Il existe deux façons d’extraire automatiquement des données d’un site web: la première consiste à créer un robot d’exploration du web dans un langage de programmation tel que Python, et la seconde à utiliser un outil de scraping web tel qu’Octoparse pour scraper les données. Mais quelle que soit l’approche adoptée, la XPath joue un rôle important : si vous savez comment écrire une requête XPath, vous pouvez récupérer des données plus correctement et plus efficacement.
Dans cet article, nous allons donc nous pencher sur les concepts de base de XPath, la manière d’écrire XPath et certaines des fonctions les plus utilisées.
Concepts de base de XPath
Dans cette partie, nous présentons brièvement les concepts de base de XPath.
1. Qu’est-ce que la XPath?
XPath (XML Path Language) est une syntaxe (langage) concise permettant de spécifier des éléments, des valeurs d’attributs, etc., à partir de documents XML/HTML structurés en arborescence.
Les pages Web étant généralement écrites en HTML, la XPath est souvent utilisée pour extraire des informations des pages Web. Si vous souhaitez visualiser le HTML d’une page web dans votre navigateur (Chrome, Firefox, etc.), vous pouvez facilement accéder au document HTML correspondant en appuyant sur F12.
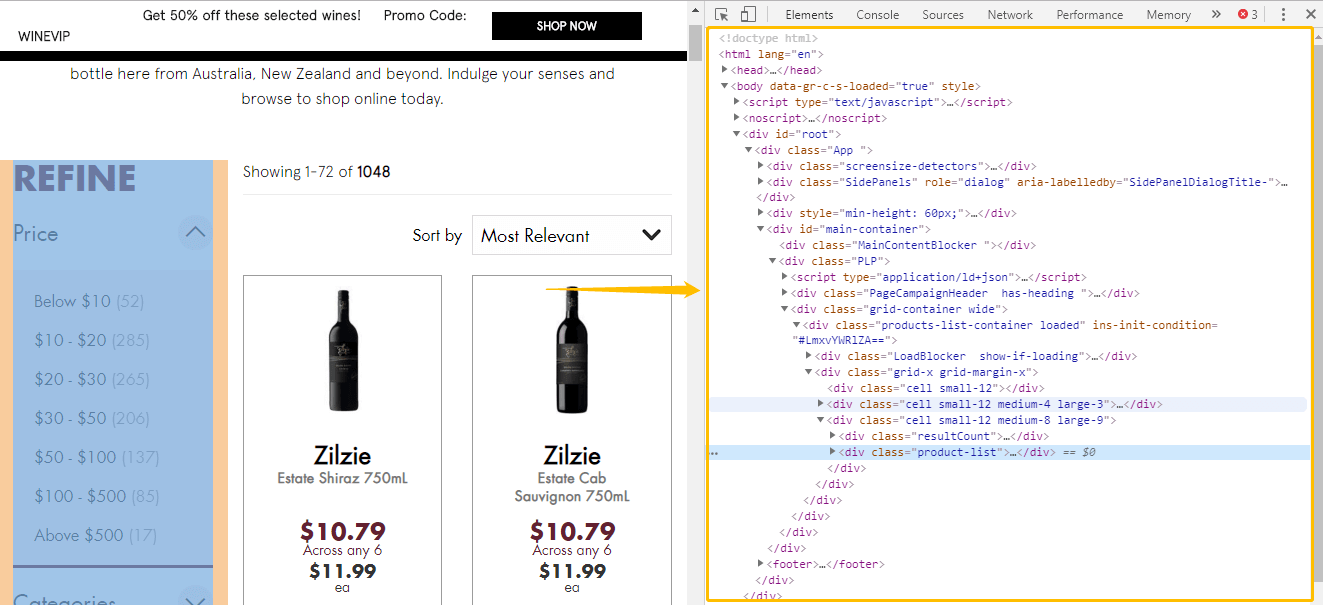
2. Comment fonctionne la requête XPath
Voyons comment fonctionne la XPath. L’image ci-dessous fait partie d’un document HTML.
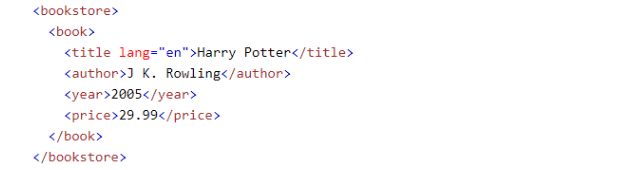
HTML est comme une structure arborescente avec différents niveaux. Dans cet exemple, le premier niveau est bookstore, le deuxième niveau est book, et title, author, year et price sont tous de troisième niveau.
Le texte avec des crochets (comme <bookstore>) est appelé un élément; les éléments HTML se composent généralement d’une balise de début et d’une balise de fin, avec du contenu inséré entre les deux.
<xx(balise de début) > contenu </xx(balise de fin)>
XPaths décrit une structure hiérarchique, séparée par une barre oblique “/”, et vous permet de spécifier différents nœuds à partir d’un nœud de référence (Axe), similaire à une URL. Dans cet exemple, pour rechercher l’élément “author”, XPath ressemble à ceci :
/bookstore/book/author
Pour mieux comprendre, découvrez comment trouver un fichier spécifique sur votre ordinateur:
Pour trouver le fichier nommé “Author”, le chemin de fichier correct est : bookstore (book) (author).

Tout comme chaque fichier sur votre ordinateur a son propre chemin, chaque élément d’une page Web a un chemin. Ce chemin est décrit dans XPath.
XPath absolu: XPath qui part de l’élément racine (l’élément supérieur du document) et passe par tous les éléments qu’il contient pour atteindre l’élément cible.
Par exemple:
/html/body/div/div/div/div/div/div/div/div/div/span/span/span…
Les XPaths absolus peuvent être très longs et déroutants, donc pour simplifier les XPaths absolus, vous pouvez utiliser “//” pour omettre les chemins et obtenir une Xpath relative (également appelés XPaths courts), par exemple:
XPath absolue:
/bookstore/book/author
XPath relative:
//author
3. Comment rechercher et écrire une requête XPath
【Google Chrome】
Affichez une page dans Chrome et affichez les outils de développement à partir du menu contextuel [Vérifier]. En html dans l’onglet Elément, faites un clic droit sur l’élément. Sélectionnez [Copier] -> [Copier XPath] dans le menu. Copiez le XPath dans le presse-papiers pour localiser l’élément.
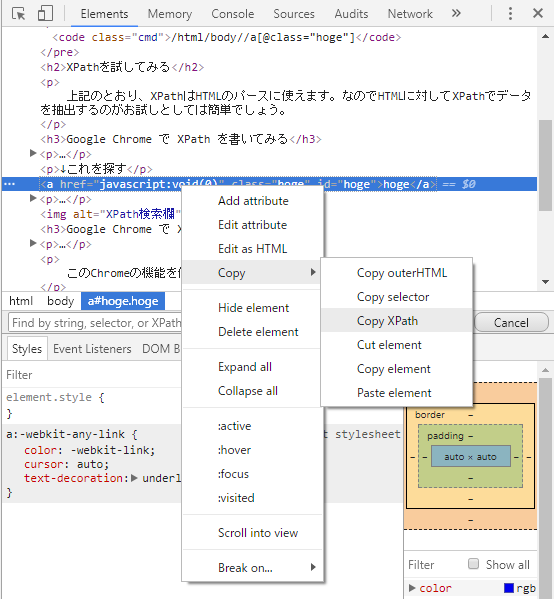
Utilisez “Ctrl + F” à partir du code HTML de la balise d’élément pour appeler le champ de recherche; entrez XPath et l’élément correspondant est sélectionné.
Vous pouvez également ajouter une extension appelée “XPath Helper“, lorsque vous entrez XPath, il vous montrera les résultats correspondants. (Installer XPath Helper)
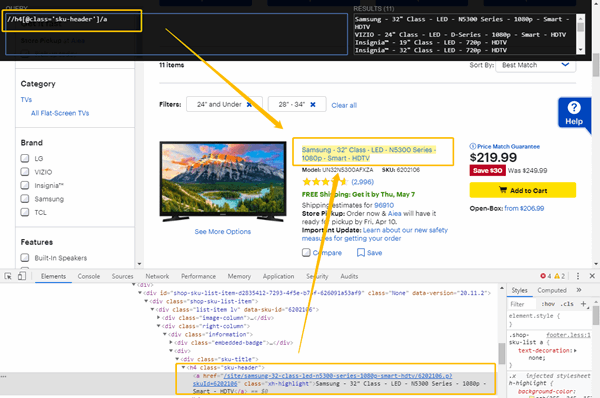
【Firefox】
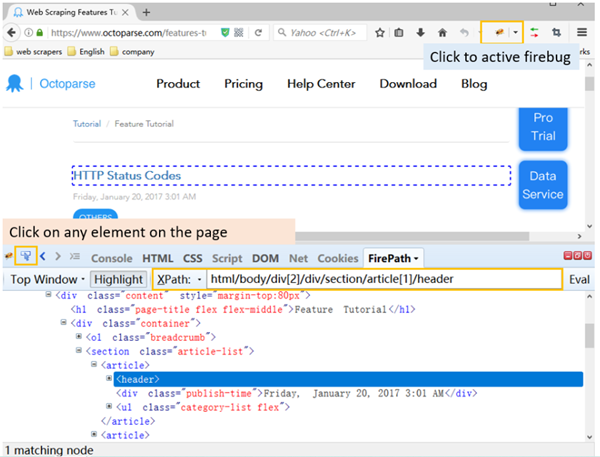
Vous pouvez utiliser l’extension Firebug, disponible dans les anciennes versions de Firefox.
Ouvrez une page Web dans Firefox ➡ cliquez sur le bouton Firebug ➡ cliquez sur un élément de la page ➡ le XPath de l’élément sera affiché
Comment écrire XPath
Cette partie décrit comment localiser et extraire des données de pages Web (HTML) à l’aide de XPath, c’est-à-dire, comment écrire une XPath.
1. Localiser par élément
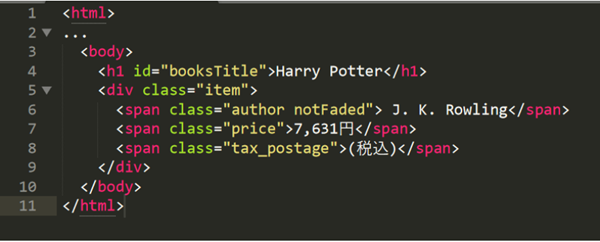
Dans l’exemple HTML ci-dessous, vous pouvez voir que le texte est entouré de symboles tels que <strong> </strong>, <html> </ html>. Les symboles tels que <strong></strong> sont appelés des balises.
<balise>contenu</balise>
La première balise est appelée “balise de début” et la deuxième balise est appelée “balise de fin”. L’ensemble de la balise de début à la balise de fin est appelé un élément.
Les parties affichées en rouge dans le code HTML ci-dessous sont des balises. (Il apparaît en bleu dans Firefox et en violet dans Chrome.)
Vous trouverez ci-dessous un résumé des balises que vous voyez souvent en HTML. Voir cet article pour plus de détails!
| <a> </a> | un lien |
| <p> </p> | un paragraphe |
| <div> </div> | une plage spécifique |
| <li> </li> | un élément de liste |
| <img> </img> | une image |
| <table> </table> | un tableau |
| <tr> </tr> | une ligne de tableau |
| <td> </td> | une colonne de tableau |
La façon la plus courante d’écrire XPath est d’écrire des balises séparées par des barres obliques “/”.
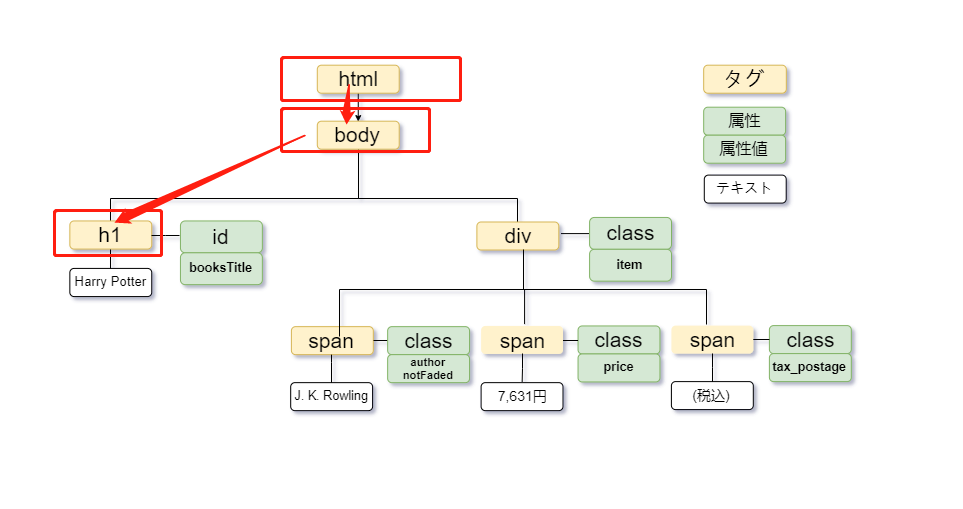
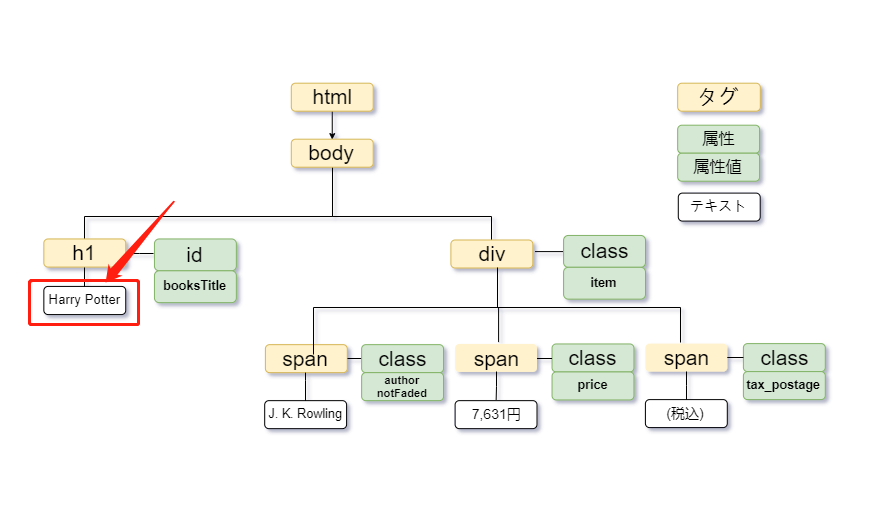
Par exemple, si vous souhaitez obtenir “Harry Potter” à partir de ce code HTML, vous pouvez spécifier “balise html-> balise body-> balise h1” à partir du haut de l’arborescence. Écrit comme:
/html/body/h1
Vous pouvez également utiliser “//” :
//h1
Dans cet exemple, lorsque vous obtenez “7 631 yens”, c’est “span” dans la deuxième ligne sous “div”, alors écrivez-le comme:
//div/span[2]
De manière abstraite, la syntaxe XPath écrite avec des balises est la suivante.
// nom de l’élément
et
// nom de l’élément/nom de l’élément…
2. Localiser par attribut
L’attribut détaille les informations de l’élément. En ajoutant des attributs aux balises, vous pouvez spécifier des éléments et ajouter des descriptions spécifiques. L’attribut est généralement affiché sous la forme id=”booksTitle”. Vous pouvez également cibler plusieurs attributs.
<Nom de l’élément Nom de l’attribut=”valeur de l’attribut”>
Les attributs les plus courants sont href, title, style, src, id, class, etc. Voir cet article pour plus de détails!
Les attributs sont représentés par la fonction “@“.
Par exemple, si vous voulez obtenir “Harry Potter”, veuillez écrire XPath comme:
//h1[@id=”books Title”]
De façon abstraite, la XPath écrite dans l’attribut est la suivante:
//nom de la balise [@nom d’attribut = “valeur d’attribut”]
Si vous voulez obtenir tous les éléments avec les mêmes attributs, écrivez:
//*[@nom d’attribut=”valeur d’attribut”]
3. Localiser par texte
Le texte est contenu comme indiqué ci-dessous.
<nom de la balise> texte </nom de la balise>
La récupération de données à partir d’une page Web consiste généralement à récupérer du contenu ou du texte dans la page. Ainsi, vous pouvez directement localiser le texte que vous souhaitez obtenir.
Dans XPath, le texte est représenté par la fonction “text()“.
Par exemple, si vous voulez obtenir “Harry Potter”, spécifiez le texte et écrivez-le:
//h1[text()=”Harry Potter”]
De manière abstraite, la syntaxe XPath écrite dans l’attribut est la suivante:
// Nom de la balise [text() = “Texte à récupérer”]
Si vous souhaitez obtenir le même texte pour tous les éléments, écrivez:
// * [text() = “Texte à récupérer”]
4. Localiser par des relations de balises
Dans l’arborescence HTML, tous les éléments ont une relation parent-enfant/frère.
L’élément qui contient un ou plusieurs éléments est appelé l’élément parent et l’élément contenu est appelé élément enfant.
L’élément enfant n’a qu’un seul élément parent et est situé entre les balises de début et de fin de l’élément parent. Les éléments ayant le même élément parent sont appelés éléments frères.
Regardons également un exemple spécifique.
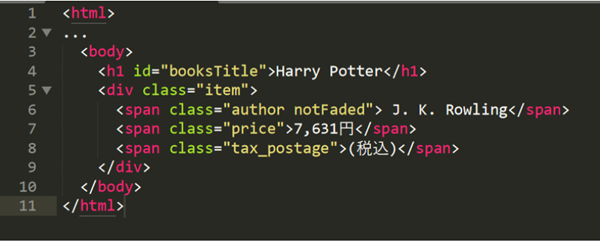
L’exemple suivant est basé sur l’élément <body>, où l’élément <body> est l’élément parent des éléments <h1> et <div>, et les éléments <h1> et <div> sont les éléments enfants du < body> element. Et <h1> et <div> sont les éléments frères car ils ont le même élément parent <body>.
De plus, puisque l’élément <div> est l’élément parent de deux éléments <span>, les deux éléments <span> sont les descendants de l’élément <body>.
Vous pouvez obtenir les éléments qui ont une relation parent-enfant ou frère basée sur l’élément actuel. Par exemple, si vous souhaitez obtenir «7 631 yens», vous pouvez écrire des Xpath différentes.
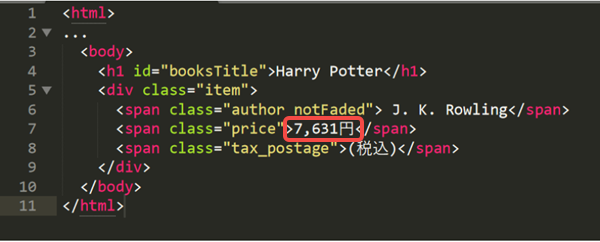
Considérez-le comme un élément enfant de l’élément <div>:
//div/span[2]
Considérez-le comme un descendant de l’élément <body>:
//body//span[2]
Considérez-le comme un élément frère de <span class = “author notFaded”>
//span[@class=”author notFaded”]/following-sibling::span[1]
Considérez-le comme un élément frère de <span class=”tax_postage”>
//span[@class=”tax_postage”]/preceding-sibling::span[1]
Deux fonctions, « following-sibling :: » et « preceding-sibling :: », sont généralement utilisées pour localiser les balises frères.
“Following-sibling ::” localiser l’élément frère après l’élément spécifié
“Preceding-sibling ::” localiser l’élément frère avant l’élément spécifié
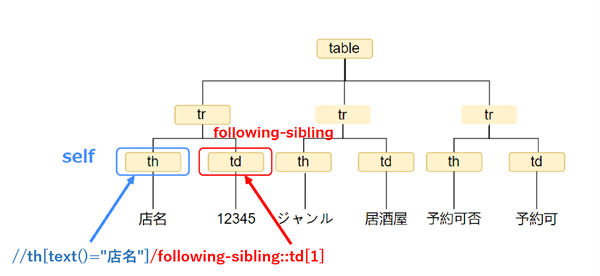
“Following-sibling ::” est très utile pour des éléments du tableau. Par exemple, il y a l’exemple HTML suivant.
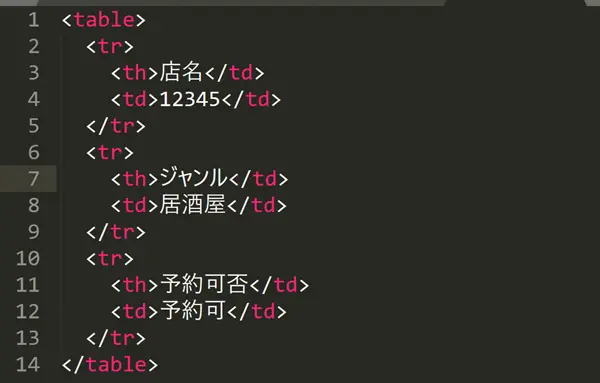
Ce HTML ressemble à un tableau comme celui ci-dessous.
| 店名 | 12345 |
| ジャンル | 居酒屋 |
| 予約可否 | 予約可 |
Dans cet exemple, nous voulons obtenir le nom du magasin “12345”. Cependant, il existe plusieurs éléments <td>, // td [1] ne peut pas les gérer. De plus, si vous souhaitez obtenir une table avec la même structure à partir de plusieurs pages à la fois, il est recommandé d’utiliser “following-sibling ::” avec une valeur fixe comme l’axe.
//th[text()=”店名”]/following-sibling::td[1]

De manière abstraite, la requête XPath écrite avec des relations de balise est la suivante:
Elément parent: // nom de balise d’axe / ..
Élément enfant: // nom de balise d’axe / nom de l’élément enfant
Elément descendant: // nom de balise d’axe // nom de l’élément descendant
L’élément frère suivant: // nom de balise d’axe / following-sibling:: nom de l’élément frère après lui
L’élément frère précédent: // nom de balise d’axe / preceding-sibling:: nom de l’élément frère avant lui
S’il existe plusieurs correspondances qui répondent aux critères, vous pouvez ajouter [N] pour spécifier le Nième élément.
Les fonctions les plus utilisées de XPath
Dans cette partie, je présenterai les fonctions hot utilisées afin de localiser plus précisément les données dans la page Web.
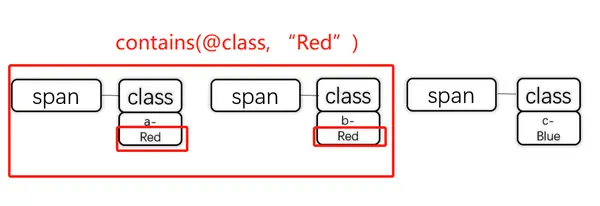
1.contains() : localise un élément qui contient une chaîne spécifique
contains() est généralement utilisé pour la recherche floue de chaînes contenues dans des valeurs d’attribut ou du texte.
contains(@class, “XXX”) : localise l’élément dont la valeur d’attribut contient une chaîne spécifique.
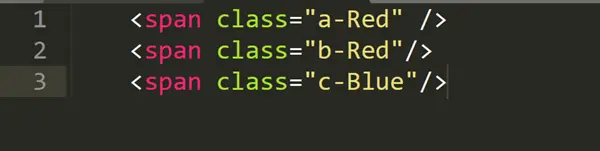
Par exemple, si vous souhaitez obtenir tout le contenu contenant Red dans l’attribut class à partir du HTML, Xpath:
//span[contains(@class,“Red”)]
En d’autres termes, ce XPath signifie obtenir un élément span qui contient Red dans l’attribut class.
contains(text(), “XXX”) : spécifiez un élément dont le texte contient une chaîne spécifique
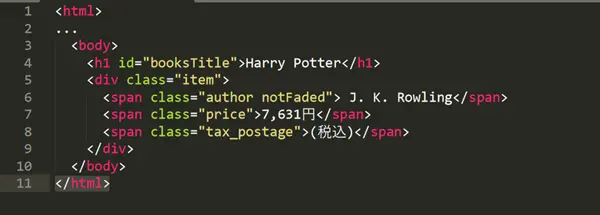
Par exemple, si vous souhaitez localiser un élément contenant le caractère “Rowling” à partir de ce code HTML:
//span[contient(text(),”Rowling”)]
Lors du positionnement du bouton de pagination, [contains (text(), “next”)] est souvent utilisé.
2.position(): localiser l’élément à une position spécifique
1. []
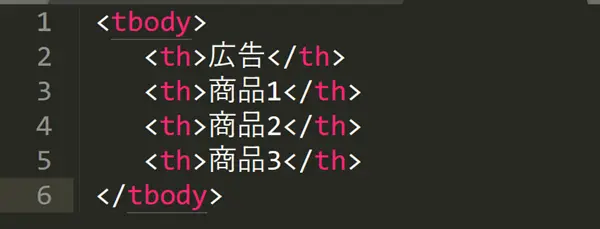
Par exemple, dans le code HTML ci-dessus, “Product 3” est le quatrième élément, il est donc écrit comme suit.
//tbody/th[4]
2.position()=
//tbody/th[position()=4]
3.position()>
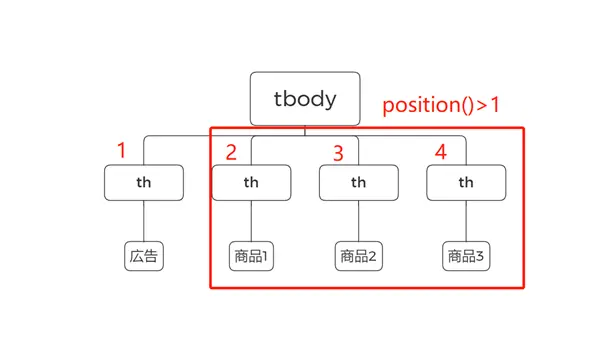
Si vous souhaitez obtenir des éléments autres que “ad”, car “ad” est le premier élément, Xpath:
//tbody/th[position()>1]
3.and/not/or : sélectionner des éléments contenant plusieurs conditions
and- Sélectionner des éléments qui correspondent à plusieurs conditions
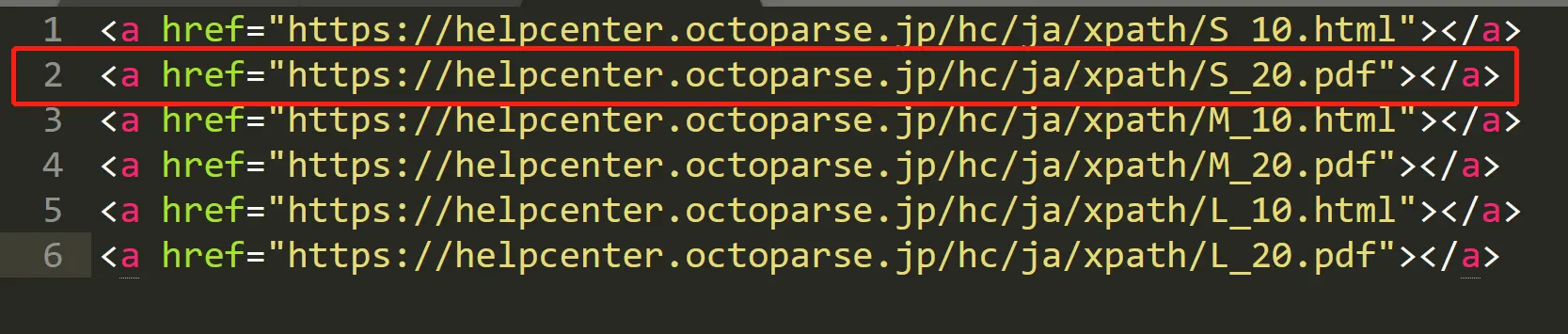
Si vous souhaitez obtenir le href incluant “S_20” et “pdf” à partir de ce HTML:
//a[contains(@href,“S_20”) and contains(@href,“pdf”)]
not- Sélectionner des éléments qui ne contiennent pas de conditions spécifiques
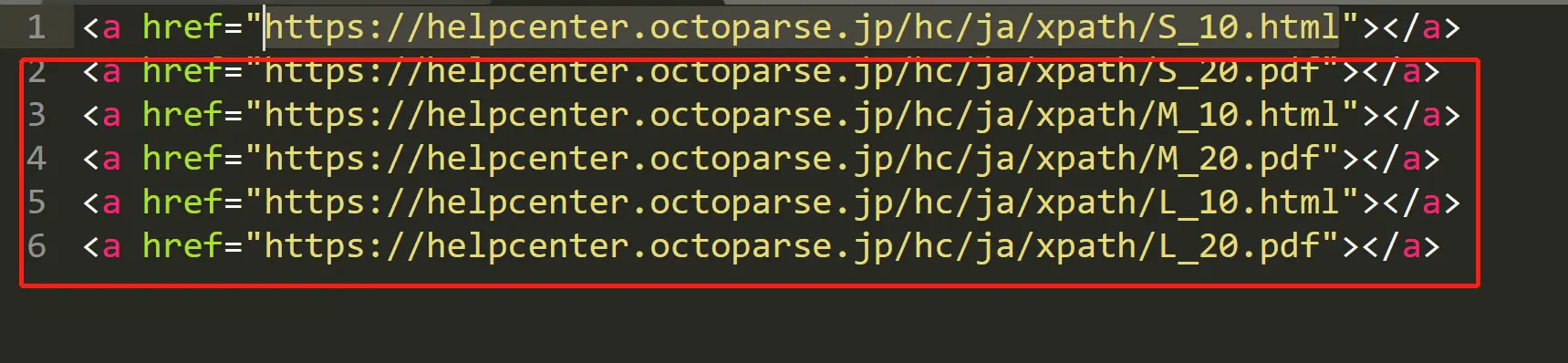
Si vous souhaitez obtenir @href autre que https://helpcenter.octoparse.jp/hc/ja/xpath/S_10.html à partir de ce code HTML:
//a[not(contains(@href, “S_10”))]
or- Sélectionner des éléments qui correspondent à l’une des multiples conditions

Si vous souhaitez obtenir le href contenant M ou L à partir de ce code HTML:
//a[contains(@href,”M_”) or contains(@href,”L_”)]
De plus, si vous souhaitez obtenir un href autre que M ou L, veuillez combiner not et or:
//a[not(contains(@href,”M_”) or contains(@href,”L_”))]
Si vous souhaitez en savoir plus sur la requête et les fonctions XPath, veuillez vous référer à cet article.
Conclusion
La requête Xpath est hautement recommandé parce qu’elle est facile à utiliser pour l’exploration du Web. Combiné à des expressions régulières, il permet d’obtenir des données encore plus intéressantes. Il est donc fortement recommandé aux débutants qui souhaitent utiliser des outils de crawler!



