Vous souhaitez reproduire un site web pour tester une refonte, migrer vers un nouvel hébergeur, ou analyser la structure de pages concurrentes. L’intention est précise. Les outils disponibles, eux, sont rarement à la hauteur.
Les aspirateurs de site classiques téléchargent du HTML statique. Ils butent sur les pages en JavaScript, se font bloquer par les protections anti-crawling modernes, et ne produisent rien d’exploitable directement dans un tableur ou un outil data. Si votre besoin se limite à sauvegarder un site pour le consulter hors ligne, un comparatif complet des aspirateurs de site web testés en conditions réelles sur des sites français couvre ce périmètre.
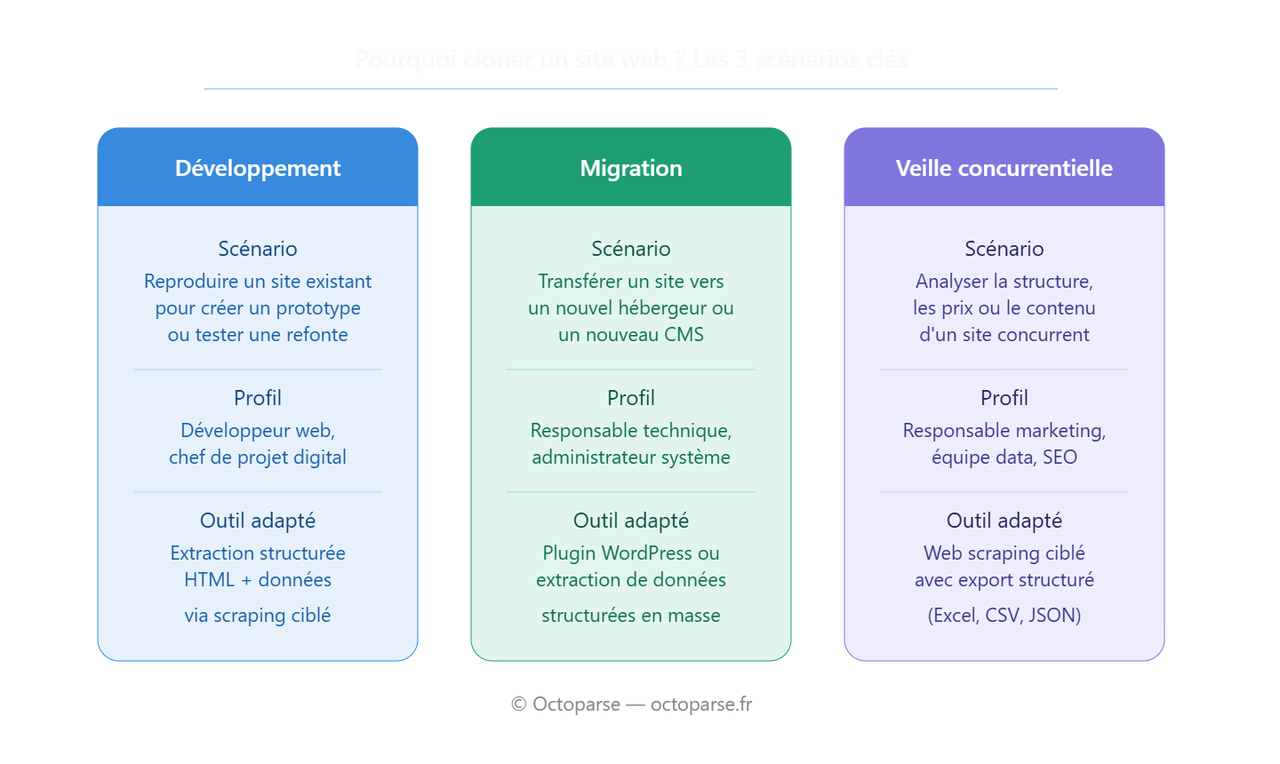
Cet article s’adresse à un besoin différent : cloner ou dupliquer un site web pour en faire quelque chose de concret. Migration de contenu, développement d’un prototype, extraction de données à grande échelle, analyse concurrentielle. Ces cas d’usage nécessitent une approche structurée, pas une copie brute de fichiers.
Cloner un site web : de quoi parle-t-on exactement ?
Le terme « cloner un site web » ou « cloner un site internet » recouvre des réalités très différentes selon le contexte. Il peut s’agir de :
- reproduire l’apparence visuelle d’un site pour s’en inspirer dans un projet de design ;
- dupliquer l’architecture technique d’un site WordPress pour le transférer vers un nouvel hébergeur ;
- extraire les données structurées d’un site (prix, descriptions, contacts) pour les analyser ou les intégrer dans un CRM ;
- créer un environnement de staging identique au site de production, pour tester des modifications sans risque.
Ces quatre besoins n’appellent pas les mêmes outils. En France, la majorité des demandes de duplication ou de reproduction de site web concernent des migrations WordPress, des refontes e-commerce sous Prestashop ou WooCommerce, ou des extractions de données pour alimenter des outils comme HubSpot ou Salesforce. Un aspirateur de site comme HTTrack répond au premier cas de manière partielle. Il est inadapté aux trois autres, particulièrement dès que le site cible utilise JavaScript pour charger son contenu, ce qui représente aujourd’hui la quasi-totalité des sites professionnels.
La distinction est importante : copier des fichiers ne produit pas les mêmes résultats que l’extraction de données. La première approche donne une copie statique, souvent incomplète et inexploitable en dehors d’un navigateur. La seconde produit des données structurées, directement utilisables dans vos outils métier.
Pourquoi les outils classiques montrent leurs limites
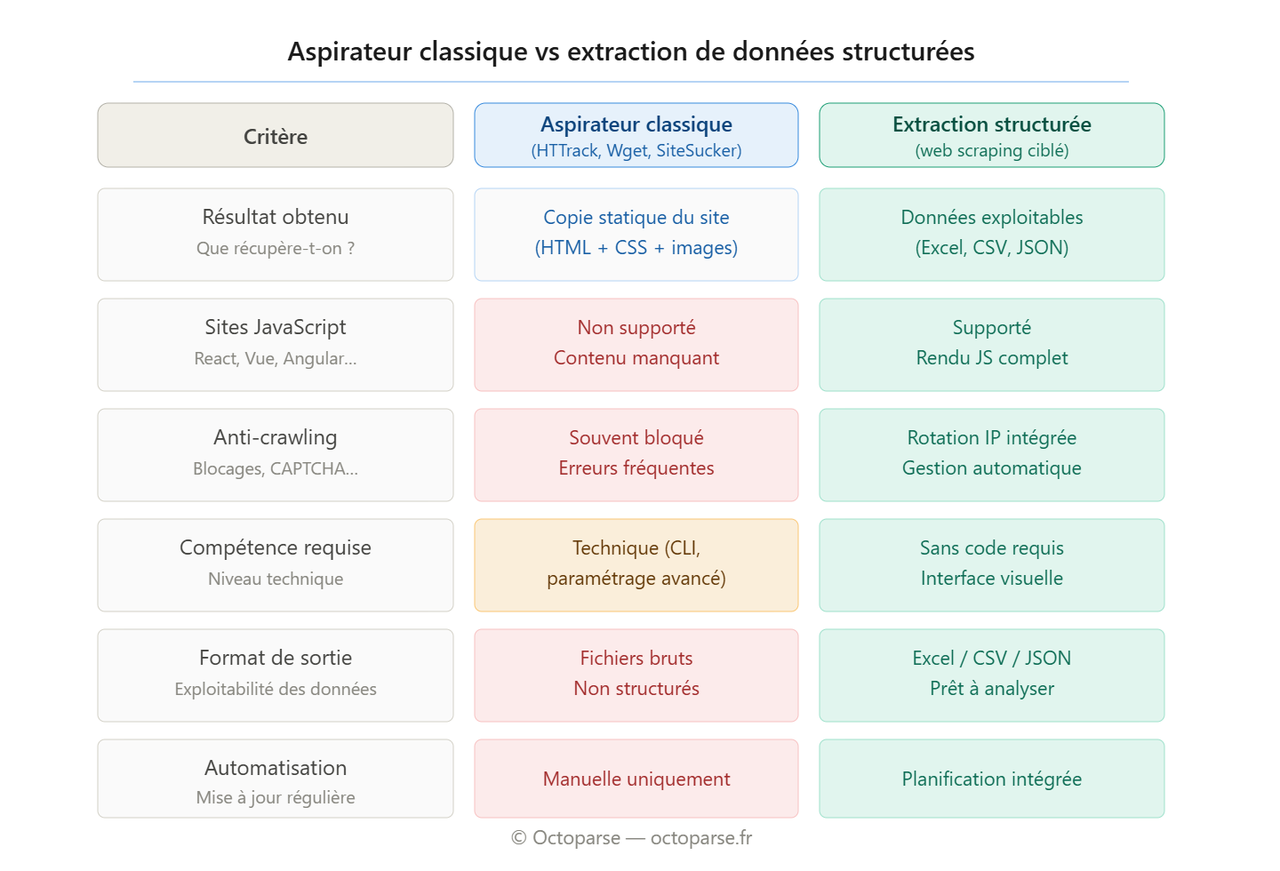
Les aspirateurs de site web traditionnels, HTTrack en tête, ont été conçus à une époque où les sites web étaient principalement statiques. Leur principe de fonctionnement repose sur le téléchargement récursif de fichiers HTML, CSS et images à partir d’une URL de départ.
Ce modèle présente trois limites structurelles en 2026 :
Les sites modernes sont dynamiques. La grande majorité des sites professionnels charge son contenu via JavaScript : React, Vue, Angular, ou simplement des appels AJAX. Un aspirateur classique récupère le squelette HTML initial, mais pas les données affichées après exécution du script. Le résultat est une copie vide ou incomplète.
Les protections anti-crawling sont généralisées. Cloudflare, les CAPTCHA, la rotation des requêtes, la détection des User-Agents automatisés : ces mécanismes bloquent systématiquement HTTrack et Wget sur les sites qui les ont activés. En pratique, cela concerne la plupart des sites e-commerce, médias et SaaS français.
La sortie n’est pas exploitable. Une copie locale de fichiers HTML n’est pas une base de données. Si votre objectif est d’analyser des prix, d’alimenter un CRM ou de comparer des structures de contenu, vous devrez retraiter manuellement les fichiers obtenus, ce qui annule le gain de temps attendu.
HTTrack reste la référence historique, mais en 2026, la plupart des équipes techniques françaises cherchent une alternative à HTTrack capable de gérer les sites dynamiques et les protections anti-crawling sans configuration manuelle fastidieuse.
Les cas d’usage légitimes du clonage de site
Cloner un site web est une pratique courante dans de nombreux contextes professionnels. Voici les principaux scénarios rencontrés en France.
Migration et transfert de site
La migration est probablement le cas d’usage le plus fréquent. En France, les situations sont variées : un site WordPress hébergé chez OVHcloud ou Ionos dont le contrat n’est pas renouvelé, un transfert vers Hostinger ou o2switch pour réduire les coûts, ou encore une refonte qui impose de passer d’un CMS propriétaire vers WordPress ou Webflow. Dans tous ces cas, il faut exporter le contenu structuré du site d’origine et le réimporter ailleurs.
Pour les sites WooCommerce notamment, l’extraction des données produits (noms, descriptions, prix, SKU, images) est une étape incontournable avant tout transfert vers un nouvel environnement. Une approche structurée pour extraire les données WooCommerce permet de gagner plusieurs jours sur le processus de migration.
Développement et prototypage
Un développeur ou un chef de projet souhaitant proposer une refonte a souvent besoin de copier un site web et le modifier pour présenter une maquette fonctionnelle au client. L’enjeu n’est pas de reproduire le contenu protégé, mais d’analyser l’architecture, les blocs de navigation, les gabarits de pages, et les types de données présents.
Reproduire un site web fidèlement commence souvent par une analyse structurelle : quels composants sont utilisés, comment les blocs sont organisés, quelles classes CSS reviennent systématiquement. Pour ce faire, extraire le code source HTML page par page est souvent plus rapide qu’une inspection manuelle via les outils de développement du navigateur.
Veille concurrentielle et analyse de données
Un responsable marketing ou une équipe data qui surveille les prix, les promotions ou les fiches produits de sites concurrents a besoin d’extraire ces informations de manière régulière et structurée. Ce n’est pas du clonage au sens strict, mais de l’extraction ciblée, ce qui est techniquement et juridiquement très différent.
Si votre équipe passe encore 2 heures par semaine à copier-coller des prix ou des fiches concurrents dans un tableur, mettre en place une collecte automatisée prend moins de temps que cette session de veille manuelle, et tourne ensuite sans intervention.
Staging et tests
Créer une copie de son propre site pour tester des mises à jour, des plugins ou des modifications de design sans risquer d’affecter la production est une bonne pratique recommandée par tous les prestataires d’hébergement sérieux. Dans ce cas, la migration se fait entre deux environnements que vous contrôlez tous les deux.
Légalité et cadre applicable en France
La question de la légalité du clonage de site revient systématiquement, et pour cause : la frontière entre une pratique légitime et une violation de droits peut être fine.
Ce que dit le droit français
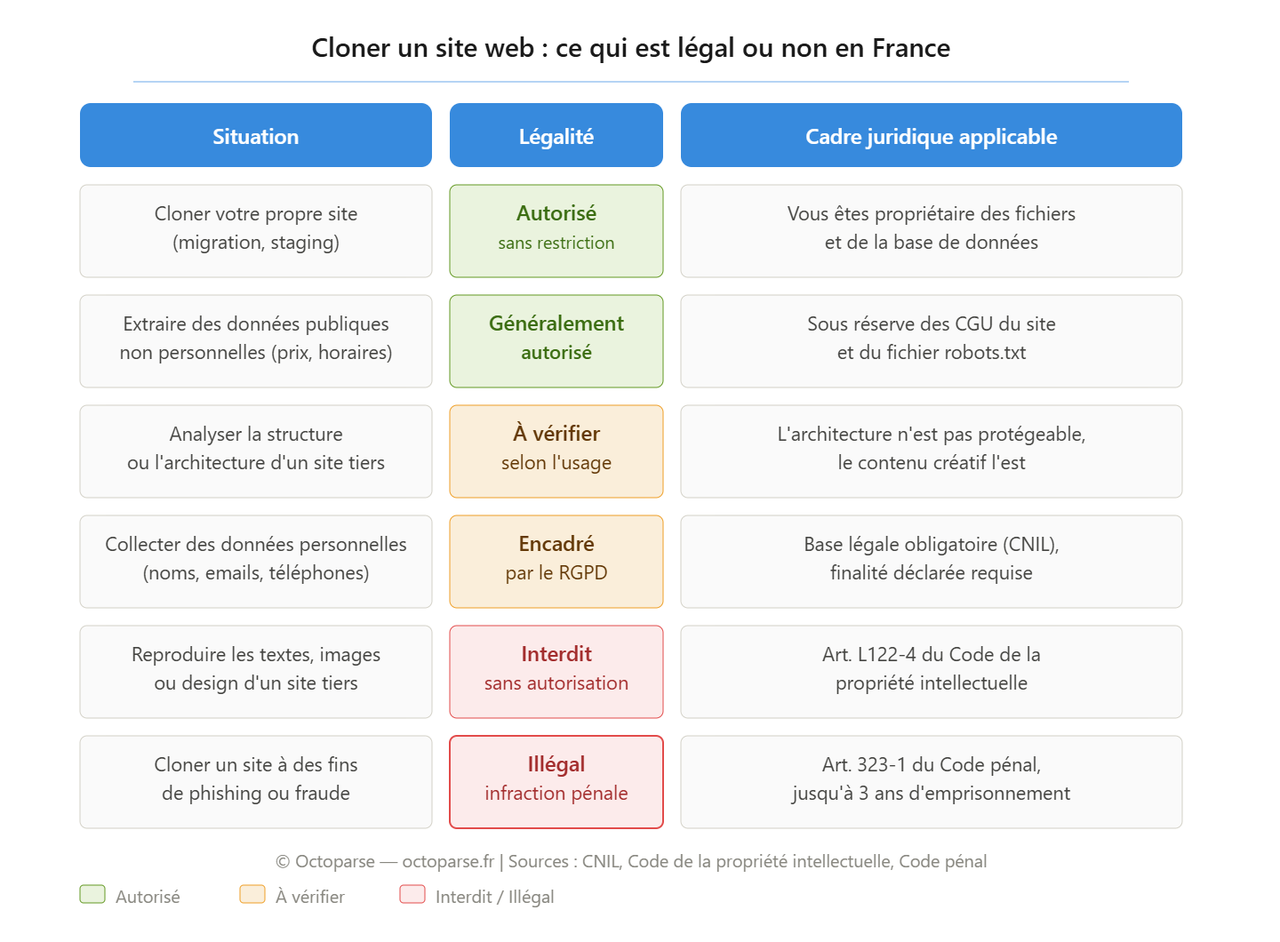
L’article L122-4 du Code de la propriété intellectuelle interdit toute reproduction, représentation ou diffusion d’une oeuvre sans autorisation de l’auteur. Un site web est une oeuvre protégée : son design, ses textes, ses images, sa charte graphique appartiennent à son créateur ou à l’entreprise qui l’a commandé.
Cloner un site pour en reproduire le contenu créatif sans accord explicite constitue donc une violation du droit d’auteur, même si la copie reste en usage interne.
En revanche, sont généralement autorisés :
- la copie de votre propre site, pour migration ou staging ;
- l’extraction de données publiques non personnelles (prix, horaires, noms de produits), à des fins d’analyse ;
- la reproduction d’éléments non protégeables, comme une architecture de navigation ou une structure de page.
Le RGPD s’applique dès que des données personnelles sont en jeu
Si le site que vous souhaitez analyser contient des données personnelles (noms, adresses e-mail, numéros de téléphone), le Règlement général sur la protection des données impose des contraintes supplémentaires. La CNIL rappelle que la collecte de données personnelles sans base légale est illicite, même si ces données sont techniquement accessibles en ligne. Dans ses lignes directrices sur les données publiquement accessibles, elle précise que la réutilisation de données à caractère personnel issues de sites tiers doit reposer sur une base légale documentée, et que les personnes concernées peuvent exercer leur droit d’opposition à tout moment.
La règle pratique : avant d’extraire des données d’un tiers, vérifiez les conditions générales d’utilisation du site, l’existence d’un fichier robots.txt restrictif, et assurez-vous que les données collectées ne permettent pas d’identifier des individus sans leur consentement.
Cloner un site web avec les outils traditionnels : ce qu’il faut savoir
Pour les cas simples, deux outils restent des références.
HTTrack et Wget : utiles dans un périmètre précis
HTTrack est un logiciel open source conçu pour cloner un site statique en local : il télécharge récursivement les pages HTML, CSS et images d’un site simple, sans JavaScript et sans protection anti-crawling. Son usage est gratuit, mais son interface est datée et sa configuration peut décourager les profils non techniques.
Wget est un outil en ligne de commande disponible sur Linux, macOS et Windows. Pour copier un site web avec Wget en conservant sa structure de navigation, la commande de base est la suivante :
Les deux paramètres les plus importants pour éviter un blocage :
--wait=2introduit une pause entre chaque requête,--limit-rate=100klimite la charge sur le serveur cible. Le détail complet des options est couvert dans le comparatif des aspirateurs de site web.
Ces deux outils partagent la même limite fondamentale : ils ne gèrent pas le JavaScript. Sur un site moderne, le résultat sera une copie incomplète, souvent inutilisable.
Si votre besoin se limite à sauvegarder un site pour le consulter hors ligne, les aspirateurs de site web classiques testés en conditions réelles sur des sites français restent une option valable.
Cloner un site web pour en extraire les données : l’approche structurée
Exportez vos données directement vers Excel, CSV, Google Sheets ou votre base de données, sans manipulation intermédiaire.
Pointez sur les données qui vous intéressent : l’outil détecte automatiquement la structure de la page et génère les règles d’extraction.
Démarrez en quelques clics grâce aux modèles prêts à l’emploi pour les sites les plus courants.
Contournez les blocages automatiquement : rotation de proxies IP et rendu JavaScript intégré, sans configuration manuelle.
Planifiez vos extractions en cloud : vos données se mettent à jour automatiquement, sans laisser votre ordinateur allumé.

Quand l’objectif dépasse la simple sauvegarde, une autre approche s’impose : extraire les données structurées d’un site, plutôt que d’en faire une copie brute.
La différence est fondamentale. Au lieu de télécharger des fichiers HTML, vous extrayez les informations qui vous intéressent (titres, prix, descriptions, URLs, contacts) et vous les exportez directement dans un format utilisable : Excel, CSV ou JSON.
Cette approche présente plusieurs avantages concrets :
- elle fonctionne sur les sites JavaScript dynamiques ;
- elle produit des données directement exploitables sans retraitement ;
- elle peut être automatisée pour des mises à jour régulières ;
- elle est paramétrable : vous choisissez précisément ce que vous extrayez.
Extraire le code source HTML d’un site
Pour les développeurs qui ont besoin d’analyser la structure HTML d’un site avant de le reproduire, l’extraction du code source page par page est souvent la première étape. Cela permet d’identifier les composants, les classes CSS utilisées, les blocs de contenu récurrents.
Le modèle HTML Scraper d’Octoparse automatise cette extraction à partir d’une liste d’URLs :
https://www.octoparse.fr/template/html-scraper
Extraire le contenu structuré d’un site
Pour aller plus loin et extraire directement les données utiles (textes, prix, images, métadonnées), le Smart Article Scraper permet de cibler n’importe quelle page web et ses sous-pages, sans configuration technique :
https://www.octoparse.fr/template/smart-article-scraper
L’export est direct : les données collectées arrivent dans Excel en quelques clics, sans manipulation intermédiaire.
L’extraction de données sur les sites dynamiques
La majorité des sites professionnels en France charge son contenu via JavaScript. Les pages produits sur les sites e-commerce, les fiches entreprises sur les annuaires, les offres d’emploi sur les job boards : toutes ces données ne sont pas dans le HTML initial, elles sont injectées dynamiquement après l’exécution des scripts.
La solution passe par des outils capables d’extraire les données de sites web dynamiques en exécutant le JavaScript avant la collecte, ce qui permet de récupérer le contenu réellement affiché à l’utilisateur.
Octoparse gère nativement les sites JavaScript, sans configuration supplémentaire. Si vous avez des URLs cibles précises, tester directement sur vos pages reste la façon la plus rapide de vérifier si l’extraction fonctionne avant de vous engager.
Cloner un site avec l’IA : les nouvelles possibilités
Depuis 2025, plusieurs outils ont introduit une approche radicalement différente du clonage de site : au lieu de télécharger des fichiers ou de configurer des règles d’extraction, vous décrivez ce que vous voulez en langage naturel, et l’IA s’occupe du reste.
Deux familles d’outils coexistent aujourd’hui :
Cloner un site web avec l’IA visuelle, c’est ce que proposent des outils comme Anima, v0 by Vercel ou bolt.new : à partir d’une URL ou d’une description, ils reproduisent l’apparence d’une page et génèrent du code React ou HTML directement utilisable. v0 by Vercel est particulièrement adopté par les équipes frontend françaises pour le prototypage rapide de composants. Ces outils conviennent à l’inspiration design et aux maquettes fonctionnelles, mais ils ne produisent pas de données exploitables : le résultat est du code, pas un tableau structuré.
Les agents de scraping pilotés par IA permettent d’interroger un site en langage naturel pour en extraire des données précises, sans écrire de requête technique. Octoparse MCP s’inscrit dans cette catégorie.
Octoparse MCP : extraire des données par la conversation
Octoparse MCP est un serveur MCP (Model Context Protocol) qui connecte des agents IA comme Claude ou ChatGPT aux capacités de collecte de données web d’Octoparse. Concrètement, vous pouvez demander à votre assistant IA de « récupérer les 50 premiers produits de ce site avec leur prix et leur description », et l’agent exécute la collecte directement.
Pour aller plus loin, le tutoriel Claude scraping web avec Octoparse MCP détaille la mise en place étape par étape.
Le protocole MCP est le standard qui permet à un agent IA de communiquer avec des outils externes en temps réel : comprendre son fonctionnement aide à saisir pourquoi cette approche est plus fiable qu’un simple prompt ChatGPT pour collecter des données web.
Pour transformer n’importe quelle URL en données structurées prêtes à l’emploi, le modèle universel est accessible directement :
https://www.octoparse.fr/template/universal-content
Si vous utilisez déjà Claude ou ChatGPT au quotidien, connecter Octoparse MCP à votre assistant IA transforme n’importe quelle session de travail en outil de collecte de données, sans quitter votre interface habituelle.
Cloner un site WordPress : les méthodes adaptées
WordPress représente environ 43 % des sites web dans le monde, et une part significative des sites professionnels français. Le clonage d’un site WordPress pour migration ou staging a ses propres spécificités. Aspirer un site WordPress avec HTTrack est techniquement possible, mais le résultat est rarement exploitable : les thèmes modernes (Divi, Elementor, Avada) génèrent leur contenu via JavaScript, ce qui donne une copie incomplète. Pour une migration réelle, d’autres méthodes sont plus fiables.
Les plugins dédiés comme Duplicator ou WP Staging permettent de créer une archive complète du site (fichiers + base de données) et de la redéployer sur un autre hébergement. Pour les utilisateurs hébergés chez o2switch ou OVHcloud, ces deux hébergeurs proposent également des environnements de staging intégrés dans leur panel, ce qui évite de passer par un plugin tiers. C’est la méthode recommandée pour les migrations WordPress vers WordPress.
Pour les migrations vers un autre CMS (Webflow, Shopify, Prestashop), ou pour extraire le contenu d’un site WordPress tiers, l’extraction de données structurées reste la seule approche viable. C’est notamment le cas pour les boutiques WooCommerce qui migrent vers Shopify : aucun plugin natif ne gère ce transfert de façon automatisée, et l’export CSV de WordPress ne couvre pas toutes les métadonnées produits.
Pour les sites WooCommerce, extraire les données produits sans accès administrateur au site cible reste possible via le scraping des pages publiques.
Attention : cloner un site WordPress que vous ne possédez pas, même via un plugin, nécessite un accès administrateur au site cible. Sans cet accès, seule l’extraction des données publiques via scraping est possible.
Comment fonctionne l’extraction de données structurées en pratique
Un aspirateur de site télécharge des fichiers. Un outil d’extraction de données récupère des informations ciblées, structurées, directement utilisables. La différence se mesure à l’usage : au lieu de récupérer 2 000 fichiers HTML à retraiter manuellement, vous obtenez un tableau Excel avec les données que vous avez sélectionnées, directement filtrable, analysable et importable dans votre CRM.
Concrètement, il permet de :
- pointer sur n’importe quelle page web et sélectionner les données à extraire (comme on sélectionnerait du texte) ;
- gérer automatiquement la pagination, les menus déroulants et les sites JavaScript ;
- planifier des extractions récurrentes : une veille tarifaire quotidienne sur les sites concurrents, un suivi hebdomadaire des nouvelles offres d’emploi, une mise à jour mensuelle d’une base de contacts depuis PagesJaunes. Tout cela tourne en arrière-plan, sans action manuelle.
- exporter directement vers Excel, CSV, JSON ou API.
Pour les équipes commerciales qui constituent leurs listes de prospects sur LinkedIn, les règles du jeu sont différentes : ce comparatif des outils d’extraction LinkedIn explique ce qui fonctionne réellement en 2026, et ce qui expose à un blocage de compte.
Quel que soit votre cas d’usage, extraction de données produits, veille tarifaire ou prospection commerciale, l’essai gratuit permet de tester sur vos propres URLs sans carte bancaire requise.
FAQ
- Est-il légal de cloner un site web en France ?
Cela dépend de l’objectif et de la nature des données. Cloner votre propre site pour le migrer ou le tester est légal sans restriction. Surveiller les prix publics de sites concurrents à des fins d’analyse interne est généralement toléré, à condition de respecter les CGU du site et de ne pas automatiser des volumes qui perturbent le serveur. En revanche, reproduire le contenu créatif d’un tiers (textes, design, images) sans accord explicite constitue une violation de l’art. L122-4 du Code de la propriété intellectuelle. Dès que des données personnelles sont impliquées, le RGPD s’applique et une base légale documentée est obligatoire.
- Quelle est la différence entre cloner un site et le scraper ?
Cloner un site consiste à en reproduire l’apparence ou l’architecture complète. Le scraping consiste à en extraire des données précises et structurées. Dans la pratique, si votre objectif est d’analyser ou d’utiliser des informations issues d’un site, le scraping ciblé est plus efficace, plus rapide et plus exploitable qu’une copie brute.
- HTTrack fonctionne-t-il encore sur les sites modernes ?
HTTrack reste utile sur les sites statiques simples, sans JavaScript et sans protection anti-crawling. Sur les sites modernes (e-commerce, SaaS, médias), il produit des copies incomplètes et rencontre régulièrement des erreurs de blocage. Il n’est pas adapté à l’extraction de données structurées.
- Peut-on cloner un site WordPress sans plugin ?
Techniquement oui, en exportant manuellement les fichiers via FTP et en sauvegardant la base de données MySQL. C’est une procédure réservée aux profils techniques. Les plugins comme Duplicator ou WP Staging simplifient considérablement cette opération pour les migrations entre environnements WordPress.
- Comment extraire les données d’un site sans coder ?
Des outils comme Octoparse permettent de sélectionner visuellement les éléments à extraire sur n’importe quelle page web, sans écrire de code. Vous pointez sur les données qui vous intéressent (prix, titres, contacts), l’outil génère automatiquement les règles d’extraction. L’export se fait directement vers Excel ou CSV. Tester gratuitement pendant 14 jours permet de valider la méthode sur vos propres URLs avant tout engagement.
- L’IA peut-elle cloner un site web automatiquement ?
Partiellement. Les outils de clonage visuel par IA reproduisent l’apparence d’une page en quelques secondes, mais le résultat est une maquette, pas des données exploitables. Pour extraire automatiquement des informations structurées depuis un site, les agents de scraping pilotés par IA sont plus adaptés : vous décrivez ce que vous cherchez, l’outil s’occupe de la collecte. Les deux approches ne se substituent pas : la première sert le design, la seconde la donnée. La mise en pratique avec Claude est détaillée dans le tutoriel Claude scraping web avec Octoparse MCP.
- Que faire si le site cible bloque les tentatives de scraping ?
Les outils de scraping avancés comme Octoparse intègrent des mécanismes pour contourner ces protections légalement : rotation des requêtes, gestion des délais, rendu JavaScript complet. Un tour d’horizon des techniques anti-scraping les plus courantes permet de mieux comprendre ce que votre outil doit être capable de gérer.
- Existe-t-il des outils gratuits pour cloner ou scraper un site web ?
Plusieurs outils permettent de cloner ou scraper un site web gratuitement selon le cas d’usage. Pour les sites statiques simples : HTTrack (Windows/Linux) et Wget (ligne de commande, toutes plateformes) sont open source et gratuits. Pour l’extraction de données structurées sur des sites modernes : Octoparse propose un plan gratuit avec un quota mensuel adapté aux besoins ponctuels, et ses modèles prêts à l’emploi (HTML Scraper, Smart Article Scraper) sont accessibles sans abonnement. L’accès gratuit de 14 jours couvre les fonctionnalités complètes, sans carte bancaire.
- La migration d’un site web nécessite-t-elle un prestataire technique ?
Pas nécessairement. Pour les migrations WordPress vers WordPress, un plugin comme Duplicator suffit dans la majorité des cas. Pour les migrations vers un autre CMS (Shopify, Webflow, Prestashop), l’extraction des données via scraping permet de récupérer le contenu structuré sans accès serveur, et de le réimporter manuellement ou via API. Un prestataire devient utile si le site dépasse quelques centaines de pages ou si la structure de données est complexe. En France, les tarifs pour une migration WordPress complète avec un freelance ou une agence varient généralement entre 500 et 3 000 euros selon le volume et la complexité. L’extraction préalable des données via scraping permet souvent de réduire ce coût en livrant un fichier structuré clé en main au prestataire.
- Comment cloner un site web automatiquement et le maintenir à jour ?
L’automatisation complète passe par un outil de scraping planifié plutôt que par un aspirateur de site. Concrètement : vous configurez une extraction une fois en pointant sur les données à récupérer, puis vous définissez une fréquence (quotidienne, hebdomadaire, mensuelle). L’outil tourne en arrière-plan et met à jour votre fichier de sortie sans intervention manuelle. C’est ce que permettent les extractions cloud d’Octoparse, accessibles sans laisser votre ordinateur allumé.
Cet article a été rédigé par l’équipe technique d’Octoparse, qui accompagne depuis plus de 10 ans des équipes data, marketing et développement dans l’extraction de données web en France et en Europe. Les outils et méthodes présentés ont été testés en conditions réelles sur des sites français en 2026. Les informations juridiques ont un caractère informatif général et ne constituent pas un avis juridique. Pour toute question spécifique, consultez un professionnel du droit spécialisé en droit du numérique.



