Le Google scraping est un sujet qui retient de plus en plus d’attention des growthhackers, des spécialistes de marketing digital, des experts en référencement. D’après une étude menée auprès des utilisateurs d’Octoparse, Google occupe la première place de la liste des sites les plus scrapés en 2025.
Dans cet article, on va présenter quatre façons utiles pour extraire les résultats de SERP Google vers Excel/Google Sheets ou d’autres fichiers. Et bien sûr, tant des méthodes no-code que quelques méthodes plus populaires sont incluses dans le but de satisfaire les besoins des personnes avec connaissance de programmation de différents niveaux.
À propos de Google Scraping
Le Google scraping désigne l’extraction automatisée de données provenant des résultats de recherche sur Google. Son utilisation permet d’extraire un grand nombre d’informations des résultats de la SERP Google (pages de résultats du moteur de recherche), parmi lesquelles on trouve notamment des mots-clés, des liens, etc. Il est en général surtout utilisé pour analyser le positionnement des sites Web, observer les tendances d’une recherche ou extraire des données dans le cadre de diverses applications.
En définitive, les résultats de recherche Google constituent un levier intéressant pour les entreprises afin de déceler des stratégies gagnantes et de récolter un grand nombre d’informations, notamment pour affiner leurs pratiques numériques.
Comment extraire les résultats de recherche de Google ?
Pour récupérer les SERP de Google, plusieurs stratégies sont envisageables :
- Scraper manuellement les pages de résultats de Google en copiant les informations importantes vers un tableur, pratique pour des besoins très ponctuels.
- Utiliser des outils de web scraping comme Octoparse pour extraire automatiquement titres, URLs, extraits et autres éléments des SERP sans écrire une ligne de code.
- Passer par des API (officielles ou tierces) pour extraire des résultats de recherche structurés, souvent au format JSON ou CSV, adaptées aux gros volumes.
- S’appuyer sur des extensions de navigateur dédiées au scraping pour capturer les données directement depuis la page Google en quelques clics.
- Développer ses propres scripts en Python, JavaScript ou autre langage pour un scraping totalement sur mesure, avec une logique et des filtres adaptés à ses besoins.

Transformer les sites web vers Excel, CSV, Google Sheets ou base de données.
Auto-détecter les sites Web et extraire les données sans aucun codage.
Scraper les sites populaires en quelques clics avec les modèles pré-construits.
Ne se trouver jamais bloqué grâce aux proxies IP et à l’API avancée.
Service Cloud pour programmer le scraping de données.
Quelle est l’utilité du scraping de Google ?
Le scraping de Google permet d’extraire les données des sites web de recherche sans avoir à copier-coller manuellement, ce qui fait gagner un temps précieux.
Il est surtout utilisé pour suivre le positionnement de mots-clés, analyser la visibilité d’un site sur la SERP et surveiller les concurrents. Les données collectées servent aussi à mieux comprendre les intentions de recherche et les tendances du marché, afin d’ajuster plus finement sa stratégie SEO et ses actions marketing.
Google scrapers prêts-à-l’emploi
L’Octoparse template, ce que l’on nommait modèle de web scraping, désigne des modèles préconstruits par l’équipe d’Octoparse qui couvrent les sites les plus visités au monde et les sites pour le référencement professionnel : du réseau social à l’immobilier en passant par l’emploi, la finance, et tant d’autres.
Vu que les modèles sont déjà prêts-à-l’emploi, c’est vraiment très facile de les utiliser. Il suffit aux utilisateurs de saisir quelques mots-clés ou l’URL cible et de cliquer pour démarrer. Par conséquent, ces modèles sont surtout populaires parmi les non-codeurs.
https://www.octoparse.fr/template/google-search-scraper
Si cela vous intéresse, je vous invite à télécharger Octoparse et à essayer le modèle Google Search Scraper ci-dessus pour découvrir les données sur les SERP de Google.
👀 Voici les données que j’ai collectées en 5 minutes :
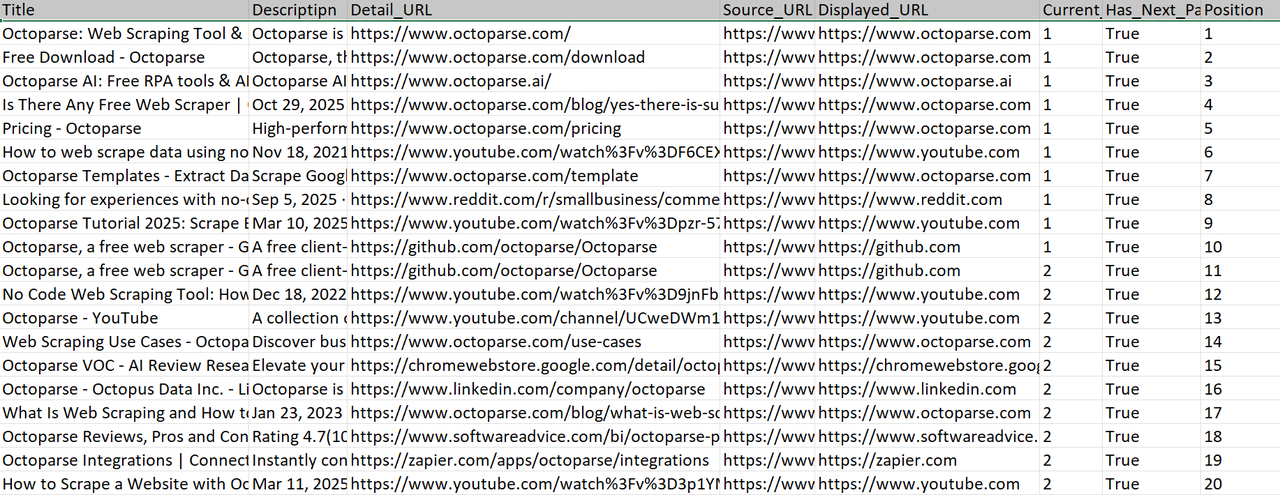
💡Analyse instantanée du Top 5 Google pour vos mots-clés
Quand on travaille son SEO, le plus frustrant est souvent de ne pas savoir rapidement qui occupe les meilleures positions sur ses mots-clés stratégiques, ni à quoi ressemblent exactement ces pages dans Google.
https://www.octoparse.fr/template/google-search-results-scraper
Ce modèle Google SERP scraper (Top 5 results) répond précisément à ce besoin en extrayant automatiquement les 5 premiers résultats des pages de résultats de recherche Google à partir d’une simple liste de mots-clés.
Concrètement, il vous suffit de renseigner vos mots-clés, de lancer le modèle et d’obtenir en quelques minutes un tableau clair avec les URLs et les métadescriptions essentielles des sites qui dominent la SERP, comme le résultat collecté que j’indique ci-dessous :
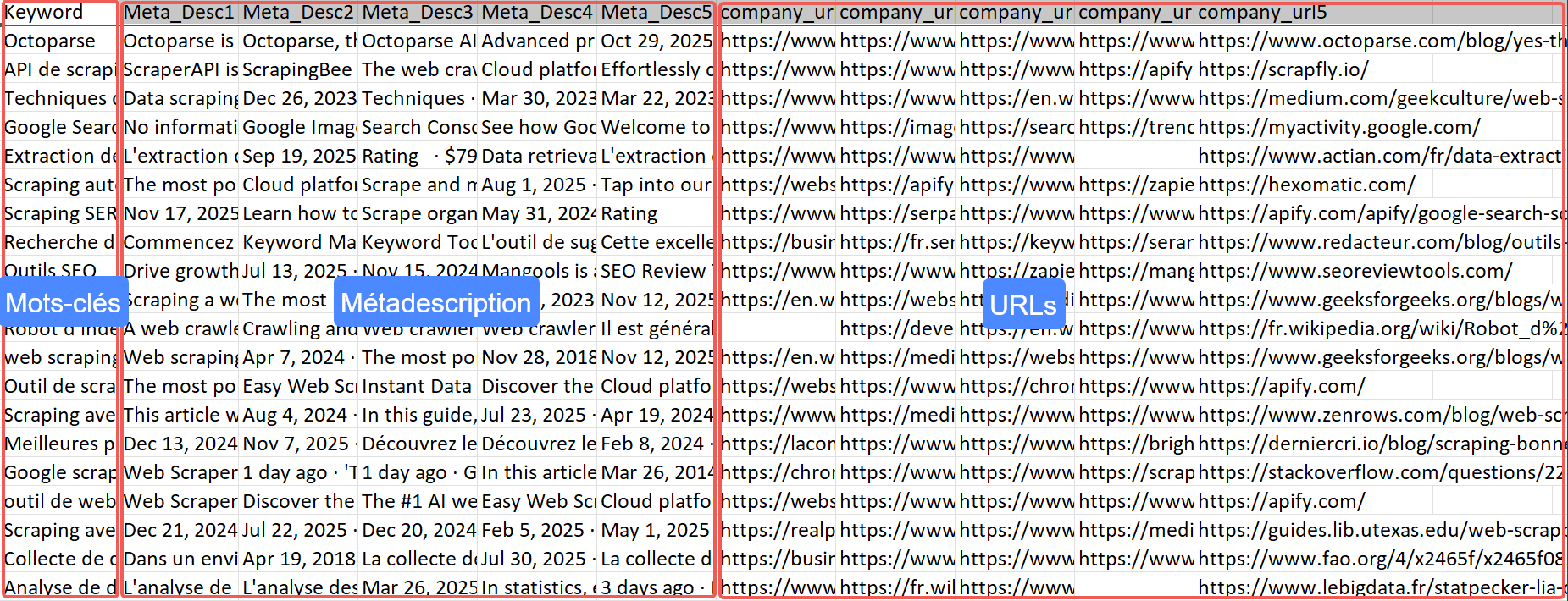
Plus besoin de vérifier manuellement chaque requête une par une : vous gagnez du temps, vous repérez instantanément vos concurrents principaux et vous disposez de données fiables pour ajuster vos contenus, vos balises ou votre stratégie SEO globale.
Comment scraper Google sans coder ?
En effet, il est tout à fait possible de réaliser vous-même un scraper Google, même sans avoir de connaissances en programmation.
La version gratuite d’Octoparse pourrait suffire à la plupart des tâches d’extraction de données simples, mais si vous en avez besoin de manière avancée avec des fonctionnalités particulières comme le Cloud, la programmation de l’extraction ou la rotation des adresses IP, il vous faudra passer à une version payante ou à un service de données.
🙌 Dans la partie suivante, on va voir les étapes simples pour scraper Google GRATUITEMENT :
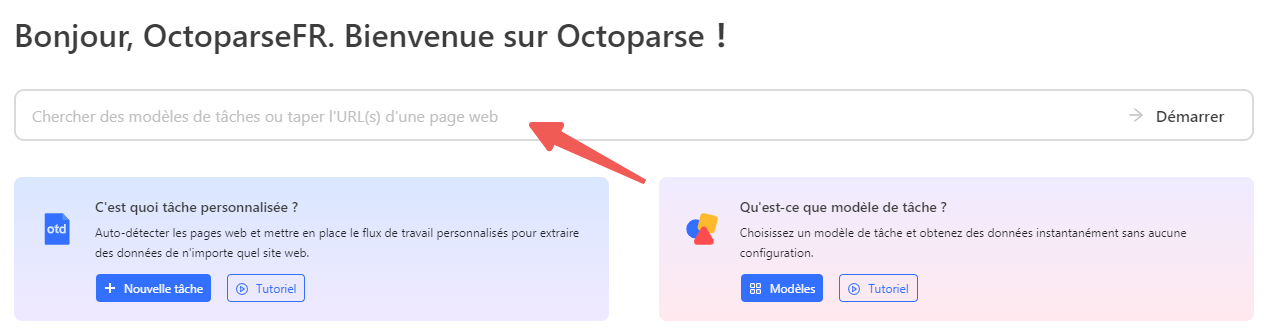
Étape 1 : Ouvrir Octoparse et entrer l’URL
Vous effectuez d’abord une recherche sur Google, puis copiez l’URL dans Octoparse. Par exemple, vous entrez le mot-clé “web scraping” dans Octoparse, puis vous collez l’URL. Octoparse va ensuite vérifier si l’URL est valide ou non.
Étape 2 : Configurer la pagination et l’auto-détection pour parcourir plusieurs pages
En général, vous avez besoin de données qui se répartissent sur plusieurs pages, donc il faut configurer une pagination. Avec la fonction d’auto-détection, Octoparse analysera automatiquement la page web pour détecter les données et les liens de pagination,ce qui permet de générer automatiquement un flux de travail prêt pour l’étape suivante.
🎬 Bien sûr, vous pouvez aussi voir la vidéo ci-dessous pour comprendre le processus :
Étape 3 : Lancer le scraping et exporter les données
Après avoir vérifié toutes les informations, cliquez sur “Exécuter” pour lancer votre propre scraper.
Octoparse propose maintenant deux options pour exécuter les tâches :
L’une est l’exécution sur l’appareil local, où vous devez garder votre appareil allumé tout au long du processus de scraping pour vous assurer que tout se passe comme prévu.
L’autre option est l’exécution sur les serveurs Cloud d’Octoparse. Si vous choisissez cette option, votre tâche sera envoyée sur des serveurs en nuage, qui pourront continuer à fonctionner pour vous 24 heures sur 24.
Une fois la tâche terminée, vous pouvez exporter les données dans un fichier Excel, CSV ou JSON, voire dans une base de données via API.
L’API Octoparse vous permet aussi de réaliser des tâches de scraping, de récupérer vos données et même de gérer vos tâches de manière programmatique en les liant à votre application.
🎯 Consultez la documentation de l’API pour plus de détails.
Google search scraper API
Les outils API sont des applications logicielles qui sont créées pour vous aider à extraire les résultats de recherche en temps réel. Ils peuvent gérer un énorme volume de demandes, et les réponses peuvent être structurées au format JSON, HTML ou CSV.
Ces outils API peuvent gérer les proxys, contourner les CAPTCHAS et analyser toutes sortes de riches données structurées à partir des recherches de Google. Avec API, vous obtiendrez des données avec tous les détails tels que le titre, le lien, la description, la date et la position SERP.
Certaines des API destinées à extraire les résultats de recherche les plus populaires sont :
| Outil | Facilité d’utilisation | Support de volume | Données principales | Coût |
| SERP API | Très simple, bien documenté | Très élevé | Titre, lien, position, description | Payant, selon volume depuis $75 |
| Zen SERP | Facile, interface intuitive | Élevé | Données complètes, détails SEO | 50 recherches gratuitement |
| SERP House | Simple, orienté SEO | Élevé | Résultats riches, analyse approfondie | Essai gratuit pour 200 SERP en direct |
| Data for SEO SERP | Facile, support technique | Élevé | Toutes les infos (date, position, etc.) | Payant |
Scraper Google avec des extensions Chrome
Pour extraire rapidement des SERP sans coder, les extensions Chrome sont une bonne option :
Web Scraper permet de définir une structure de données (sitemap) puis de lancer le scraping directement depuis la page Google pour exporter les résultats vers un fichier CSV ou Excel.
Instant Data Scraper repère automatiquement les tableaux ou listes présents sur la SERP et propose en un clic d’exporter les données, ce qui le rend très pratique pour un usage ponctuel.
Nocoding Data Scraper fonctionne sur le même principe : on lance l’extension depuis la page de résultats, on sélectionne les éléments à capturer (titres, URLs, snippets) et l’outil se charge de les extraire et de les convertir en fichier exploitable.
Même si ces extensions sont très pratiques pour démarrer, elles ont aussi leurs limites. Certaines fonctionnalités avancées ou l’export de gros volumes de données ne sont accessibles qu’avec une offre payante, ce qui peut vite faire grimper la facture.
En cas de bug ou de blocage lié à la structure des pages ou aux protections de Google, il n’y a généralement pas d’équipe technique dédiée pour t’accompagner, ce qui rend la résolution des problèmes plus compliquée pour les utilisateurs non techniques.
Scraping Google avec Python
Si vous êtes à l’aise avec le codage, vous pouvez utiliser Python avec la Beautiful Soup Library pour collecter les résultats de recherche Google. Pour essayer cette méthode, vous devrez d’abord installer le langage Python sur votre ordinateur, au besoin, vous pouvez suivre un tutoriel d’installation de Python.
Et puis, vous devrez installer deux modules, bs4 et requests. bs4 (Beautiful Soup) est une bibliothèque Python utilisée pour lire des données XML et HTML à partir du web. requests est un module qui permet d’envoyer des requêtes HTTP au site web. Vous pouvez installer les deux modules avec la commande suivante dans votre terminal ou invite de commande :
pip install bs4
pip install requests
Une fois les modules bs4 et requests installés, vous pouvez utiliser le code suivant pour extraire les données.
La valeur de la variable de texte dans le code ci-dessous peut être changée.
Par exemple, remplacer text=”web scraping” par text=”octoparse”.
En conclusion
Dans cet article, nous avons présenté quatre méthodes pratiques pour récupérer les résultats de recherche de Google. Pour la plupart des utilisateurs qui ne souhaitent pas coder, les modèles Octoparse restent généralement la solution la plus simple.
J’espère que votre scraping de Google se déroule à merveille ! Si vous rencontrez des problèmes lors de l’utilisation d’Octoparse, n’hésitez pas à contacter notre équipe de support par e-mail à support@octoparse.com.
FAQ
- Qu’est-ce que le Google scraping ?
Le scraping de Google, ou SERP scraping sur Google, consiste à automatiser l’extraction de données à partir des résultats de recherche Google. Cette technique permet de collecter des informations telles que les mots-clés, les liens, les descriptions, et les positions dans la SERP. Elle est principalement utilisée pour analyser le positionnement de sites web, suivre les tendances de recherche, ou réaliser des audits SEO pour améliorer la visibilité en ligne.
- Comment scraper Google Maps ?
Vous pouvez soit copier manuellement les informations des fiches (pratique mais limité), soit utiliser des Google Maps Scrapers sans code sur Octoparse ou avec des extensions dédiées, qui extraient automatiquement les noms, adresses, numéros de téléphone, sites web, notes, etc.
- Comment optimiser le scraping sur Google pour la recherche de mots-clés ?
Il faut configurer votre scraper pour effectuer des recherches régulières, suivre la position des mots-clés, et analyser les tendances. Utiliser des délais entre les requêtes, la rotation IP, et des outils anti-CAPTCHA permet d’obtenir des données précises sans interruption, vital pour une stratégie SEO efficace.