L’analyse de sentiment constitue un sujet populaire dans notre époque où l’opinion publique règne. Quand on aborde sur ce sujet, ce qui vient premièrement à la tête est où et comment récupérer un océan de données qui sont nécessaires pour mener une analyse de sentiments. En effet, il s’agit ici d’un des inconvénients les plus importants : il faut analyser régulièrement une grande quantité de données textuelles, ce qui veut dire que nous devons disposer de beaucoup de données qui sont quotidiennement mises à jour.
Dans cet article, notre obejectif est de vous montrer comment scraper les données Twitter via API ou à l’aide d’un web crawler avant de les mettre dans l’analyse de sentiments.
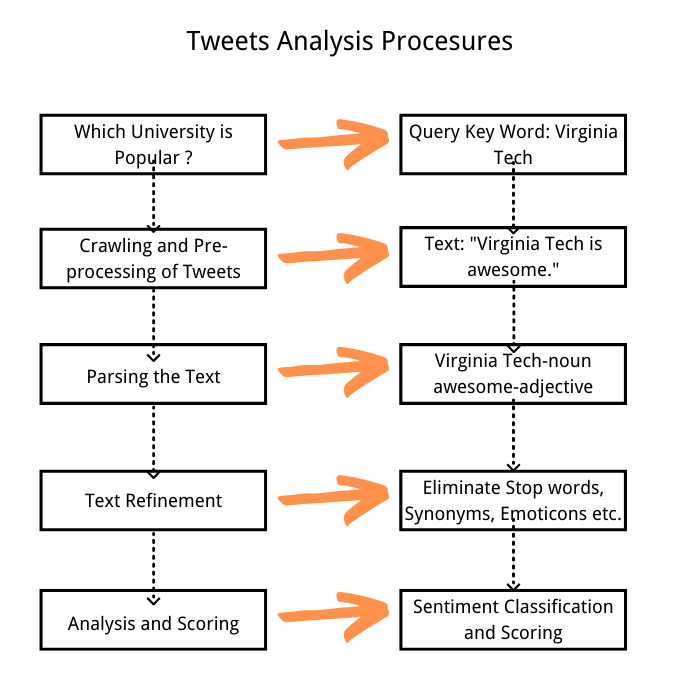
Pour bien démonstrer le processsus complet de récupérer les données et de faire l’analyse de sentiments, on va essayer de découvrir le sentiment publique sur Twiiter envers les universités. Le processus d’analyse sera comme le suivant :
Premèrement enjeu : Comment récupérer les données Twitter ?
Prenons l’exemple de Twitter, il existe plusieurs méthodes pour extraire les données : utiliser les API publiques, construire un robot d’extraction par programmation, ou choisir un outil d’extraction de données, comme Octoparse ou Import.io.
Méthode 1 : API ( À propos des API Twitter )
Il est bien connu que Twitter fournit des API publiques pour que les développeurs puissent lire et écrire des tweets avec convénience. L’API REST est capable d’identifier les applications et les utilisateurs de Twitter à l’aide d’OAuth. Ainsi, nous pouvons utiliser les API REST de Twitter pour obtenir les tweets les plus récents et les plus populaires. Twitter4j est importé pour explorer les données Twitter via l’API REST. Les utilisateurs peuvent acquérir les données après avoir défini une date spécifique, une location, des hashtags ou d’autres champs de données. Les données récupérées sont renvoyées au format JSON. Notez que les développeurs doivent créer des comptes d’application Twitter, afin d’obtenir un accès à l’API Twitter. En utilisant un jeton d’accès spécifique, l’application a fait une demande au POST OAuth2 pour échanger des informations d’identification afin que les utilisateurs puissent obtenir un accès authentifié à l’API REST.
Ce mécanisme nous permet d’extraire les informations des utilisateurs. Ensuite, nous pouvons utiliser la fonction de recherche pour explorer les tweets structurés liés au sujet d’université.
Et puis, il faut un ensemble de requêtes pour récupérer les tweets. J’ai réussi à collecter les données concernant le classement des universités de USNews 2016, 244 universités et leurs classements y compris. Et maintenant, il est temps de personnifier les champs de données que je vais utiliser avant de les exporter au format JSON.
Méthode 2 : construire un robot d’extraction par programmation
De nos jours, le besoin pour l’extraction de données connaît une grande augmentation et beaucoup sont ceux qui sont plongés dans la technologie de web scraping malgré une courbe d’apprentissage assez abrupte. Octoparse a déjà préparé pour les amateurs de web scraping un tutoriel étape par étape pour effectuer le web scraping avec Python. Veuillez consulter :
🠊 Web Scraping en utilisant Python : Un guide étape par étape
Méthode 3 : outil de web scraping pour l’extraction de données – Octoparse
Franchement, construire un robot d’extraction par programmation n’est pas facile et semble relativement compliqué pour ceux qui n’ont pas de compétence en codage. Et je reconseille d’utiliser des outils de web scraping dans ce cas-là, car ces derniers sont conçus surtout pour les non-codeurs, les libérant de la gaspillage de temps et les permettant de se concentrer sur des choses plus importantes.
Octoparse a construit 7 modèles de web scraping pour scraper les données Twitter. Avec le Template mode, les utilisateurs n’ont qu’à entrer quelques paramètres selon les instructions avant que Octoparse ne lance le web scraping et ne commence l’extraction de données.
Cas d’étude : Comment analyser l’opinion publique sur les réseaux sociaux (ex : discussion de la présidentielle sur Twitter)
Voilà un tutoriel de vidéo pour dire comment scraper les donnnées de Twitter pour l’analyse de sentiments. Je suis sûr que cela vous aide à vous familiariser avec Octoparse qui est un outil très facile à utiliser.
Pourquoi Octoparse est surtout super pour récupérer les données mises dans l’analyse de sentiments ?
˃ L’analyse de sentiments nécessitent une grande quantité de données – Octoparse est capable de scraper un nombre illimité de pages de données (la version gratuite permet d’exporter 10 mille de données à chaque fois)
˃ Les données doivent être mises à jour fréquemment – On peut plannifier l’extraction de données : par exemple, faire exécuter l’extraction chaque minute/ jour/ semaine/ mois.
˃ On veut analyser le sentiment publique sur diverses plateformes (Twitter, forums, site d’actualités, avis clients, etc) – Octoparse est applicable avec presque tous les genres de sites.
Deuxième enjeu : comment faire l’analyse de sentiments ?
Revenons au classement des universités. La technologie de classement consiste à analyser les tweets récupérés à partir de Twitter, puis à classer les tweets en fonction de leur pertinence avec une certaine université.
Attention : le suivant n’est qu’un exemple simple pour mieux démonstrer le processus de faire l’analyse de sentiments. Donc, il semble inévitablement un peu légère et simple.
La première étape est de trier les tweets les plus pertinents
Pour effectuer l’analyse des sentiments, on ne concentre que sur les tweets les plus pertinents, ce qui permet de se passer des tweets insignifiants qui risquent de rendre nos résultats inexactes.
Les tweets peuvent être classés en fonction de la similarité TF-IDF, du résumé de texte, des facteurs spatiaux et temporels, ou vous pouvez mettre en service l’apprentissage automatique pour le calssement. Et Twitter lui-même propose une méthode basée sur le temps ou la popularité. Cependant, nous avons besoin d’une méthode plus avancée capable de repérer les spams.
La deuxième étape consiste à construire un modèle d’analyse
Dans la fin de mesurer la confiance et la popularité d’un tweet, je concentre plutôt sur les quelques critères suivants : nombre de retweets, nombre de followers, nombre d’amis. Supposons qu’un tweet de confiance doit être posté par un utilisateur de confiance et qu’un utilisateur de confiance doit avoir pas mal d’amis et de followers. Et donc, un tweet populaire doit avoir un nombre élevé de retweets.
Je crée un modèle qui combine la confiance et la popularité (CP Score) pour un tweet. Et je classe ces tweets en fonction du score CP pour chacun d’entre eux. Il est à remarquer que les tweets de nouvelles ont généralement un nombre de retweets élevé et que ce type de score sera inutile pour notre analyse de sentiment. J’ai donc attribué un poids relativement faible à ce genre de contenu lors du calcul du score CP.
Puisque les tweets explorés sont déjà flitrés par les mots de requêtes et l’heure de publication, ce qui reste à prendre en compte est nombre de retweets, nombre de followers, nombre d’amis. La formule est comme le suivant.
La troisième étape est de classer les universités
Je vais faire un classement des universités selon leur réputation qui est expliquée par le score de sentiment.
Voilà trois principaux genres de textes de tweets :
Notez que la polarité négative n’est pas prise en compte puisque’elle est égale à zéro.
Le Score de sentiment est calculé pour la réputation publique. Le taux de positivité de chaque université a été utilisé comme score de sentiment pour le classement de la réputation publique. La formule ci-dessous définit le taux de positivité.
Dans cette formule, “n” représente le nombre total des tweets pour chaque université, et le chiffre “4” veut dire la polarité pour un tweet positif.
Après avoir terminé l’analyse de sentiments, je vais procéder à créer un classificateur pour l’analyse de sentiments en utilisant un algorithme d’apprentissage automatique.



