De nos jours, les réseaux sociaux sont devenus un véritable baromètre de l’opinion publique. Sur ces plateformes, les internautes expriment librement leurs idées, leurs opinions et leurs réactions face à l’actualité. Cette abondance de données représente une mine d’informations précieuse pour différents acteurs.
Dans le domaine de la recherche académique, l’analyse des tweets peut alimenter des études approfondies sur les tendances sociales, les mouvements de foule ou encore les perceptions du public. Les chercheurs peuvent ainsi mieux comprendre les comportements et les dynamiques sociales.
Du côté des professionnels, le scraping de tweets offre de nombreuses possibilités. Les marketeurs peuvent s’en servir pour surveiller l’image de leur marque, identifier des cibles publicitaires pertinentes ou encore épier les stratégies de la concurrence. Cette pratique permet de recueillir une grande quantité de données de manière structurée et exploitable.
Plutôt que de parcourir manuellement tweet après tweet, il existe des moyens plus efficaces de récupérer ces informations à grande échelle. Dans cet article, je vous montrerai comment scraper des tweets de façon simple et rapide, en 5 minutes chrono !
Meilleur outil NOCODE pour le scraping de Twitter
Bien que le scraping de tweets puisse sembler complexe de prime abord, il existe aujourd’hui des outils qui permettent à tout le monde de réaliser cette tâche sans aucune compétence en programmation.
Parmi ces outils, Octoparse se démarque particulièrement pour sa simplicité d’utilisation et sa puissance.
Dans cette partie, je vais vous présenter en détail les principales fonctionnalités de cet outil et vous guider pas à pas dans le processus de scraping de tweets. Que vous soyez un professionnel du marketing, un chercheur académique ou simplement curieux, cet outil saura répondre à vos besoins en matière d’analyse des réseaux sociaux.
Octoparse est réputé pour être facile à utiliser, mais puissant dans l’extraction de donnéess. Comme Octoparse simule l’interaction humaine avec une page Web, il vous permet d’extraire toutes les informations que vous voyez sur n’importe quel site Web, comme Twitter. Par exemple, vous pouvez facilement extraire les tweets, les hashtags, la date de publication, le nombre de Aimer, de commentaires et ses contenu.
Ce logiciel a servi des millions d’utilisateurs par ses avantages :
- Facile à utiliser grâce à son UI intuitive
- Détection automatique de la structure des pages Web
- 400+ modèles de web scraping accessibles couvrant les sites les plus populaires
- Cloud service accessible
- Aucune limite dans le nombre de données extraites
- Programmation de scraping
- Exportation automatique de données
- Essai gratuit de 14 jours des plans premium
- Version gratuite accessible
Que vous soyez un professionnel en quête d’informations sur votre marché, un chercheur académique désireux d’alimenter vos travaux, ou simplement un curieux intéressé par l’analyse des réseaux sociaux, je vous encourage vivement à tester cet outil.
N’hésitez pas à vous lancer dès maintenant ! Vous découvrirez rapidement comment Octoparse peut booster votre veille stratégique, affiner votre ciblage publicitaire ou enrichir vos recherches. Prêt à relever le défi du scraping de tweets sans coder ?
Scraper des tweets sur Twitter avec Octoparse
Octoparse propose deux modes de tâches de scraping, l’une c’est personnaliser une tâcher de scraping à partir de zéro et l’autre consiste à utiliser directement les modèles prêts à l’emploi. Quand le premier mode offre plus de flexibilité pour répondre aux besoins spécifiques, les modèles ciblent les sites les plus populaires au monde, comme Twitter, permettant de récupérer les données depuis ces sites en entrant seulement les paramètres tels que les mots-clé ou les URLs.
Pourquoi pas télécharger l’outil et l’installer sur votre ordinateur maintenant, et puis suivre les étapes suivantes pour scraper les données Twitter.
Utiliser Twitter Scrapers prêts à l’emploi
Pour le scraping de Twitter, Octoparse propose plusieurs scrapers dont les saisies se diffèrent : via hashtags, via mot-clé ou via URL de résultat de recherche. Il vous faut démêcher votre projet de données d’abord et puis aller trouver le modèle qui correpond le mieux à votre besoin.
Par ici, on va voir comment récupérer les tweets avec le modèle intitulé Tweets & Commentaires Scraper (via URL de recherche)
https://www.octoparse.fr/template/tweets-comments-scraper-by-search-result-url
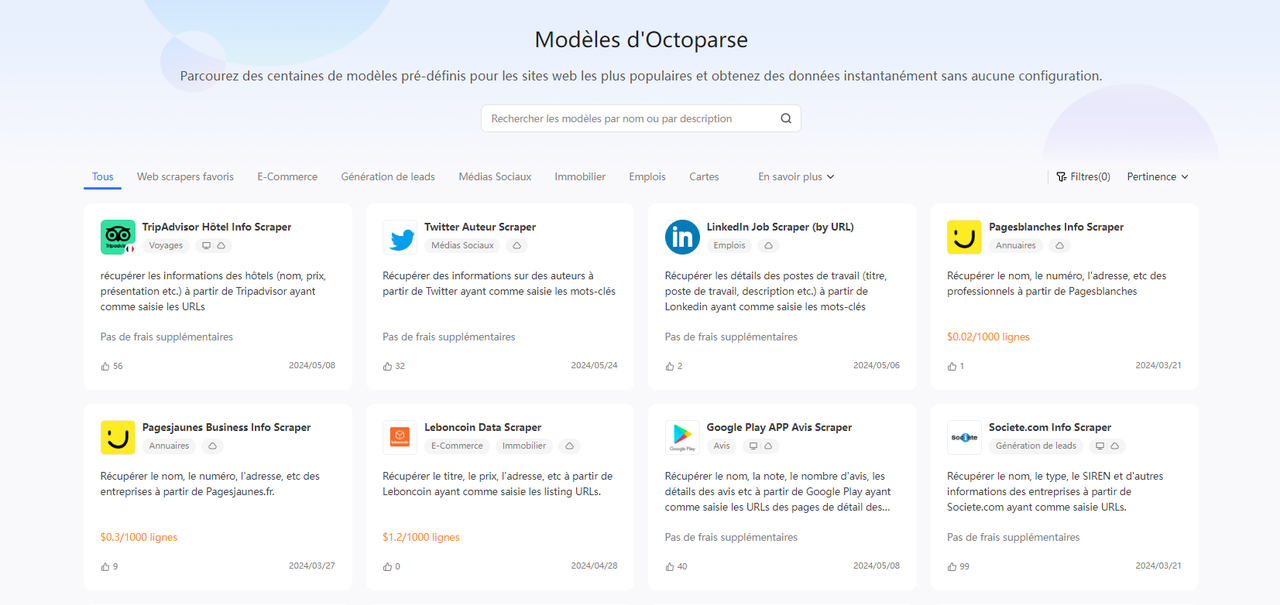
Étape 1 – Trouver le modèle cible
L’ensemble des modèles accessibles peuvent être explorés dans l’application ou sur notre site web. Vous pouvez rechercher par catégories ou par mots-clés.
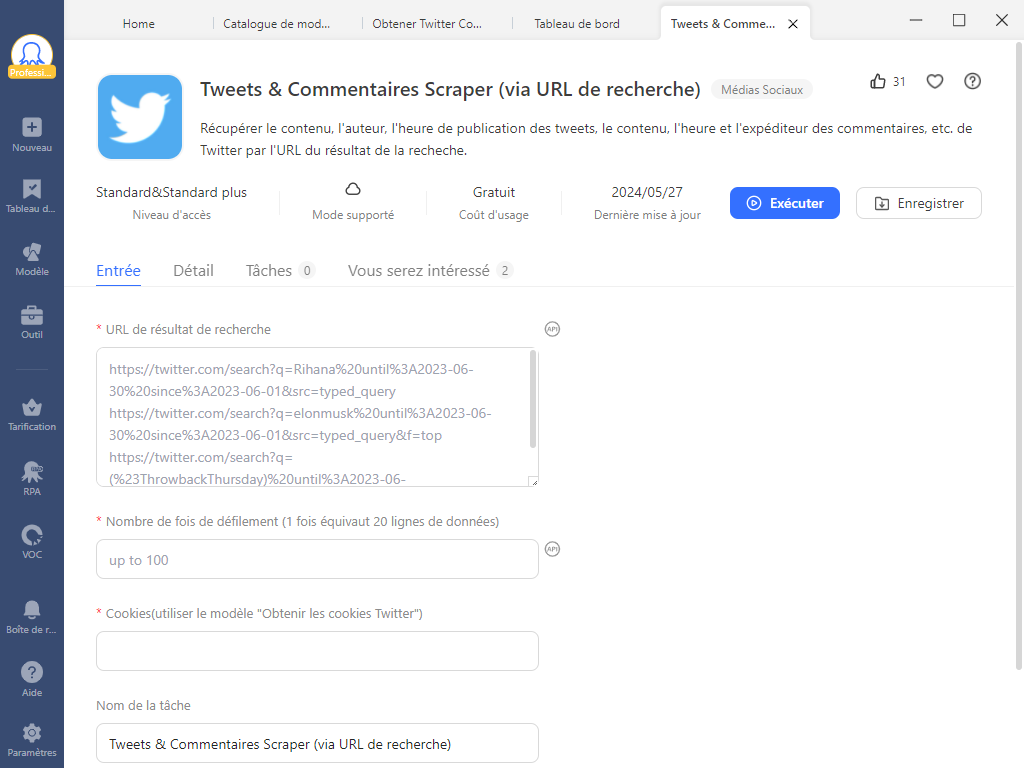
Étape 2 – Lire l’introduction et saisir les paramètres
Le modèle cible trouvé, il est temps à lire en détail l’introduction pour comprendre comment l’utiliser, savoir l’aperçu de données et les paramètres à saisir. S’il correspond justement à votre besoin, vous pouvez saisir les paramètres selon les instructions et puis exécuter la tâche.
Étape 3 – Exécuter la tâche et exporter les données
Vous pouvez choisir d’exécuter la tâche sur Cloud ou localement sur votre appareil.
Une fois l’extraction terminée, vous pouvez exporter les données dans des feuilles Excel, CSV, HTML, SQL, ou les diffuser dans votre base de données en temps réel via les API d’Octoparse.
Créer un scraper de Twitter à partir de zéro
Les modèles c’est très facile n’est pas ? Mais il arrive que les modèles ne couvrent pas votre besoin. Voyons maintenant comment construire un crawler Twitter en quelques minutes. Mais ne vous inquiétez pas, L’algorithme de détection automatique de l’outil vous facilitera grandement cette tâche, quel que soit votre niveau d’expertise.
Étape 1 : Saisir l’URL cible dans la barre de recherche
Par exemple, si je voudrais extraire tous les posts de OctoparseFr

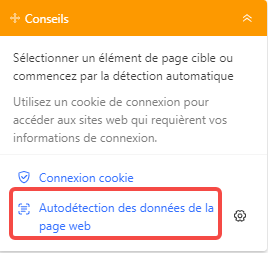
Étape 2 : Créer le flux de travail à l’aide de la détection automatique
Quand la page web est pleinement chargée, vous pouvez cliquer sur le bouton pour lancer la détection automatique des données de la page Web. Le robot va créer automatiquement un flux de travail de scraping pour vous.
Étape 3 : Exécuter la tâche et exporter les données
Vous pouvez maintenant exécuter le crawler pour obtenir les données et exporter les donénes vers Excel, CSV, HTML ou base de données.
Consultez ce tutoriel complet pour avoir un guide étape par étape.
Conseils et bonnes pratiques sur le scraping de tweets
Lorsque vous vous lancez dans le scraping de données sur Twitter, il est important de garder à l’esprit quelques conseils et bonnes pratiques afin d’optimiser votre processus et de vous conformer aux politiques de la plateforme.
- Définissez clairement les objectifs de votre projet de scraping et les données dont vous avez besoin. Cela vous permettra d’affiner vos requêtes et donc choisir le bon modèle qui correspond justement à votre besoin.
- Profiter des fonctionnalités de “Programmer l’exécution de tâches” pour suivre de près les mises à jour et les récolter à temps.
- Demander un essai gratuit de Octoparse premium pour tester la tester la solution.
Pour finir, on peut discuter sur un sujet auquel s’intéressent beaucoup de personnes : est-il légal de scraper Twitter ?
D’une manière générale, il est légal d’extraire et d’exploiter les données publiques. Cependant, vous devez toujours respecter la politique de protection des droits d’auteur et la réglementation sur les données personnelles. L’utilisation des données que vous avez extraites relève de votre responsabilité et vous devez prêter attention à la législation locale. Si vous avez toujours des doutes sur la légalité, vous pouvez essayer l’API de Twitter.
En conclusion
Pour exploiter pleinement le potentiel de Twitter, l’étape préliminaire consiste à récupérer l’ensemble des tweets pertinents pour votre projet. À cet effet, Octoparse s’avère être un outil puissant permettant de récolter efficacement ces informations depuis la plateforme.
Le processus de scraping de Twitter n’est pas particulièrement difficile grâce aux riches modèles de web scraping mis à disposition, aussi bien sur le site officiel d’Octoparse que dans le logiciel lui-même. Ainsi, même les débutants peuvent rapidement mettre en place des tâches de scraping opérationnelles.
Cependant, dans le cas où votre projet nécessiterait des fonctionnalités au-delà de ces modèles standards, vous avez également la possibilité de créer une tâche de scrapingà partir de zéro. Pour assurer le succès et la pérennité de cette approche, il est primordial de bien définir vos objectifs et de mettre en place des mécanismes de sauvegarde robustes.
En suivant ces étapes, vous serez en mesure d’exploiter efficacement les données Twitter pour les besoins de votre projet, tout en vous conformant aux bonnes pratiques en matière de scraping.



