Franchement, j’ai réussi à construire un web crawler et à extraire 20k données du site Web Amazon Jobs quand je débutais dans le scraping. Beaucoup de gens tendant à le considérer comme une tâche compliquée et difficile, mais bien au contaire, c’est simple, facile et ne nécessite aucune connaissance de programmation si vous optez pour des outils de scraping non-codage. Comment configurer un web crawler et créer une base de données qui est à vous gratuitement ? Ici, j’écris un petit tutoriel pour créer un web crawler à partir de zéro, destiné surtout aux débutants. Si vous y êtes intéressé, plongeons-nous dans le vif du sujet.
Qu’est-ce qu’un web crawler ?
Un web crawler est un robot Internet qui indexe le contenu des sites Web. On peut l’utiliser pour extraire automatiquement les informations et les données à partir des sites web et les exporter dans des formats structurés. Le suivant est un vidéo qui explique qu’est-ce que web crawler et clarifie la différence entre web crawler et web scraper.
Quand on parle du web crawler, une des questions auxquelles s’intéressent le plus les gens est que ” le web crawler est-il légal ? “. En effet, ça dépend. Mais d’une manière générale, il est totalement légal de crawler les données publiques dans la plupart de pays.
Pourquoi avez-vous besoin d’un Web Crawler ?
Imaginez que la recherche Google n’existe pas. Combien de temps vous faudra-t-il pour obtenir la recette des pépites de poulet ? Il y a 2,5 quintillions d’octets de données qui sont créées chaque jour. On peut dire qu’il est presque impossible de trouver des informations sans un moteur de recherche comme Google.
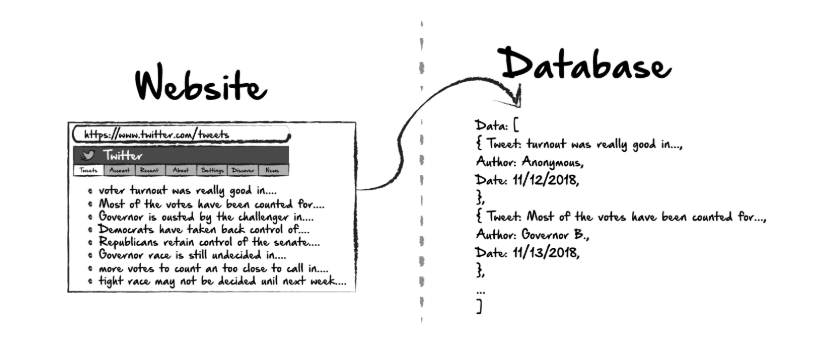
Google Search est un web crawler unique qui indexe les sites Web et trouve la page. Les gens moyens utilisent le web crawler pour régler le besoin d’un grand nombre de données. Il peut être une entreprise qui doit collecter des données à grande échelle avant de les mettre dans l’utilisation ultérieure, il peut être aussi un individu qui a besoin de données pour remplir une tâche importante. Le suivant donne des cas fréquents où un volume immense de données sont nécessaires :
Agrégation de contenu ou d’autres agrégateurs
Un aggrégateur de contenu et d’autres informations consiste à compiler sur une seule plateforme des données sur des sujets de niche à partir de diverses ressources. Dans ce cas, il est nécessaire d’utiliser un web crawler de données pour alimenter votre plate-forme à temps. Certains collectent les données d’emploi pour créer un jobboard de niche pour une certaine industrie spécifique, d’autres collectent les données de prix de billets d’avion ou de hôtels pour créer un comparateur de prix, etc.
On l’appelle également “opinion mining”. Comme son nom l’indique, il s’agit du processus d’analyser les opinions du public à l’égard d’un produit et d’un service. Une évaluation précise des sentisments doit être basée sur un grand nombre de données. Pour ce faire, vous pouvez utiliser un web crawler pour extraire des tweets, des commentaires ou avis clients laissés sur des sites d’e-commerce, des commentaires Youtube pour comprendre ce que disent les consommateurs ou l’audience.
Chaque entreprise a besoin de prospects. Supposons que vous envisagiez de faire une campagne marketing ciblant un groupe spécifique et que vous devriez récupérer les e-mails, les numéros de téléphone et les profils publics d’un exposant ou d’une liste de participants à des salons.
En tout cas, le web crawler est un outil d’extraction de données, les données extraites avec le web crawler sont des ressources à exploiter. C’est à vous d’y fouiller de la valeur et d’en profiter pour apporter de la croissance à votre entrerprise.
Créer un web crawler avec Python ou d’autres langages de script
Les programmeurs écrivant des scripts pour construire un web crawler et il peut être aussi puissant que vous le créez. Voici un exemple d’extrait de code de bot.

De Kashif Aziz
Créer un web crawler avec Python en trois étapes
1. Envoyer une requête HTTP à l’URL de la page Web. Il répond à votre requête en renvoyant le contenu des pages Web.
2. Analyser la page Web. Un parser (analyseur) créera une structure arborescente du HTML puisque les pages Web sont entrelacées et imbriquées. Une arborescence aidera le bot à suivre les chemins que nous avons créés et à naviguer pour obtenir les informations.
3. Utiliser la bibliothèque python pour rechercher l’arborescence.
Parmi les langages de programmation qui peuvent être utilisés dans la création d’un web crawler, Python est plus facile par rapport à PHP et Java. Mais, il y a toujours une courbe d’apprentissage abrupte qui empêche de nombreux non-codeurs de l’utiliser.
Utiliser outil de scraping Nocode pour contruire un web crawler gratuitement
Si vous ne savez pas grand chose sur la programmation, ne vous inquiétez pas puisqu’il y a de nomrbreux outils de scraping Nocode, parmi lesquels je recommande surtout Octoparse qui simule la navigation humaine et applique une interface de type pointer-cliquer, rendant l’utilisation très simple et facile à comprendre.
Ici, voyons comment créer un web crawler pour extraire des données depuis Amazon Jobs avec Octoparse pour voir si les étapes sont assez faciles pour que vous pourriez créer vous-même un crawler en peu de temps.
Préparations
Télécharger et installer Octoparse sur votre ordinateur pour suivre les étapes suivtantes.
Objectif
Créer un crawler pour extraire les postes d’emploi, y compris le titre du poste, l’identifiant du poste, la description, la qualification de base, la qualification prioritée et l’URL de la page.
URL https://www.amazon.jobs/en/job_categories/administrative-support
Guide étape-par-étape
- Entrez l’URL dans la barre de recherche d’Octoparse et puis cliquez “Start”
Ici, on n’utilise pas la fonction d’auto-détection ni les modèles pré-construits dans Octoparse, qui faciliteront davantage la tâche de scraping. Dans les étapes suivantes, on va configurer un web crawler par lui-même.
- Configurez la pagination : les données d’offres d’emploi s’étalent sur plusieurs pages. Donc nous devons configurer la pagination afin que le crawler puisse naviguer sur plusieurs pages. Pour ce faire, cliquez sur le bouton de page suivante et sélectionnez «Loop click single bouton» dans le panneau d’astuces. C’est fait !
- Comme nous voulons cliquer sur chaque case, nous devons créer une boucle pour que le robot clique les cases l’une après l’autre. Pour ce faire, cliquez sur la première offre d’emploi et puis la deuxième. Octoparse identifiera toutes les autres offres d’emploi dans la liste. La liste sera surlignée en vert, et là, choisissez «Loop click each element» dans le panneau des astuces d’action. Jusque là, la boucle est créée avec succès.
- Maintenant, nous sommes sur la page de détails, et nous devons dire au robot d’exploration les données dont on a besoin. Cliquez sur le titre du poste et sélectionnez «Extract text of the selected element» dans le panneau des astuces. Comme suit, répétez cette étape pour récupérer ID du poste, description, qualification de base, qualification prioriée et URL de la page.
- Une fois la configuration de crawler terminée, cliquez sur «Save and run» pour le lancer.
Pour les logiciels SaaS, les nouveaux utilisateurs doivent suivre une formation avant de profiter pleinement des avantages. Quand Octoparse travaille dûr pour faciliter le web scraping avec l’auto-détection et le mode de template, l’équipe ne manque jamais d’aider les utilisateurs découvrir au maximun la puissance de l’outil avec son riche tutoriel et des sessions de formation.
En conclusion
L’écriture de scripts peut être pénible, tenu compte des coûts initiaux et de maintenance continue. Aucune page Web n’est identique et nous devons écrire un script pour chaque site. En outre, les sites Web modifient probablement sa mise en page et sa structure. Ce n’est pas durable si vous devez explorer de nombreux sites Web. En comparant avec les scripts, l’outil de Web scraping est plus pratique pour l’extraction de données au niveau de l’entreprise avec moins d’efforts et de coûts.




