de plusieurs établissements : nom, note, catégorie de cuisine, fourchette de prix, URL de fiche détail.
https://www.octoparse.fr/template/tripadvisor-restaurant-scraper-listing
Sur une page de résultats restaurants, le modèle capture en une seule exécution le nom de chaque établissement, sa note, la catégorie de cuisine proposée, la fourchette de prix et le lien vers sa fiche complète.
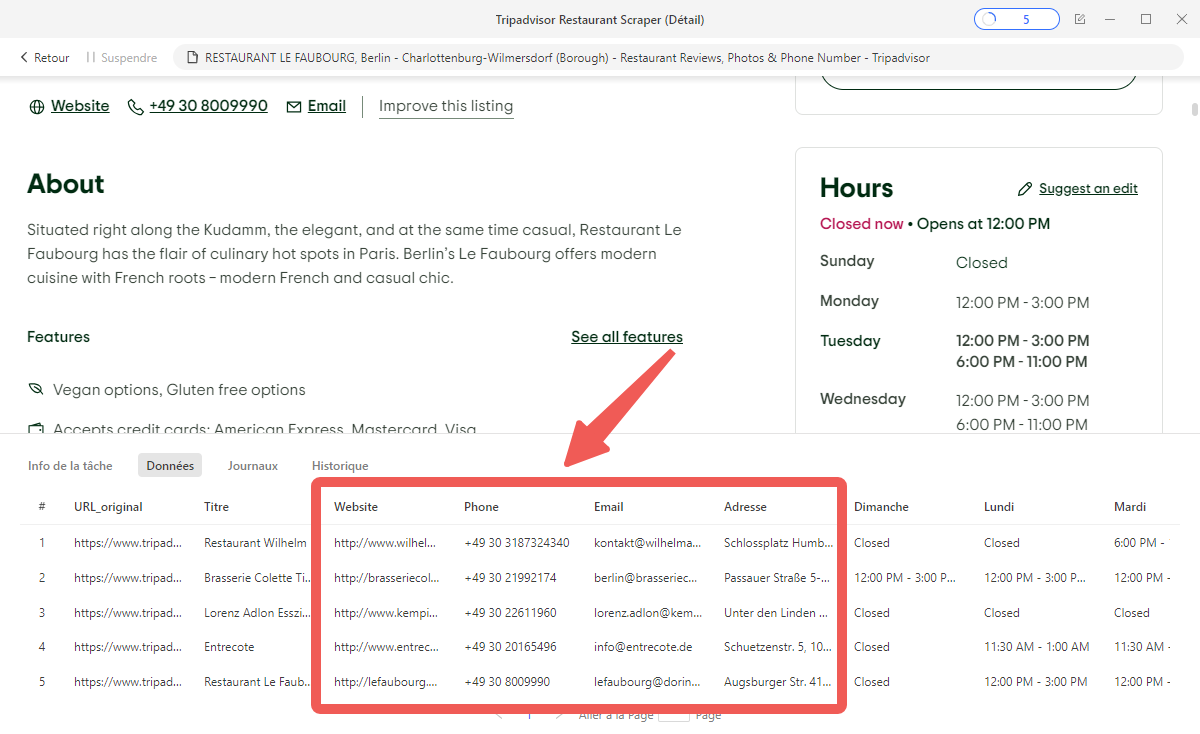
Modèle 3 : Tripadvisor Restaurant Scraper (Détail)
Ce modèle entre dans la fiche individuelle de chaque restaurant pour extraire le détail complet : coordonnées, horaires, avis, équipements, photos et données de contact.
https://www.octoparse.fr/template/tripadvisor-restaurant-scraper-detail
En ciblant directement la fiche d’un restaurant, le modèle va chercher les informations complètes : coordonnées, horaires d’ouverture, avis clients, équipements et données de contact. Utile pour constituer une base de données restauration enrichie sur une ville ou une région.

Modèles TripAdvisor prêts à l’emploi pour hôtels et restaurants, sans configuration.
Gestion native des protections anti-bots : JavaScript, fingerprinting, CAPTCHA, rotation d’IP.
Export direct en Excel, CSV, Google Sheets ou vers une base de données.
Exécution cloud planifiable pour automatiser vos extractions sans intervention manuelle.
Auto-détection de la structure des pages pour les sites non couverts par les modèles.
Pourquoi utiliser les modèles Octoparse plutôt que de scraper manuellement ? Les sélecteurs CSS de TripAdvisor évoluent régulièrement : chaque mise à jour du site peut casser un script maison. Les modèles Octoparse sont maintenus et mis à jour par l’équipe technique, ce qui vous libère de toute maintenance.
Un plan gratuit à vie est disponible pour tester les modèles, avec un essai de 14 jours sur les fonctionnalités avancées (exécution cloud, planification). Compatible Windows et macOS.
Méthode 2 : scraper TripAdvisor avec Python (Selenium + BeautifulSoup)
Pour les développeurs qui souhaitent garder la main sur leur pipeline de données, Python reste la méthode la plus flexible. Point critique à retenir avant de commencer : une requête requests.get() standard sera bloquée systématiquement par TripAdvisor (contenu dynamique + anti-bots). Il vous faut obligatoirement un navigateur headless.
Prérequis : installation des dépendances
Script : extraction des données hôtelières TripAdvisor à Paris
Pour ceux qui préfèrent coder leur propre tripadvisor scraper en Python, voici un script complet qui contourne les protections anti-bots de TripAdvisor via Selenium, et extrait les données avec BeautifulSoup. L’exemple ci-dessous cible les hôtels parisiens, mais la logique est identique pour scraper les avis TripAdvisor avec Python sur n’importe quelle destination.
Points d’attention avant de déployer
- Sélecteurs CSS évolutifs : TripAdvisor met à jour sa structure HTML régulièrement. Vérifiez les attributs avec l’outil Inspect de votre navigateur avant chaque exécution en production.
- Délais obligatoires : respectez 2 à 5 secondes entre les requêtes. En dessous, le risque de blocage d’IP devient très élevé.
- Volume important (> 500 pages) : intégrez des proxies résidentiels rotatifs pour éviter les bans d’IP.
- Conformité : ce script est fourni à titre pédagogique. Assurez-vous de respecter les CGU de TripAdvisor et le cadre RGPD pour votre usage spécifique.
Le script ci-dessus convient pour des extractions ponctuelles ou des tests. Pour des volumes plus importants ou des extractions planifiées sur plusieurs destinations, d’autres options existent : un comparatif des principales solutions est disponible dans cet article dédié.
Méthode 3 : API officielle TripAdvisor (Content API)
TripAdvisor propose une Content API officielle accessible via le portail développeurs. Cette option convient aux agences de voyage, comparateurs hôteliers et développeurs d’applications B2C souhaitant intégrer des données TripAdvisor de manière contractuelle et stable.
Ce que l’API permet
- Détails d’établissements : nom, adresse, catégorie, note globale, URL de fiche
- Photos haute qualité associées à chaque lieu
- Avis récents en accès direct
- Recherche par localisation ou mot-clé
Les limites à connaître avant de vous lancer
L’API donne accès à un maximum de 3 avis et 2 photos par établissement, avec un quota journalier strict (1 000 appels en phase de développement, 10 000 après validation). En pratique, récupérer plusieurs centaines d’avis pour des dizaines d’établissements consomme rapidement ce quota, ce qui la rend peu adaptée à la surveillance de e-réputation à grande échelle ou au benchmarking multi-destinations.
- Phase de développement : 1 000 appels/jour maximum
- Après validation : 10 000 appels/jour (les 5 000 premiers appels/mois sont gratuits)
- Accès soumis à validation manuelle par les équipes TripAdvisor (délai variable, pas de garantie d’approbation)
- Obligation d’afficher le logo TripAdvisor et des liens retour vers le site sur chaque page intégrant le contenu
- Réservée aux sites B2C : les projets B2B doivent s’orienter vers les programmes TripConnect
Pour quel usage ?
L’API officielle convient principalement si vous développez une application grand public qui affiche des évaluations TripAdvisor, ou si vous avez besoin d’un accès stable et contractuellement encadré à un volume limité de données. Pour les besoins d’analyse à grande échelle (veille concurrentielle, extraction de milliers d’avis, benchmarking multi-établissements), les Méthodes 1 et 2 seront systématiquement plus adaptées.
Pour soumettre une candidature et consulter la documentation technique, le portail développeurs TripAdvisor est accessible ici.
FAQ : questions fréquentes sur le scraping TripAdvisor
- Le scraping de TripAdvisor est-il légal en France ?
Oui, dans le respect du cadre établi par le RGPD et la fiche pratique CNIL de juin 2025 sur le web scraping. Vous pouvez extraire des données publiques non personnelles (notes, prix, descriptions d’établissements) en respectant les CGU et le fichier robots.txt. En revanche, contourner des protections techniques est passible de sanctions pénales en France (art. 323-1 du Code pénal). Un guide complet sur la légalité du scraping en France est disponible sur ce site si vous avez un doute sur votre usage spécifique.
- Comment extraire automatiquement les avis TripAdvisor ?
Deux approches selon votre profil : (1) sans code — utilisez les modèles Octoparse dédiés à TripAdvisor (hôtels et restaurants), entrez vos URLs et exportez en CSV ou Excel en quelques clics ; (2) avec Python — utilisez Selenium pour le rendu JavaScript et BeautifulSoup pour le parsing HTML. Le script complet est disponible dans la Méthode 2 de ce guide. Pour les équipes qui souhaitent analyser les avis TripAdvisor à grande échelle, la combinaison Selenium + BeautifulSoup reste la solution la plus flexible.
- Quel est le meilleur outil pour scraper TripAdvisor sans coder ?
Pour les équipes non-techniques, Octoparse offre la combinaison la plus complète : modèles prêts à l’emploi pour hôtels et restaurants, gestion native des anti-bots, exécution cloud planifiable, export multi-format (Excel, CSV, JSON, API). Pour une comparaison détaillée des outils disponibles sur le marché, un comparatif dédié est accessible dans cet article.
- Puis-je scraper les campings et les données de vols sur TripAdvisor ?
Oui. TripAdvisor référence également des campings, des hébergements alternatifs et des informations de vols.Les méthodes décrites dans ce guide (modèles Octoparse et Python/Selenium) sont applicables à ces catégories. Pour les campings, ciblez les URL de la section « Hébergements » de tripadvisor.fr.
- Les données extraites de TripAdvisor peuvent-elles servir à surveiller les prix des concurrents ?
Oui, c’est l’un des cas d’usage les plus répandus dans le secteur hôtelier français. En extrayant régulièrement les tarifs affichés sur les fiches TripAdvisor de vos concurrents directs, vous pouvez constituer un historique de prix et ajuster votre stratégie tarifaire en conséquence. Pour automatiser cette veille, les tâches cloud planifiées d’Octoparse permettent de programmer des extractions régulières sans aucune intervention manuelle.
- Quelle est la différence entre scraper TripAdvisor et utiliser l’API officielle ?
L’API officielle donne accès à des données structurées et stables, mais avec des quotas stricts (1 000 puis 10 000 appels par jour) et une validation manuelle requise. Le scraping web permet d’extraire l’ensemble des données visibles publiquement sans restriction de quota, mais demande une maintenance technique régulière. En pratique : l’API convient aux intégrations B2C stables à faible volume ; le scraping via modèle no-code ou Python s’impose pour la veille concurrentielle, l’analyse d’avis à grande échelle ou le benchmarking multi-destinations.
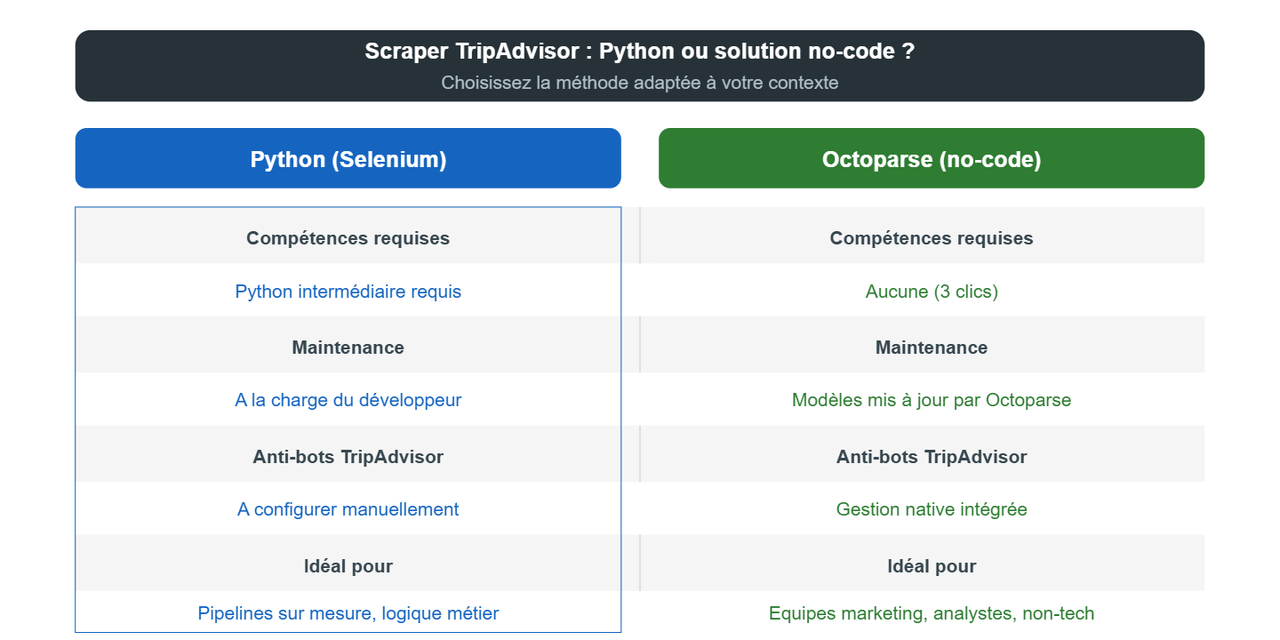
En résumé : quelle méthode choisir pour scraper TripAdvisor ?
TripAdvisor regroupe des données directement exploitables pour les professionnels du tourisme et de l’hôtellerie : tarifs, avis clients, notes, coordonnées, données de restauration et de campings. Selon votre profil technique et vos volumes, l’une des trois méthodes présentées dans ce guide sera plus adaptée que les autres.
- Méthode 1 (Modèles Octoparse) : idéale pour les équipes marketing, revenue managers et analystes sans compétences techniques. Déployable en 3 clics, zéro maintenance, export direct vers vos outils.
- Méthode 2 (Python / Selenium) : pour les développeurs qui ont besoin de flexibilité totale, d’un pipeline personnalisé ou de volumes importants avec logique métier intégrée.
- Méthode 3 (API officielle) : pour les intégrations contractuelles B2C stables, avec des volumes limités et une obligation d’affichage du logo TripAdvisor.
Pour une veille concurrentielle TripAdvisor réellement exploitable, la régularité prime sur le volume : une extraction hebdomadaire planifiée donne une vision des tendances bien plus fiable qu’un scraping ponctuel.
Pour aller plus loin dans votre stratégie data TripAdvisor :
- Vous n’avez pas encore défini quelles données exploiter en priorité ? Découvrez notre guide : Données TripAdvisor : hôtels, avis et restaurants — ce que vous pouvez en faire et comment les obtenir
- Pour comparer les solutions disponibles sur le marché (tarifs, fonctionnalités, facilité d’utilisation), un comparatif dédié est disponible ici : Meilleurs scrapers TripAdvisor 2026
Un dernier conseil pratique : commencez par tester le modèle hôtels sur une dizaine d’URLs de votre marché cible, exportez en CSV et vérifiez la structure des données avant de lancer une extraction à grande échelle. C’est la façon la plus rapide de valider que le modèle couvre bien vos besoins sans engagement.



