Après des années de travail dans l’industrie du Web scraping et de discussion avec des utilisateurs du monde entier, je constate que les données sur les emplois se trouvent parmi les informations les plus recherchées sur Internet.
Pourquoi ces données attirent une attention aussi importante ? Comment les obtenir à grande échelle pour en profiter au mieux ?
Pourquoi scraper les données sur les offres d’emploi ?
C’est sans doute que les données sur les offres d’emploi sont d’une valeur considérable et il existe tant de façons d’utiliser ces données, pour n’en nommer que quelques-unes :
- 💡 Alimenter les sites d’agrégation d’emplois avec de nouvelles données sur les offres
- 💡 Collecter ces données pour analyser la tendance du marché du travail, par exemple l’apparition des postes, la disparition de certains postes, le relevé de salaire reflètent dans un certain degré la nouvelle demande du marché
- 💡 Suivre des positions ouvertes et la description ou le salaire fixés par les concurrents pour se donner une longueur d’avance
- 💡 Trouver des prospects en présentant votre service aux entreprises qui embauchent pour la même chose
- 💡 Les agences de dotation grattent les sites d’emploi pour mettre à jour leurs bases de données d’emplois
Et croyez-moi, ce ne sont que la pointe d’un iceberg. Cela dit, gratter les informations sur les offres d’emploi n’est pas toujours une chose simple.
Challenges liés à la récupération de données
Tout d’abord, vous devrez décider où extraire ces informations. Il existe deux principaux types de sources de données sur les emplois :
- Les principaux sites d’agrégation d’emplois comme Indeed, Monster, Naukri, ZipRecruiter, Glassdoor, Craiglist, LinkedIn, SimplyHired, reed.co.uk, Jobster, Dice, Facebook jobs, etc.
- Chaque entreprise, grande ou petite, insère sur son site officiel une section spécialement destinée à l’embauche.
En scrapant ces pages régulièrement, vous aurez une liste toujours mise à jour des offres d’emploi.
Ensuite, vous aurez certainement besoin d’un grand nombre de données, ce qui signifie que vous devriez mettre en application un outil de web scraping pour obtenir des données à partir de n’importe lequel site mentionné ci-dessus.
Cependant, les sites d’emploi d’une grande taille peuvent mettre presque toujours en œuvre des techniques anti-scraping pour empêcher les robots de grattage de collecter des informations. Les pratiques anti-scraping les plus courants incluent les blocages IP (par le suivi des activités de navigation suspectes), les pièges du pot de miel ou l’utilisation de Captcha. Si vous êtes intéressé, cet article fournit de bonnes pratiques pour contourner certains des blocs anti-grattage courants. Au contraire, les sites des entreprises sont généralement plus faciles à gratter. Pourtant, comme chaque entreprise a sa propre interface Web / site Web, il faut configurer un crawler pour chaque entreprise séparément. Dans ce cas-là, non seulement le coût est haut, mais les sites Web changent sa structure assez souvent, ce qui pousse à développer de nouveaux crawlers dans la fin de réagir aux changements du site.
Comment scraper les données sur les offres d’emploi ?
Il existe quelques options pour extraire des offres d’emploi sur le Web.
1. Service de web scraping (Daas, soit Data as a Service)
Ces sociétés fournissent ce que l’on appelle généralement des « services gérés ». Certains fournisseurs bien connus sont Scrapinghub, Datahen, Data Hero, etc. Ils prendront en charge vos demandes et mettront en place tout ce qui est nécessaire pour faire le travail, comme les scripts, les serveurs, les proxys IP, etc. Les données vous seront fournies dans un format structuré à une certaine fréquence. Les services de grattage facturent généralement en fonction du nombre de sites à scraper, de la quantité de données à récupérer et de la fréquence de l’extraction. Certaines entreprises facturent des frais supplémentaires pour le nombre de champs de données et le stockage des données. La complexité du site Web est, bien entendu, un facteur majeur qui aurait pu affecter le prix final. Pour chaque tâche de grattage, il y a généralement des frais de maintenance mensuels.
Avantages :
- Aucune courbe d’apprentissage. Les données vous sont livrées directement.
- Hautement personnalisable et parfaitement adapté à vos besoins.
Désavantages :
- Le coût peut être élevé, notamment si vous avez beaucoup de sites à scraper (350 $ ~ 2500 $ par projet + 60 $ ~ 500 $ de frais de maintenance mensuels).
- Les coûts d’entretien à long terme peuvent causer une spirale incontrôlable du budget
- Cela nécessite un long temps de développement (3 à 10 jours ouvrables par site).
2. Configuration interne du Web scraping
Employer des personnes professionnelles et organiser une équipe sépcialement pour faire du web scraping.
Avantages :
- Contrôle complet du processus de crawling.
- Moins de challenges de communication, un délai d’exécution plus rapide.
Désavantages :
- Coût élevé. Une troupe professionnelle coûte cher.
- Le Web scraping est un processus de niche qui nécessite un haut niveau de compétence technique, surtout si vous devez scraper les sites les plus populaires ou si vous voulez extraire une grande quantité de données régulièrement. Commencer par zéro est difficile même si vous embauchez des professionnels, alors que c’est évident que les fournisseurs de services de données, ainsi que les outils de grattage, devraient être plus expérimentés pour s’attaquer aux obstacles imprévus.
- Perte de concentration. Pourquoi ne pas consacrer plus de temps et d’énergie à la croissance de votre entreprise ?
- Exigence d’infrastructure. Vous devrez obtenir les serveurs pour exécuter les scripts, le stockage des données et le transfert. Il y a aussi de fortes chances que vous ayez besoin d’un fournisseur de services proxy et d’un solveur Captcha tiers. Le processus de mise en place et de maintien de tous ces éléments au quotidien peut être extrêmement fatigant et inefficace.
- Problème d’entretien. Les scripts doivent être changés ou même réécrits tout le temps car ils se cassent chaque fois que les sites Web mettent à jour des mises en page ou des codes.
- Risques juridiques. Malgré des débats, le Web scraping est légal dans la plupart des cas. En générale, les informations publiques peuvent être récupérées en toute sécurité et si vous voulez être plus prudent à ce sujet, vérifiez et évitez d’enfreindre les TOS (conditions de service) du site Web. Donc, le risque s’abaisse si on tout confie à une autre entreprise professionnelle.
3. Outil de Web scraping
La technologie progresse et comme toute autre chose, le web scraping peut désormais être automatisé. Il existe de nombreux logiciels de Web scraping conçus pour que les personnes non techniques puissent récupérer des données sur le Web. Ces web scrapers feuillent les sites cibles et capturent les données en déchiffrant la structure HTML de la page web. Vous pourrez ” dire ” ce dont vous avez besoin à travers des ” pointer ” et des ” cliquer ” grâce à l’algorithme intégré du logiciel et puis le scraping se fonctionne automatiquement. La plupart des outils de scraping sont compatibles avec votre propre système.

Avantages :
- Économique. La plupart des outils de Web scraping font payer les utilisateurs mensuellement (60 $ ~ 200 $ par mois) et certains proposent même des formules gratuites qui sont déjà assez robustes et capables de répondre à pas mal de besoins, comme Octoparse.
- Convivial parce que sans codage. La plupart d’entre eux sont relativement faciles à utiliser et peuvent être manipulés par des personnes ayant peu ou pas de connaissances techniques. Si vous souhaitez gagner du temps, il y a certains fournisseurs qui proposent des services de configuration des crawlers ainsi que des sessions de formation.
- Puissant. Ces logiciels s’appliquent facilement aux projets de toute taille, d’un à des milliers de sites Web.
- Délai d’exécution rapide. Selons vos efforts, un crawler peut être construit en 10 minutes.
- Contrôle complet. Une fois que vous avez saisi son utilisation, vous pouvez configurer des crawlers ou modifier ceux déjà existants sans demander l’aide de l’équipe technique ou du fournisseur de services.
- PFaible coût de maintenance. Comme vous n’aurez plus besoin d’une troupe de technologie pour réparer les crawlers, vous pouvez facilement contrôler le coût de maintenance.
Désavantages :
- Courbe d’apprentissage. Quel que soit le produit que vous choisissez, il te faut consacrer un peu de temps pour apprendre à l’utiliser. Et je peux vous dire par avance, les outils virtuels tels que Octoparse, import.io, dexi.io sont plus faciles à apprendre.
- Problème de compatibilité. Tous les outils de Web scraping prétendent couvrir des sites de toutes sortes, mais la vérité est qu’il existe de toute façon des sites pour lesquels le scraping est impossible.
- Captcha. La plupart des outils de Web scraping ne peuvent pas résoudre complètement les problèmes causés par Captcha.
Un vrai exemple de web scraping …
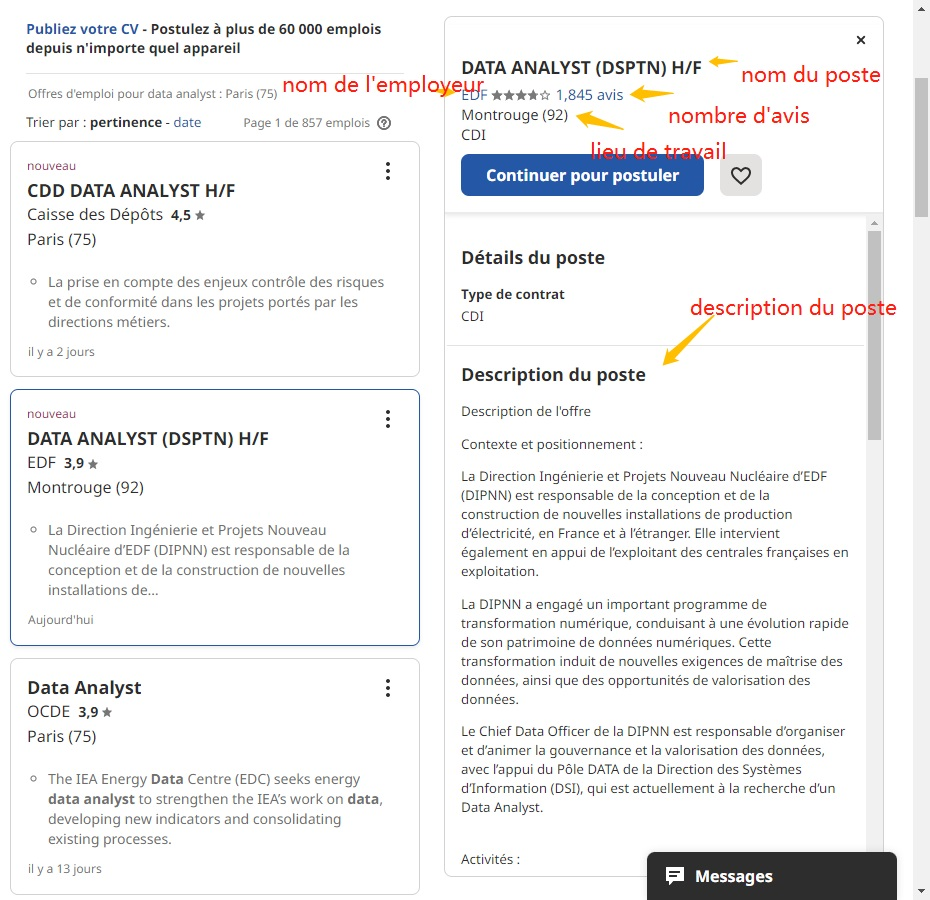
Afin de rendre cet article plus utile pour vous, j’ai décidé de vous donner un petit tutoriel sur comment scraper Indeed avec Octoparse. Dans cet exemple, je vais récupérer quelques informations de base pour le poste : titre du poste, lieu de travail, nom de l’employeur, description de l’emploi, nombre d’avis, url de la page.
Faire la préparation
Télécharger Octoparse et installez-le. Il serait préférable que vous connaissiez déjà comment utiliser l’Octoparse. Consultez son centre d’aide pour avoir une idée de sa logique et sa façon de fonctionnement.
Configurer une tâche de scraping
# Étape 1 Lancer Octoparse et créer un nouveau projet avec le Mode Avancé
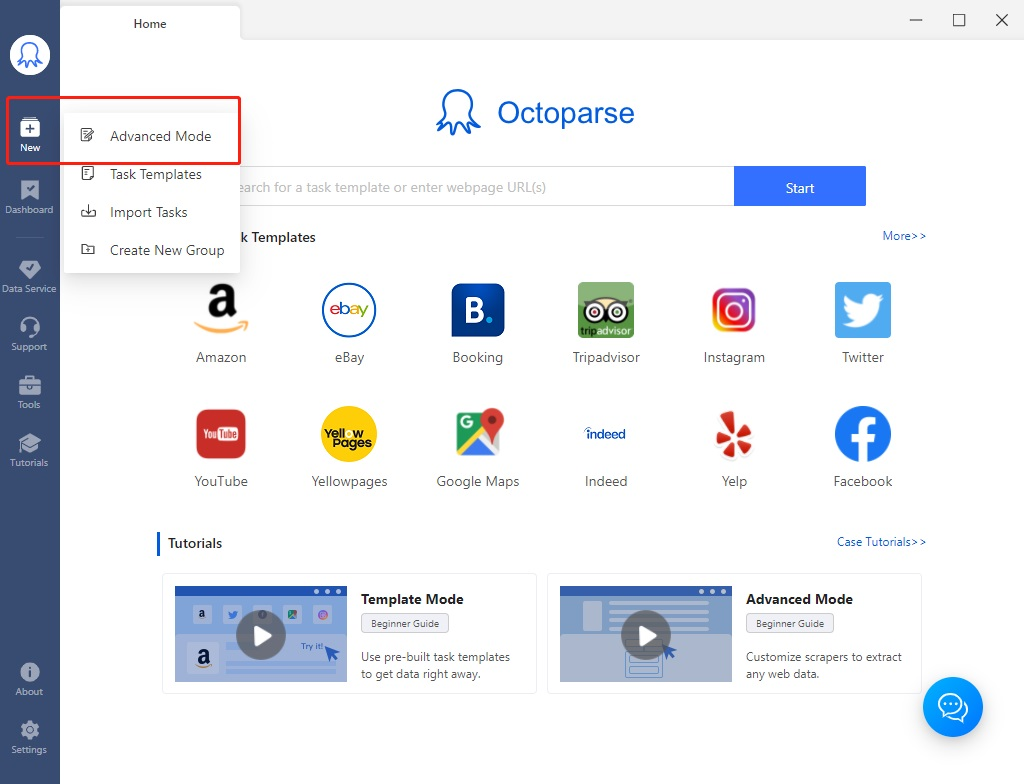
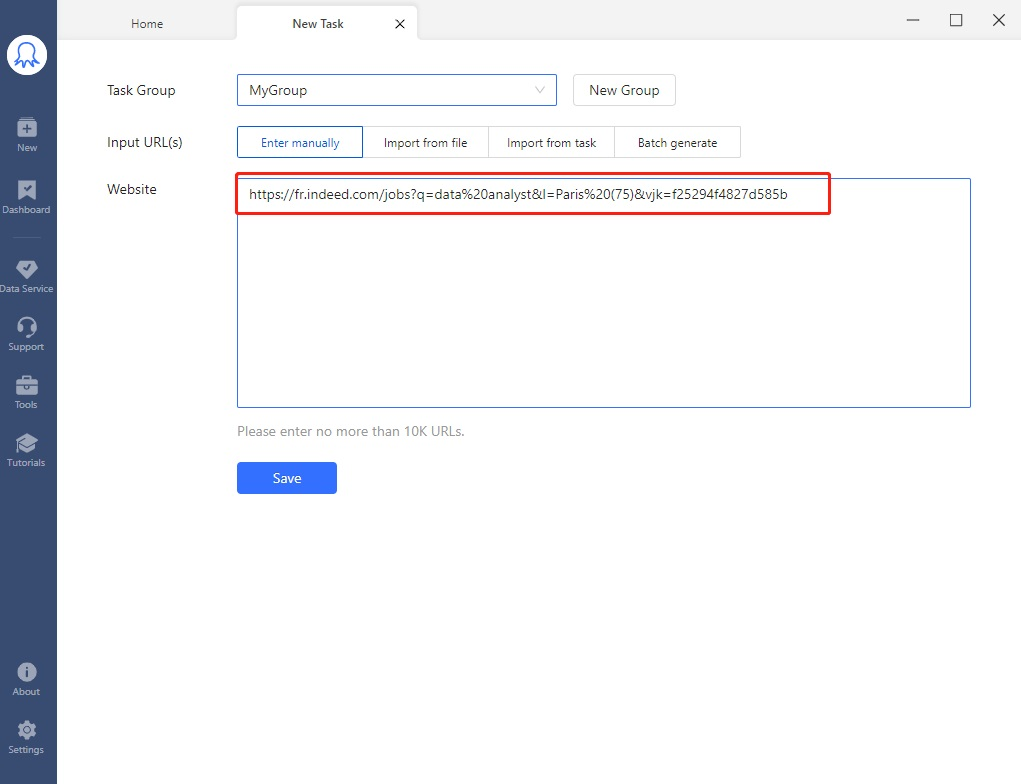
# Étape 2 Entrer l’URL cible (exemple : https://fr.indeed.com/jobs?q=data%20analyst&l=Paris%20(75)&vjk=f25294f4827d585b) dans la zone de URL. C’est l’URL copié à partir de Chrome lors de la recherche de ” data scientists ” à proximité de ” Paris ” sur https://fr.indeed.com/. Cliquer sur ” Save ” pour continuer la configuration.
# Étape 3 Cliquer sur le premier titre du poste. Ensuite, cliquer sur le deuxième (ou tout autre titre de poste fera l’affaire).
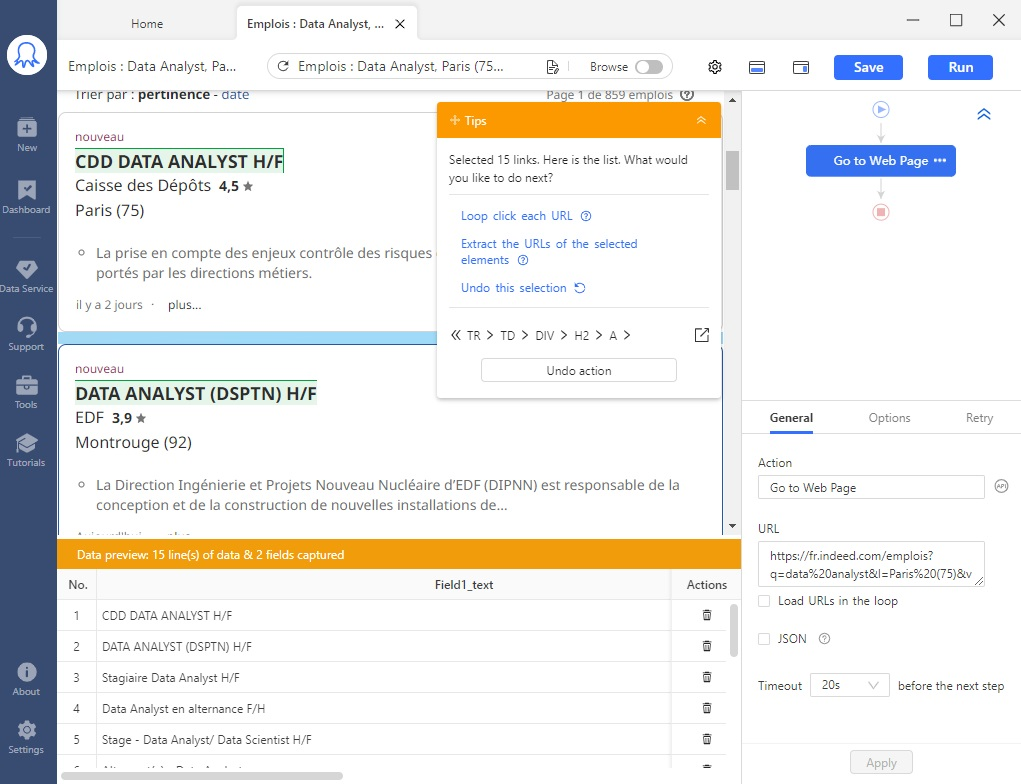
# Étape 4 Suivre les instructions sur le panneau ” +Tips “, où se lit maintenant ” Selected 15 links “. Puisque notre intention est de cliquer sur chaque titre et de l’ouvrir, il est donc logique de sélectionner ” Loop click each URL “.
#Étape 5 Actuellement, on est sur la page emploi avec des détailles et notre but est d’extraire les données en cliquant dessus. Cliquer sur le titre du poste, le lieu de travail, le nombre d’avis, le nom de l’employeur et la description du poste.
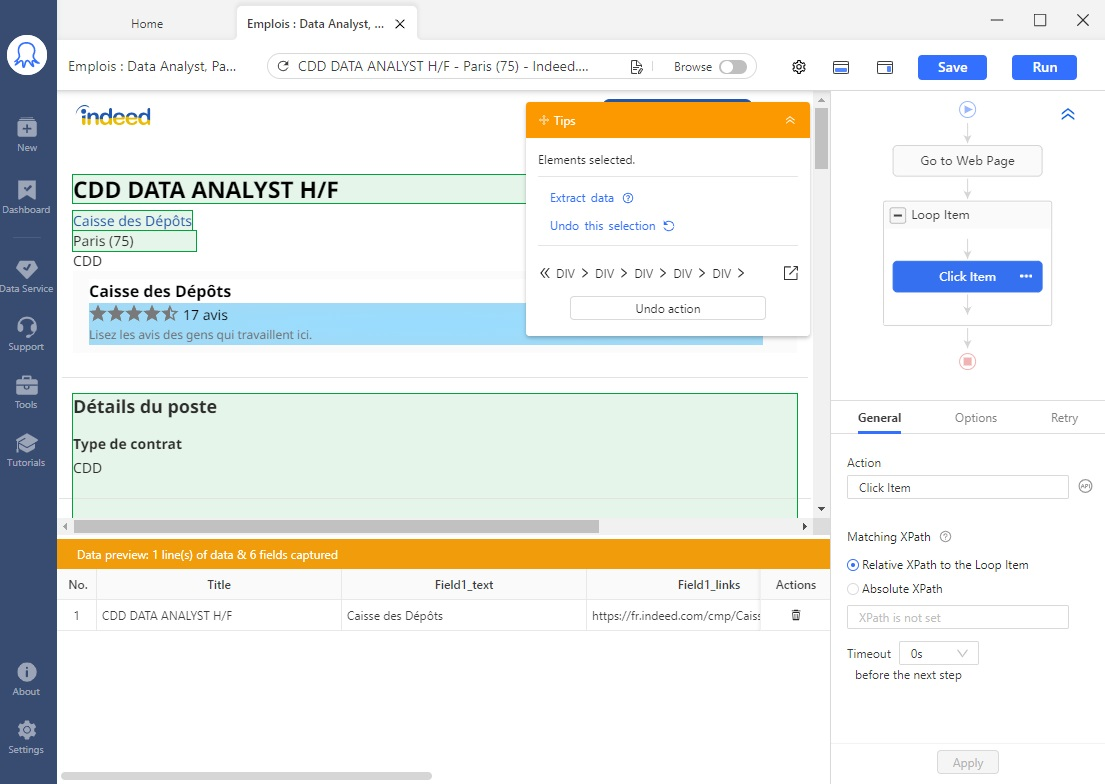
# Étape 6 Une fois que la sélection des champs nécessaires est terminée, cliquer sur ” Extract data ” dans le panneau de ” +Tips “.
# Étape 7 Ensuite, capturer l’URL de la page en suivant les trois étapes indiquées.
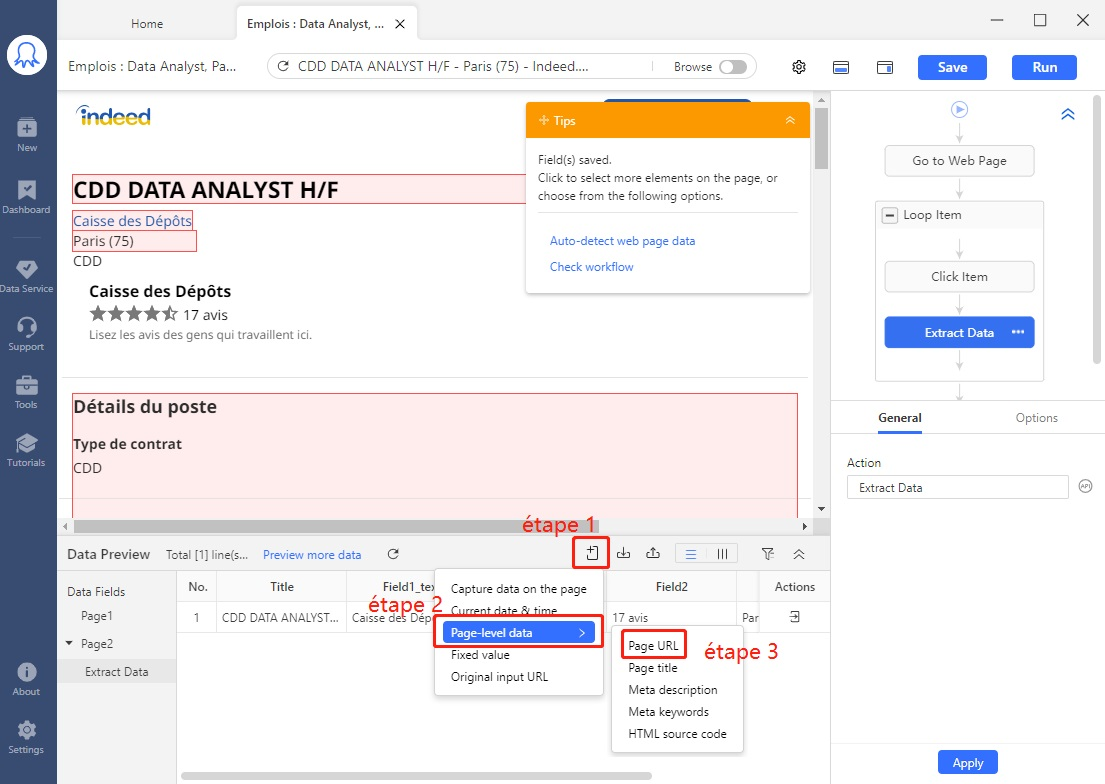
Conseil : Octoparse génère automatiquement des noms de champs pour les données capturées. Si vous voulez les renommer, tapez simplement au-dessus de noms de champ actuels après une double clic.
# Étape 8 Jusqu’à présent, toutes les données d’emplois sur la première page sont récupérées, mais on veut certainement scraper plus d’une page. Pour ce faire, il faut recourrir à la pagination, c’est-à-dire, demander à Octoparse de parcourir plusieurs pages.
Trois sub-étapes sont suffisantes :
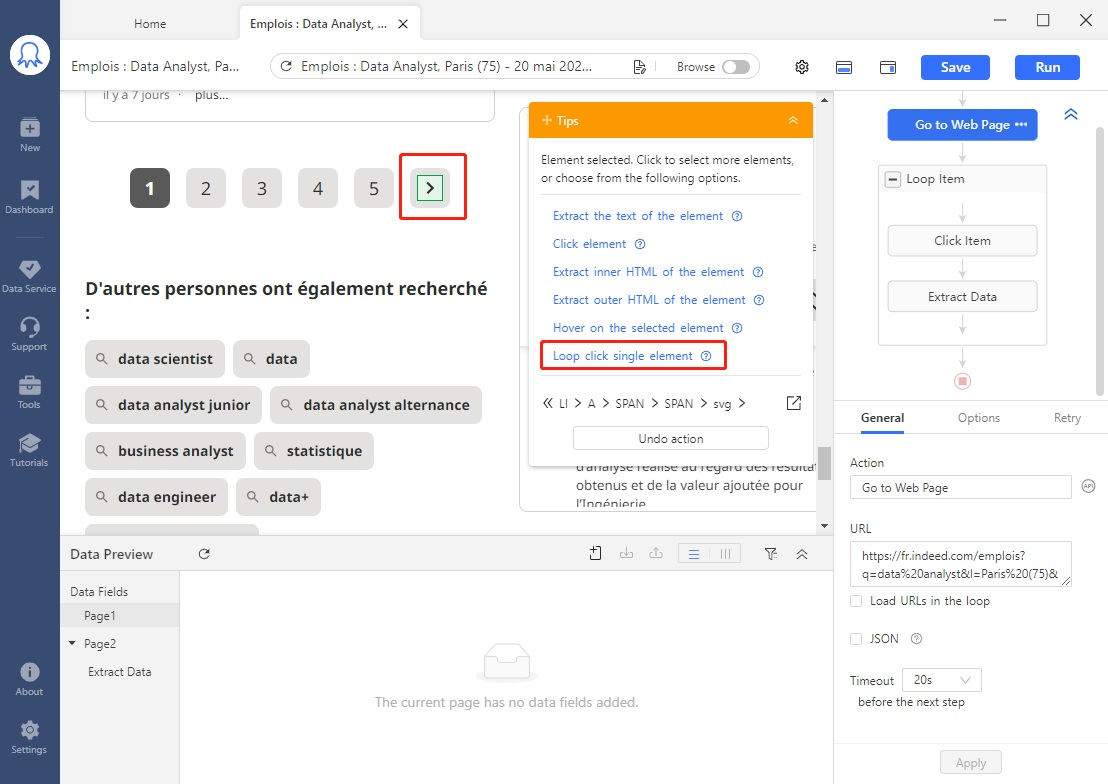
– Retourner à la page initiale des résultats de la recherche en cliquant sur ” Go to Web Page ” de boucle du workflow
– Défiler la page et trouver le bouton ” Suivant “, cliquer dessus.
– Sélectionner ” Loop click single element ” sur le panneau ” +Tips “. Octoparse cliquera automatiquement sur ce bouton jusqu’à ce qu’il atteigne la dernière page (lorsque « Suivant » ne se montre plus sur la page).
Conseil : Vous pouvez également préciser le nombre de pages à extraire. Par exemple, si vous souhaitez extraire uniquement les 3 premières pages, entrez le numéro ” 2 ” pour ” Exit loop when repeats “. Dans ce cas-là, Octoparse ne pagine que 2 fois et se termine lorsqu’il atteint la page 3.
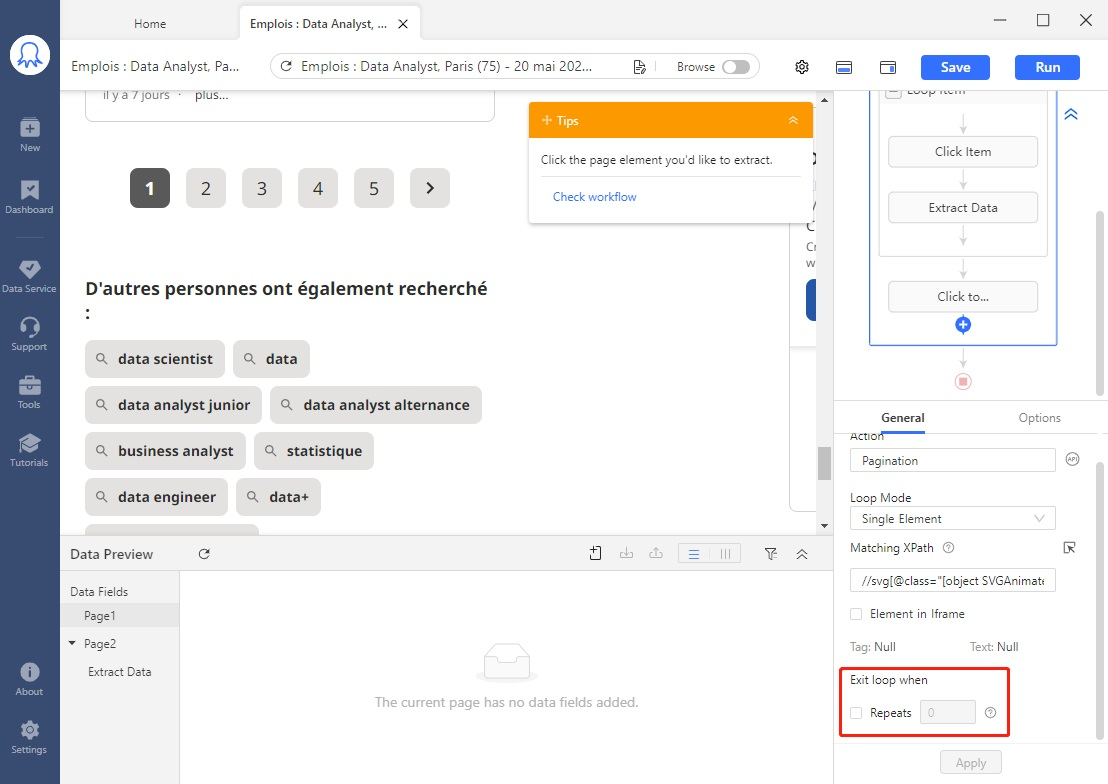
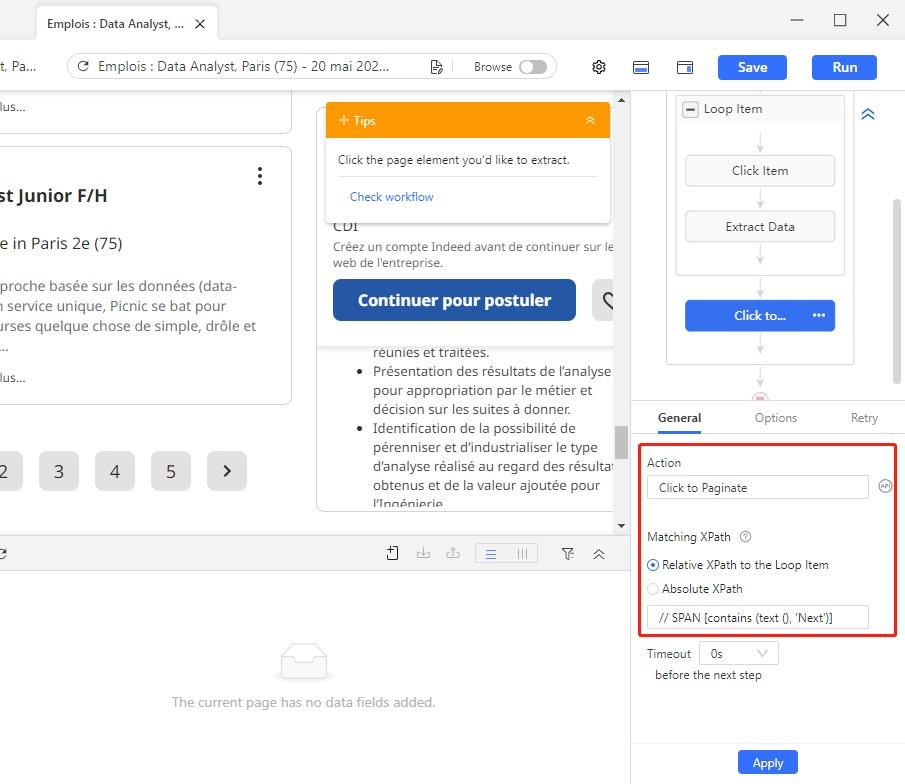
# Étape 9 Dès que je consulte la page 2, je remarque que le bouton ” Suivant ” n’est plus détecté correctement car le XPath généré automatiquement désigne le bouton ” Précédent ” à la place. Pour le résoudre, je vais devoir modifier manuellement le XPath.
Avec la boucle de pagination sélectionnée, changer le XPath de l’élément en // SPAN [contains (text (), ‘Next’)]. Maintenant, Octoparse réussit à détecter le bon bouton ” Suivant “.
Conseil : Découvrez qu’est-ce que le xpath et apprennez à comment modifier XPath en cas d’échec dans cet article.
# Étape 10 Voilà. La configuration est accomplie. Cliquer sur le bouton ” Run ” en haut pour exécuter la tâche. Après que l’extraction est finie, vous pouvez télécharger les données dans des formats xsxl, scv et d’autres.
Vous pouvez aussi scraper les données des autres sites par ces étapes. Téléchagez l’Ocotparse pour faire une découverte. Et s’il y a une question, n’hésitez pas à nous contacter.
Utilisation du modèle pour scraping
Si vous cherchez une méthode plus facile que la création un flux de travail par vous-même, l’utilisation de modèle est fortement recommandé. Vous n’avez besoin que d’entrer des URLs cibles, et vous aurez des données automatiquement extraites à l’aide de notre modèles prédéfinis.
https://www.octoparse.fr/template/indeed-entreprise-avis-scraper
En conclusion
En bref, quelque soit votre choix pour scraper les données sur les offres d’emploi, il y aura sûrement des avantages et des désavantages. La meilleure pratique doit être celle qui correspond à vos besoins spécifiques (calendrier, budget, taille du projet, etc.). De toute évidence, une solution qui fonctionne bien pour les entreprises du Fortune 500 peut ne pas fonctionner pour un étudiant. Cela dit, allez fouiller la valeur des données !



