Vous passez des heures à copier-coller des prix, des annonces ou des contacts depuis des sites web ? C’est exactement le problème que le web scraping résout, et en 2026, vous n’avez plus besoin de coder pour le faire. Des outils NOCODE permettent aujourd’hui aux équipes marketing, e-commerce et data en France de récupérer automatiquement les données dont elles ont besoin, en quelques clics, et dans le respect du RGPD.
Ce guide passe en revue 6 méthodes concrètes pour extraire les données d’un site web, des plus accessibles (extensions navigateur, outils NOCODE) aux plus puissantes (Python, IA), avec pour chacune les cas d’usage réels, les avantages et les limites. Responsable e-commerce, analyste data ou consultant : il y a forcément une approche qui correspond à votre situation.
Qu’est-ce que le web scraping et en quoi est-ce différent d’aspirer un site ?
Le web scraping, aussi appelé extraction web ou moissonnage de données, désigne l’ensemble des techniques permettant de récupérer automatiquement des données structurées depuis des pages web : prix, annonces, avis clients, coordonnées, offres d’emploi, etc. Le but : transformer du contenu HTML brut en données exploitables dans un tableur ou une base de données.
Deux termes proches prêtent souvent à confusion :
| Terme | Ce que ça désigne | Exemples d’outils |
| Aspirer un site | Télécharger un site entier en local pour le consulter hors ligne (copie miroir) | HTTrack, WebCopy, Wget |
| Scraper / extraire des données | Récupérer des données précises et structurées d’un site pour les analyser | Octoparse, ParseHub, Python/BeautifulSoup |
Si vous cherchez à télécharger un site complet en local, consultez notre guide dédié : Meilleurs aspirateurs de site web 2026. Si en revanche vous souhaitez extraire des données spécifiques (prix, leads, annonces…), vous êtes au bon endroit.
Les secteurs où l’extraction de données fait toute la différence
Le web scraping n’est pas réservé aux data scientists. Voici comment il s’applique concrètement dans les entreprises françaises :
E-commerce et retail
Les équipes pricing de Cdiscount, Fnac ou Boulanger utilisent le scraping pour surveiller les prix de la concurrence en temps réel. Un outil comme Octoparse peut collecter automatiquement les tarifs de milliers de produits chaque jour, sans aucun code.
Immobilier : la « pige immobilière »
La pige immobilière, c’est-à-dire la collecte automatisée des annonces sur Leboncoin, SeLoger ou PAP, est l’un des cas d’usage les plus répandus en France. Les agents immobiliers et les investisseurs s’en servent pour repérer les nouvelles opportunités en temps réel. À noter : la CNIL a des recommandations spécifiques sur cette pratique, notamment l’obligation de respecter les CGU des plateformes.
👇 Octoparse template Leboncoin prêt à l’emploi vous permet d’automatiser la pige immobilière et de repérer les nouvelles annonces sans effort :
Génération de leads B2B
Extraire des informations de contact depuis des annuaires professionnels comme Pages Jaunes, des répertoires d’entreprises ou LinkedIn (dans le respect strict des CGU) permet d’alimenter votre CRM en prospects qualifiés, sans les interminables copier-coller.
Emploi et RH
Agréger les offres d’emploi depuis France Travail (ex-Pôle Emploi), Welcome to the Jungle ou LinkedIn permet aux équipes RH d’analyser les tendances de recrutement, de benchmarker les salaires ou de veiller sur les mouvements de la concurrence.
Analyse de marché et veille concurrentielle
Les équipes marketing utilisent le scraping pour suivre les avis clients sur Google My Business, Trustpilot ou les réseaux sociaux, détecter les tendances émergentes et produire des rapports de veille automatisés.
Recherche académique
Dans le monde universitaire français, le scraping facilite l’accès à de grands corpus de données textuelles pour les études en sciences sociales, linguistique ou économie. Cette pratique s’inscrit dans le cadre de l’exception légale de « fouille de textes et de données » prévue par le Code de la propriété intellectuelle.
👀 Aller plus loin :
Ce qu’il faut vérifier avant le web scraping
Avant de lancer votre premier scraping, voici les étapes à ne pas sauter :
- Vérifiez les CGU du site cible — cherchez les clauses relatives au scraping, crawling ou extraction de données automatisée
- Consultez le fichier robots.txt — accessible via l’URL [domaine]/robots.txt, il indique les pages que vous ne devez pas crawler
- Vérifiez l’existence d’une API officielle — si le site propose une API (Twitter/X, LinkedIn, Google Maps Platform…), préférez-la : c’est plus stable et juridiquement plus sûr
- Définissez précisément vos données cibles — quelles informations, sur quelle période, dans quel format de sortie (CSV, Excel, JSON, Google Sheets)
- Limitez la fréquence de vos requêtes — ajoutez des délais entre les requêtes pour ne pas surcharger les serveurs et éviter d’être bloqué
- Évaluez si une AIPD est nécessaire — si vous collectez des données personnelles à grande échelle, une Analyse d’Impact relative à la Protection des Données peut être obligatoire
Comment choisir votre outil d’extraction web ?
Il n’existe pas d’outil universel. Le choix dépend de trois facteurs :
- Votre niveau technique : êtes-vous à l’aise avec le code ou préférez-vous une interface visuelle ?
- Le volume de données : quelques centaines de lignes ponctuellement ou des millions de records en continu ?
- La fréquence : extraction unique ou planification automatique (quotidienne, hebdomadaire) ?
| Votre situation | Outil recommandé | Pourquoi |
| Débutant, pas de code | Octoparse, ParseHub | Interface point-and-click, modèles pré-construits, idéal pour démarrer rapidement |
| Extraction ponctuelle depuis le navigateur | Data Miner, Web Scraper (extension Chrome) | Installation en 2 minutes, parfait pour des tâches rapides |
| Données en temps réel, via API officielle | API Octoparse, API tierce du site | Fiabilité maximale, données structurées, conformité garantie |
| Grand volume, automatisation avancée | Python (BeautifulSoup, Scrapy) | Flexibilité totale, pas de limites de volume |
| Sites complexes (JS dynamique, anti-bot) | Octoparse Cloud, solutions IA (Browse.ai) | Gestion native des CAPTCHAs, rotation IP, adaptation automatique |
💡 Dans la majorité des situations, commencer avec la version gratuite d’Octoparse est la voie la plus rapide. Si vos besoins dépassent ses capacités, Python ou une solution cloud constituera l’étape suivante logique.

Transformer les sites web vers Excel, CSV, Google Sheets ou base de données.
Auto-détecter les sites Web et extraire les données sans aucun codage.
Scraper les sites populaires en quelques clics avec les modèles pré-construits.
Ne se trouver jamais bloqué grâce aux proxies IP et à l’API avancée.
Service Cloud pour programmer le scraping de données.
Les 6 méthodes les plus rapides pour extraire les données d’un site web
Méthode 1 Outils de scraping prêts à l’emploi
En 2026, extraire des données ne demande plus aucune compétence en programmation. Les outils NOCODE permettent à n’importe quel responsable marketing, analyste ou entrepreneur de collecter des données structurées en quelques clics, via une interface visuelle, sans toucher à une seule ligne de code.
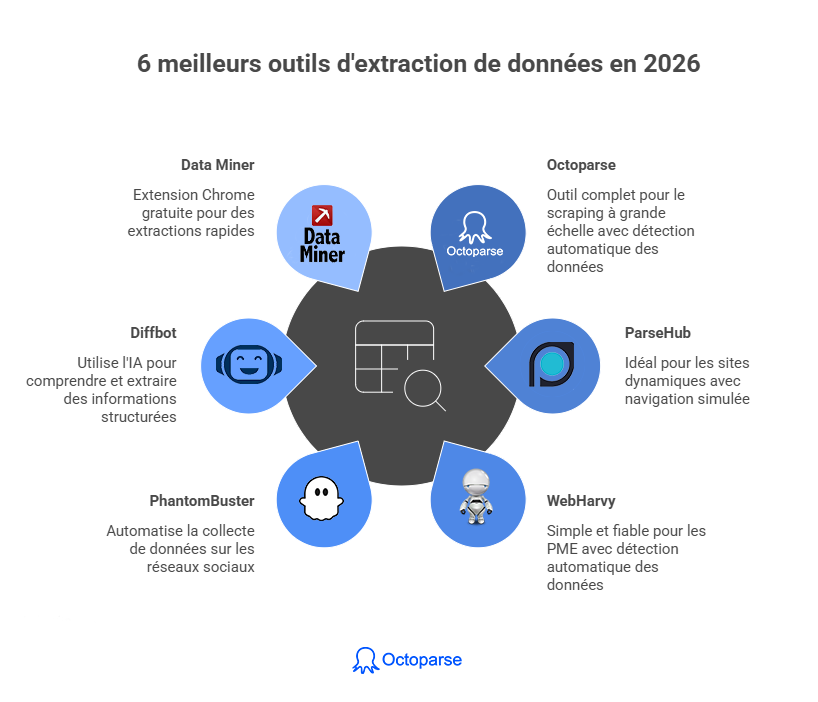
N’hésitez pas à utiliser cette infographie sur votre site, en mentionnant la source, et à insérer un lien vers notre blog à l’aide du code d’intégration ci-dessous :
Octoparse
L’outil le plus complet pour le scraping NOCODE à grande échelle. Octoparse propose une détection automatique des données, plus de 500 modèles pré-construits (Amazon, LinkedIn, Leboncoin, SeLoger…) et un mode cloud pour planifier vos extractions 24h/24. Ses mécanismes anti-blocage (rotation IP, gestion des CAPTCHAs) le distinguent de la concurrence sur les sites complexes. Interface disponible en français.
ParseHub
Idéal pour les sites dynamiques (chargement JavaScript, pagination infinie). ParseHub excelle pour des projets qui nécessitent une navigation simulée : cliquer sur des boutons, remplir des formulaires, parcourir plusieurs niveaux de pages. Version gratuite disponible pour des projets de petite taille.
WebHarvy
Simple, fiable, sans configuration complexe. WebHarvy convient parfaitement aux PME qui ont besoin d’extraire régulièrement des données depuis des sites statiques ou semi-dynamiques. Sa détection automatique des données à extraire raccourcit significativement le temps de configuration.
PhantomBuster
Incontournable dans les équipes commerciales et marketing françaises, PhantomBuster automatise la collecte de données sur les réseaux sociaux (LinkedIn, Instagram, Twitter/X) et les plateformes professionnelles. Son vrai atout : enchaîner les actions en un seul workflow, de la collecte à l’enrichissement jusqu’à l’injection dans votre CRM.
Diffbot
Diffbot se distingue par son approche IA : il comprend le contenu des pages web comme un humain et extrait automatiquement les informations structurées sans configuration manuelle. Idéal pour des extractions à grande échelle sur des sites très variés. Solution premium, particulièrement adaptée aux équipes data en entreprise.
Data Miner
Extension Chrome gratuite et légère, Data Miner permet d’extraire rapidement des données depuis votre navigateur sans installation complexe. Ses recettes pré-configurées pour des centaines de sites populaires (Google, LinkedIn, Amazon) permettent de démarrer en moins de 5 minutes. Idéal pour des extractions ponctuelles.
🎯 Testez Octoparse gratuitement pendant 14 jours : plus de 500 modèles prêts à l’emploi pour extraire des données depuis LinkedIn, Leboncoin, Pages Jaunes, Amazon et bien d’autres, sans écrire une seule ligne de code. Aucune carte bancaire requise.
Pour aller plus loin, voici un modèle prêt à l’emploi pour extraire des offres d’emploi LinkedIn sans configuration et sans connexion requise :
https://www.octoparse.fr/template/linkedin-job-search-scraper-by-url
Méthode 2 Extensions Chrome pour récupérer les données depuis le navigateur
Pour des extractions rapides et ponctuelles, les extensions Chrome sont souvent la solution la plus immédiate. Pas d’installation logicielle, pas de configuration complexe : vous installez l’extension, vous naviguez jusqu’à la page cible, et vous exportez vos données.
Les extensions les plus utilisées dans l’écosystème français :
- Data Miner — gratuit, intuitif, idéal pour les débutants
- Web Scraper — open source, très complet, communauté active, disponible sur Chrome et Firefox
- Instant Data Scraper — détection automatique des tableaux et listes sur n’importe quelle page
- PhantomBuster Chrome Extension — pour l’automatisation sur LinkedIn et les réseaux sociaux
Limite principale : ces extensions ne sont pas adaptées aux gros volumes de données ou à l’automatisation planifiée. Pour aller plus loin, une solution cloud comme Octoparse sera nécessaire.
Méthode 3 Exploiter les API officielles
Quand elle existe, l’API officielle d’un site est toujours la méthode la plus fiable et la plus sûre juridiquement. Elle garantit :
- Des données structurées, propres et à jour
- Une extraction contrôlée et dans les limites autorisées
- Une conformité RGPD simplifiée (le site gère lui-même les droits d’accès)
En France, des plateformes comme LinkedIn, Twitter/X, Google Maps Platform, Trustpilot ou encore Idealo proposent des API dont les conditions d’accès varient. Certaines sont gratuites jusqu’à un certain volume, d’autres sont payantes ou réservées aux partenaires.
💡 Besoin d’automatiser votre extraction via API ?
Consultez notre Documentation API Octoparse ou contactez notre équipe à support@octoparse.com
Méthode 4 Applications de collecte et d’analyse de données
Au-delà des outils de scraping purs, plusieurs applications métier permettent de collecter des données en ligne dans le cadre d’une analyse plus large :
- Veille e-réputation : Talkwalker, Mention, Brandwatch — pour suivre les mentions de votre marque en temps réel
- Analyse d’audience : Google Analytics 4, AT Internet/Piano Analytics — pour comprendre le comportement des visiteurs
- Visualisation de données : Power BI, Google Looker Studio (gratuit), Tableau — pour transformer vos données scrapées en tableaux de bord
- Intégration et enrichissement : Google Sheets, Airtable — pour stocker et partager facilement les données collectées
🕵️ Pour aller plus loin : Comment extraire des données d’une page web vers Excel
Méthode 5 Coder votre propre extracteur (Python)
Pour les équipes techniques qui ont besoin d’une flexibilité maximale ou de traiter des volumes importants, Python reste le langage de référence pour le web scraping en 2026, et rien ne laisse penser que ça va changer de sitôt.
Les bibliothèques essentielles :
- BeautifulSoup — le point d’entrée idéal pour parser du HTML. Simple à apprendre, parfait pour les sites statiques
- Requests — pour effectuer les requêtes HTTP et récupérer le code source des pages
- Scrapy — framework complet pour le crawling à grande échelle, asynchrone et très performant
- Selenium / Playwright — pour les sites avec JavaScript dynamique (SPA, chargement AJAX, infinite scroll)
Récupérer les prix et la disponibilité de produits sur Fnac avec BeautifulSoup, c’est une vingtaine de lignes de Python. Le workflow type suit toujours la même logique : on envoie d’abord une requête HTTP vers la page cible, on parse ensuite le code HTML avec BeautifulSoup pour en extraire les données souhaitées (prix, titres, liens…), puis on exporte le tout en CSV ou on l’injecte directement dans une base de données. Les sites comme Fnac ou Cdiscount disposent de protections anti-bot, ce qui nécessite souvent d’ajouter une gestion des délais et des en-têtes HTTP réalistes.
⚠️ Limite importante : coder son propre extracteur demande du temps de développement et de maintenance. Pour 90 % des cas d’usage professionnels, un outil NOCODE comme Octoparse sera 5 à 10 fois plus rapide à déployer.
Méthode 6 Solutions IA pour le web scraping nouvelle génération
Les scrapers IA changent concrètement la donne sur un point précis : ils n’ont pas besoin qu’on leur explique la structure d’un site pour fonctionner. Là où un outil classique exige une configuration manuelle, un outil IA analyse la page, identifie les données et s’adapte automatiquement si la structure évolue.
Octoparse (mode détection IA) : sans aucune configuration manuelle, Octoparse analyse la structure de la page et identifie les données à extraire en un clic. En mode cloud, il prend en charge les blocages IP et les CAPTCHAs en temps réel. Pour les équipes qui ne veulent pas gérer d’infrastructure technique, c’est généralement le point de départ le plus direct.
Autres solutions IA notables :
- Browse.ai — le plus simple : décrivez en langage naturel ce que vous voulez extraire, l’IA configure le scraper. Idéal pour la veille et le monitoring
- Kadoa — spécialisé dans l’extraction intelligente pour l’e-commerce et les marchés financiers. L’IA détecte automatiquement les données pertinentes même sur des sites non structurés
- Scrapestorm — combine scraping et IA pour extraire des données depuis des sites difficiles d’accès, avec une interface visuelle intuitive
Tableau comparatif des méthodes d’extraction web
| Méthode | Niveau requis | Avantages | Inconvénients | Volume idéal | Conformité RGPD |
| Outils NOCODE | Débutant | Rapide, intuitif, modèles prêts à l’emploi | Moins flexible pour les besoins très spécifiques | Faible à fort | Native si outil conforme |
| Extensions Chrome | Débutant | Zéro installation, immédiat | Pas d’automatisation avancée | Faible | À vérifier selon l’outil |
| API officielle | Intermédiaire | Fiabilité maximale, données structurées | Accès restreint, parfois payant | Moyen à fort | Optimale |
| Applications d’analyse | Débutant à intermédiaire | Visualisation, reporting, veille | Collecte limitée, souvent complémentaire | Variable | Dépend de l’outil utilisé |
| Python / Code | Avancé | Flexibilité totale, pas de limite de volume | Temps de dev, maintenance nécessaire | Fort à très fort | Selon implémentation |
| Solutions IA | Débutant à intermédiaire | Adaptation automatique, sites complexes | Coût plus élevé | Moyen à fort | Généralement |
Le web scraping est-il légal en France ?
La réponse courte : oui, dans la grande majorité des cas professionnels, à condition de respecter quelques règles claires.
Ce que dit le cadre juridique français
En France, le web scraping de données publiquement accessibles est légal, sous réserve de respecter trois cadres juridiques essentiels :
- Le RGPD (Règlement Général sur la Protection des Données) : protège les données à caractère personnel des personnes physiques
- Les CGU (Conditions Générales d’Utilisation) des sites : certains sites interdisent explicitement le scraping dans leurs CGU
- Le droit de la propriété intellectuelle : protège le contenu créatif des sites et les bases de données des éditeurs
La position de la CNIL en 2025 : ce qui change
📌 Le 19 juin 2025, la CNIL a publié ses nouvelles recommandations sur ce qu’elle appelle le « moissonnage de données ». Ce que ça change concrètement pour votre activité :
- L’intérêt légitime peut être invoqué comme base légale pour scraper des données personnelles, à condition de :
- Respecter les fichiers robots.txt et les signaux techniques d’opposition
- Exclure les données sensibles (santé, religion, opinions politiques…)
- Informer les personnes concernées et permettre le droit d’opposition
- Ne pas cibler des sites composés principalement de données personnelles
- Les sanctions en cas de non-conformité : jusqu’à 20 millions € ou 4 % du chiffre d’affaires annuel mondial (Article 83-5 du RGPD)
- Cas concrets de sanctions en France : la CNIL a sanctionné Clearview AI pour collecte massive de photos via scraping sans base légale, et a mis en demeure des acteurs de la prospection B2B pour avoir collecté des coordonnées LinkedIn sans respecter les attentes raisonnables des personnes concernées
En pratique, pour un usage professionnel courant : veille tarifaire, analyse concurrentielle, génération de leads sur données publiques : le web scraping est parfaitement légal, à condition d’utiliser un outil respectant les CGU et de ne pas collecter de données personnelles sensibles.
💡 Bonne pratique : privilégiez un outil qui respecte automatiquement les fichiers robots.txt et gère la fréquence des requêtes pour ne pas mettre à rude épreuve les serveurs cibles. Octoparse intègre ces mécanismes de protection par défaut, ce qui évite les mauvaises surprises lors de vos premières extractions.
Conseils pratiques pour éviter les erreurs courantes
Selon votre profil :
- Débutant ou projet ponctuel : commencez avec un outil NOCODE (Octoparse version gratuite ou extension Chrome). Testez sur un petit volume avant de passer à l’automatisation.
- Volumes importants ou automatisation régulière : optez pour Octoparse Cloud. La plateforme gère nativement la rotation IP, les CAPTCHAs et la planification des tâches, sans que vous ayez à maintenir quoi que ce soit.
- Données en temps réel ou intégration CRM : privilégiez les API officielles ou l’API Octoparse. Une connexion API est plus stable, moins sujette aux interruptions liées aux changements de structure des sites, et plus simple à faire évoluer dans la durée.
Les erreurs à éviter absolument :
- Ne pas vérifier les robots.txt : vous risquez un blocage immédiat ou des poursuites pour extraction non autorisée
- Envoyer trop de requêtes trop rapidement : résultat quasi certain, le ban d’IP, et dans les cas les plus graves, une mise en cause pour surcharge intentionnelle de serveur
- Collecter des données personnelles sans base légale valide : une amende RGPD pouvant atteindre 20 M€, comme l’ont expérimenté plusieurs acteurs B2B français
- Ne pas anticiper les changements de structure des sites : votre extracteur peut tomber en panne du jour au lendemain si la page cible évolue
En conclusion
En 2026, extraire les données d’un site web ne nécessite plus ni compétences en programmation, ni budget important. Que vous ayez besoin d’extraire vos premières données en 10 minutes ou d’automatiser des millions de records par jour, les six méthodes présentées ici couvrent la majorité des situations rencontrées par les équipes françaises.
Pour les équipes marketing, e-commerce, RH ou les consultants indépendants, un outil NOCODE comme Octoparse reste le choix le plus cohérent : simple à prendre en main, suffisamment puissant pour la plupart des cas, et conçu pour fonctionner dans le respect du RGPD.
Prêt à extraire vos premières données ? La version gratuite d’Octoparse est accessible sans carte bancaire, avec plus de 500 modèles prêts à l’emploi pour démarrer en quelques minutes.
FAQ — Questions fréquentes sur l’extraction de données web
- Quelle est la différence entre « aspirer » et « scraper » un site web ?
Aspirer un site (avec des outils comme HTTrack) revient à télécharger une copie complète du site pour le consulter hors ligne, un peu comme prendre une photo d’une vitrine. Scraper un site, c’est en revanche extraire des données précises et structurées (prix, contacts, annonces…) pour les analyser dans un tableur ou une base de données. Deux usages radicalement différents.
- Le web scraping est-il légal en France en 2026 ?
Oui, dans la grande majorité des cas professionnels. Le web scraping de données publiques est légal à condition de respecter les CGU du site, le fichier robots.txt, et le RGPD pour les données personnelles. En juin 2025, la CNIL a confirmé que l’intérêt légitime peut servir de base légale pour scraper des données personnelles, sous réserve de respecter des conditions précises détaillées dans la section dédiée dans cet article.
- Comment extraire des données sans logiciel ni compétences en programmation ?
Les extensions Chrome comme Data Miner ou Instant Data Scraper permettent d’extraire des données directement depuis votre navigateur, sans rien installer. Pour des projets plus complets, Octoparse propose une version gratuite avec une interface visuelle entièrement en français, où il suffit de cliquer sur les éléments à extraire, sans écrire une seule ligne de code.
- Qu’est-ce que le « moissonnage de données » selon la CNIL ?
C’est le terme officiel utilisé par la CNIL pour désigner le web scraping. La CNIL a publié en juin 2025 ses recommandations sur le moissonnage dans le cadre du développement de systèmes d’IA. Ces recommandations s’appliquent également aux entreprises qui collectent des données personnelles par scraping pour leurs bases de données commerciales.
- Pourquoi mon scraper est-il bloqué ? Comment éviter le ban IP ?
La plupart des sites mettent en place des protections anti-bot (Cloudflare, CAPTCHAs, analyse comportementale) pour détecter et bloquer les scrapers trop agressifs. Quatre réflexes permettent de limiter ce risque : respecter les délais entre les requêtes, utiliser la rotation d’adresses IP, simuler un comportement de navigation réaliste (user-agent approprié, défilement progressif) et toujours vérifier le fichier robots.txt avant de démarrer. Sur les sites les plus protégés, un outil comme Octoparse Cloud gère ces contraintes nativement, sans configuration supplémentaire de votre part.



