Avertissement : cet article traite de la collecte de données utilisées dans le contexte des paris hippiques. Les paris sont réservés aux personnes majeures. Interdit aux moins de 18 ans. Jouer comporte des risques : endettement, isolement, dépendance. Pour être aidé, appelez le 09 74 75 13 13 (appel gratuit).
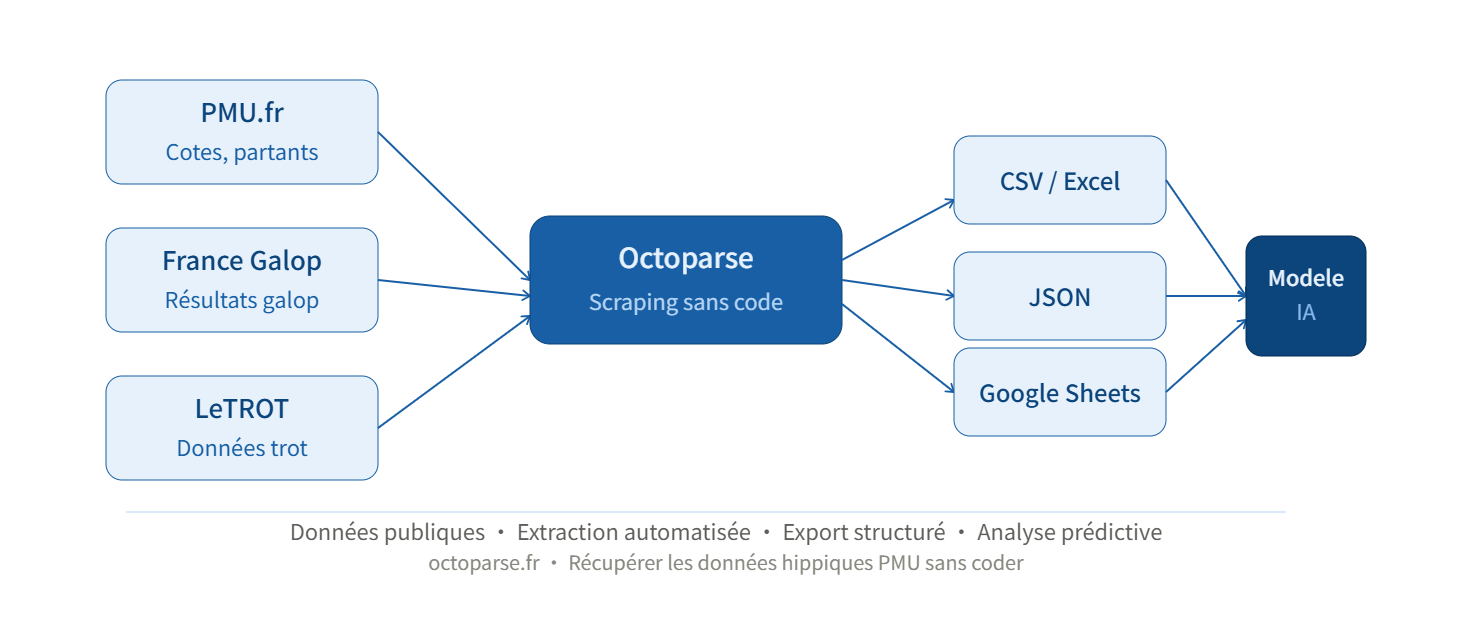
Lors du Prix d’Amérique 2025, plus de 17,7 millions d’euros ont été misés sur une seule course. Derrière chaque analyse sérieuse, il y a des données : musique du cheval, jockey, état du terrain, cotes en temps réel. Le problème n’est pas de savoir où ces données se trouvent : elles sont publiques, sur France Galop, LeTROT, PMU.fr. Le problème, c’est de les collecter à grande échelle, de les structurer et de les maintenir à jour sans passer des heures à copier-coller.
Le web scraping automatise exactement ce travail. En quelques clics depuis Octoparse, ou en quelques dizaines de lignes de Python, vous pouvez constituer une base historique de courses exportée en CSV ou Excel, exploitable directement pour vos analyses ou vos modèles prédictifs.
Ce guide vous explique comment faire, avec ou sans code.
Ce que le web scraping résout là où l’API PMU échoue
Le réflexe naturel, quand on commence à s’intéresser aux données de courses, c’est de chercher une API. PMU.fr en possède bien une, mais elle n’est pas documentée publiquement, ses endpoints changent sans préavis, et certaines routes ne retournent des données cohérentes que dans des contextes d’appel très spécifiques. Sur les forums techniques francophones comme Excel-Pratique ou PHPFrance, c’est le même constat qui revient régulièrement depuis 2023 : récupérer automatiquement les résultats PMU en JSON est faisable, mais fragile et chronophage à maintenir.
Copier manuellement les données depuis pmu.fr ou france-galop.com vers un tableur devient ingérable dès qu’on dépasse une saison de courses. Pour construire un modèle prédictif sérieux, il faut des milliers de courses, des dizaines de variables par partant et une mise à jour régulière.
C’est exactement ce que le web scraping résout : extraire automatiquement, en grande quantité, depuis n’importe quelle source publique, et exporter dans le format de votre choix.
Concrètement, voici ce qu’on peut récupérer depuis les sites hippiques officiels français :
| Champ | Description | Utilité pour l’IA |
| Hippodrome | Lieu de la course | Facteur terrain/distance |
| Distance | En mètres | Compatibilité cheval/distance |
| État du terrain | Bon, souple, lourd… | Variable météo essentielle |
| Musique du cheval | Résultats des 5 dernières courses | Indicateur de forme récente |
| Jockey / Driver | Nom et statistiques | Performance historique |
| Entraîneur | Taux de réussite par hippodrome | Signal de préparation |
| Cotes PMU | Rapport probable au départ | Consensus du marché |
| Temps / Écart | Chronométrage officiel | Mesure de performance absolue |
Les méthodes de collecte s’appliquent à tous les sports : pour une vue d’ensemble, l’article sur l’extraction de données sportives avec le web scraping couvre les principaux patterns à connaître.
Sources de données hippiques en France : PMU, France Galop, LeTROT
Avant de choisir votre outil, il faut connaître vos sources. En France, plusieurs organismes publient des données hippiques structurées en accès libre.
France Galop gère les courses de galop, plat et obstacles. Les pages de résultats détaillées nécessitent une connexion pour y accéder.
LeTROT couvre le trot attelé et monté. Les données sont accessibles sans connexion, par course et par cheval, avec un historique sur plusieurs saisons. C’est la source utilisée dans le tutoriel ci-dessous.
PMU.fr est le point d’entrée le plus connu des parieurs, mais techniquement le plus complexe à scraper : certaines pages chargent dynamiquement via JavaScript et l’API non documentée peut être instable. Pour une collecte fiable, mieux vaut partir de France Galop ou LeTROT, puis croiser avec PMU pour les cotes.
Geny Courses est la référence des turfistes pour les statistiques avancées des partants : historique des performances, statistiques jockey-hippodrome, indicateurs de forme. Les données sont particulièrement riches pour construire des features de modèle prédictif.
Paris-Turf publie chaque jour les pronostics du Quinté+ et les résultats détaillés de toutes les réunions. Utile pour croiser les données officielles avec des indicateurs éditoriaux.
Si vous débutez, privilégiez France Galop ou LeTROT. Leurs pages HTML sont stables, bien organisées, et ne nécessitent pas de gestion de rendu JavaScript.
Récupérer les données hippiques sans code avec Octoparse : tutoriel pas à pas
Octoparse fonctionne sans écrire une seule ligne de code. Vous sélectionnez visuellement les données à extraire, vous configurez la fréquence de collecte, et l’outil s’occupe du reste, en local sur votre machine ou directement dans le cloud. Voici comment récupérer les résultats de courses depuis LeTROT en moins de dix minutes.
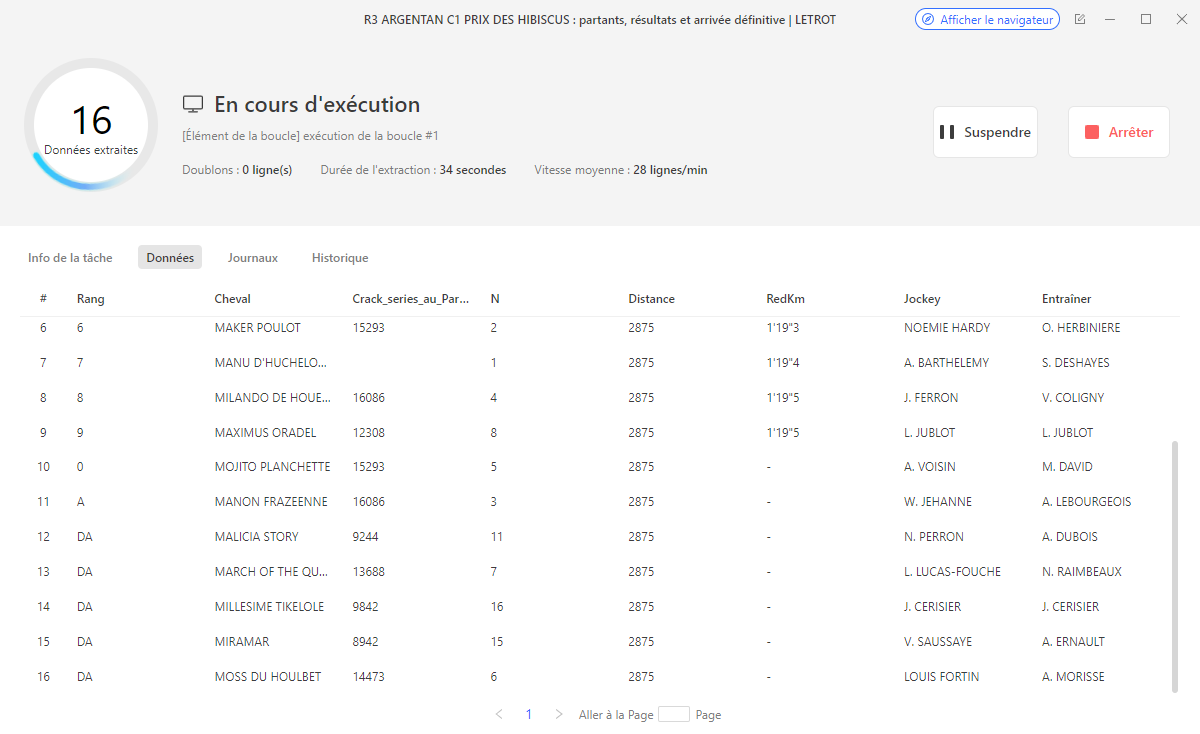
Données extraites dans cet exemple (partants R3 C1 Argentan – Prix des Hibiscus) :
| N° | Cheval | Jockey | Entraîneur | SA | Distance | Pds | Musique | Record | Gains (€) | Rap. prob. |
| 1 | MICHIGAN BLUE | J. MAILLARD | Sté. Ent. G. THOREL | H4 | 2875 | 56 | Dm Dm Dm Dm (25) Dm | – | – | 22/25 |
| 2 | MOJITO PLANCHETTE | N. PERRON | F. BLANDIN | H4 | 2875 | 63 | Da 2m 0m Dm (25) Dm | – | 3 000 € | 22/26 |
| … | … | … | … | … | … | … | … | … | … | … |
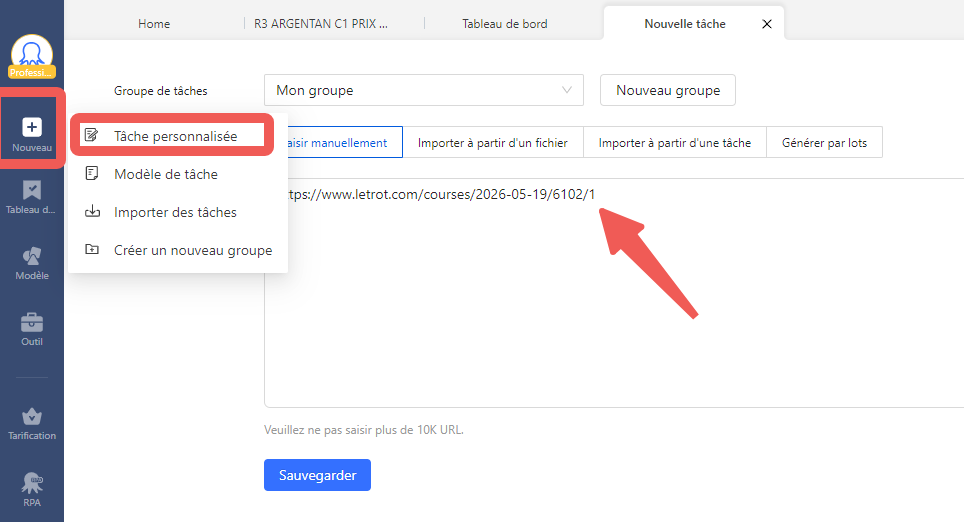
Étape 1 : ouvrir Octoparse et saisir l’URL LeTROT
Lancez Octoparse et depuis l’écran d’accueil, cliquez sur Nouveau > Tâche personnalisée.
Dans le champ URL, collez l’adresse de la page de résultats qui vous intéresse. Pour cet exemple, nous utilisons la page de résultats d’une course de trot attelé sur LeTROT :
Voir la page de résultats LeTROT utilisée dans cet exemple
La même méthode s’applique à n’importe quelle réunion LeTROT ou à toute autre source hippique publique : naviguez jusqu’à la course souhaitée, copiez l’URL depuis votre navigateur et collez-la dans Octoparse.
Cliquez sur Démarrer pour valider.
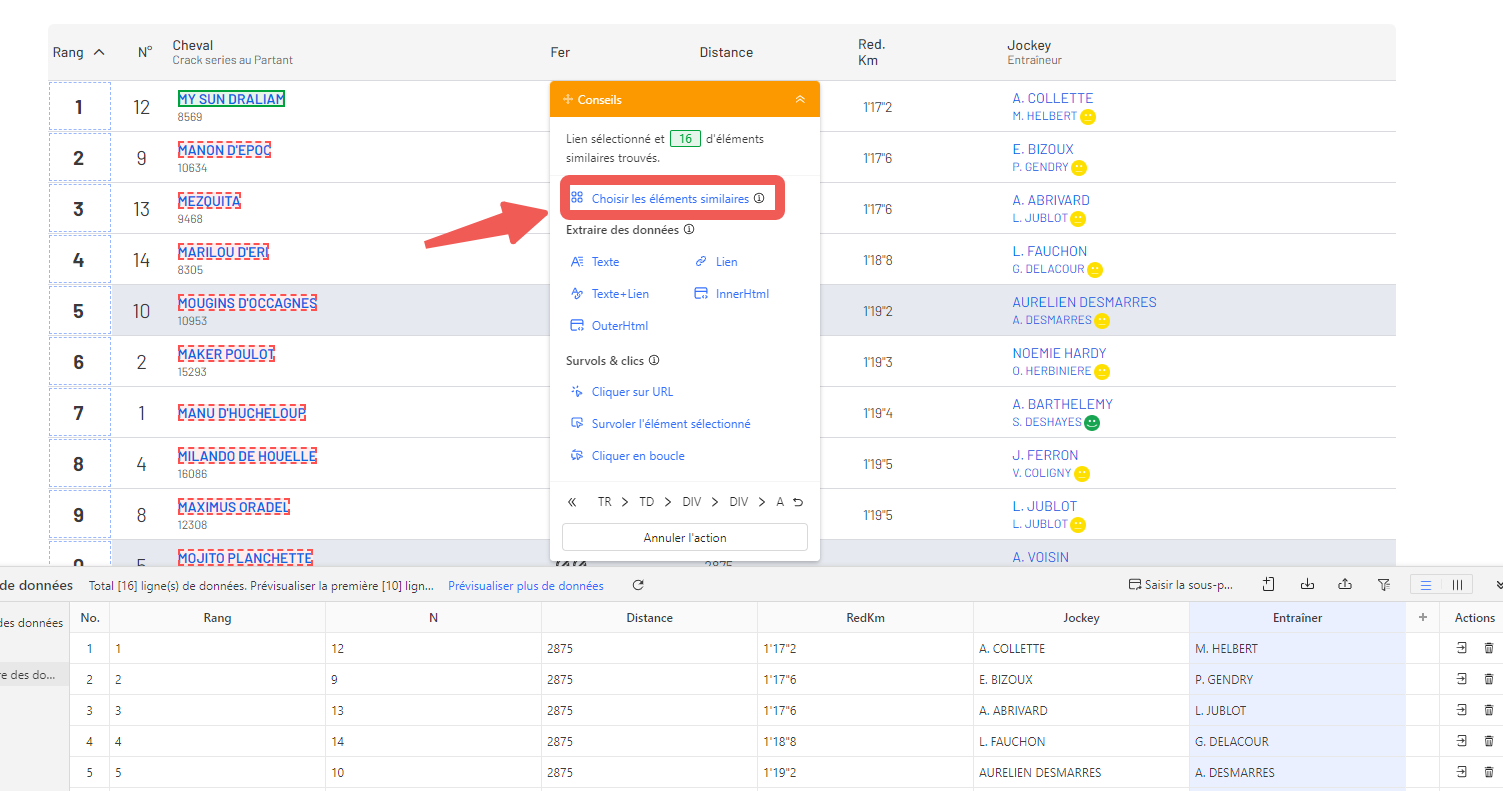
Étape 2 : sélectionner les données hippiques à extraire
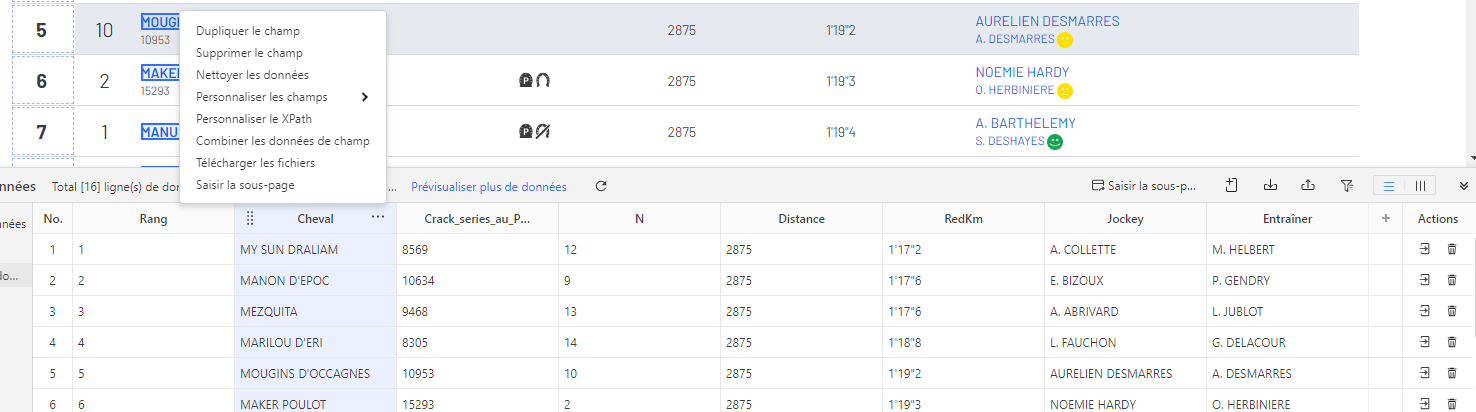
Dans le navigateur intégré d’Octoparse, cliquez sur la première valeur que vous souhaitez récupérer, par exemple le nom du premier cheval classé. La cellule passe en vert.
Les autres éléments similaires (les autres noms de chevaux) s’affichent en rouge : Octoparse les a identifiés comme éléments de même type.
Dans le panneau Conseils d’action, cliquez sur Sélectionner les éléments similaires, puis sur Sélectionner les sous-éléments pour capturer l’ensemble de chaque ligne. Cliquez ensuite sur Tout sélectionner, puis sur Extraire les données. Octoparse construit automatiquement le workflow d’extraction.
Étape 3 : vérifier et nommer les colonnes de données
Le panneau d’aperçu affiche les données extraites en temps réel. À ce stade, vous pouvez :
- renommer les colonnes (ex : “field_1” → “Cheval”, “field_2” → “Jockey”)
- supprimer les colonnes inutiles
- vérifier que toutes les lignes sont correctement capturées
Astuce : pour collecter les résultats sur plusieurs réunions ou plusieurs saisons, utilisez la fonctionnalité Boucle d’URL d’Octoparse. Il vous suffit de définir le pattern d’URL (ex : …/2024/01/, …/2024/02/…) et l’outil parcourt automatiquement toutes les pages, sans aucune compétence en programmation.
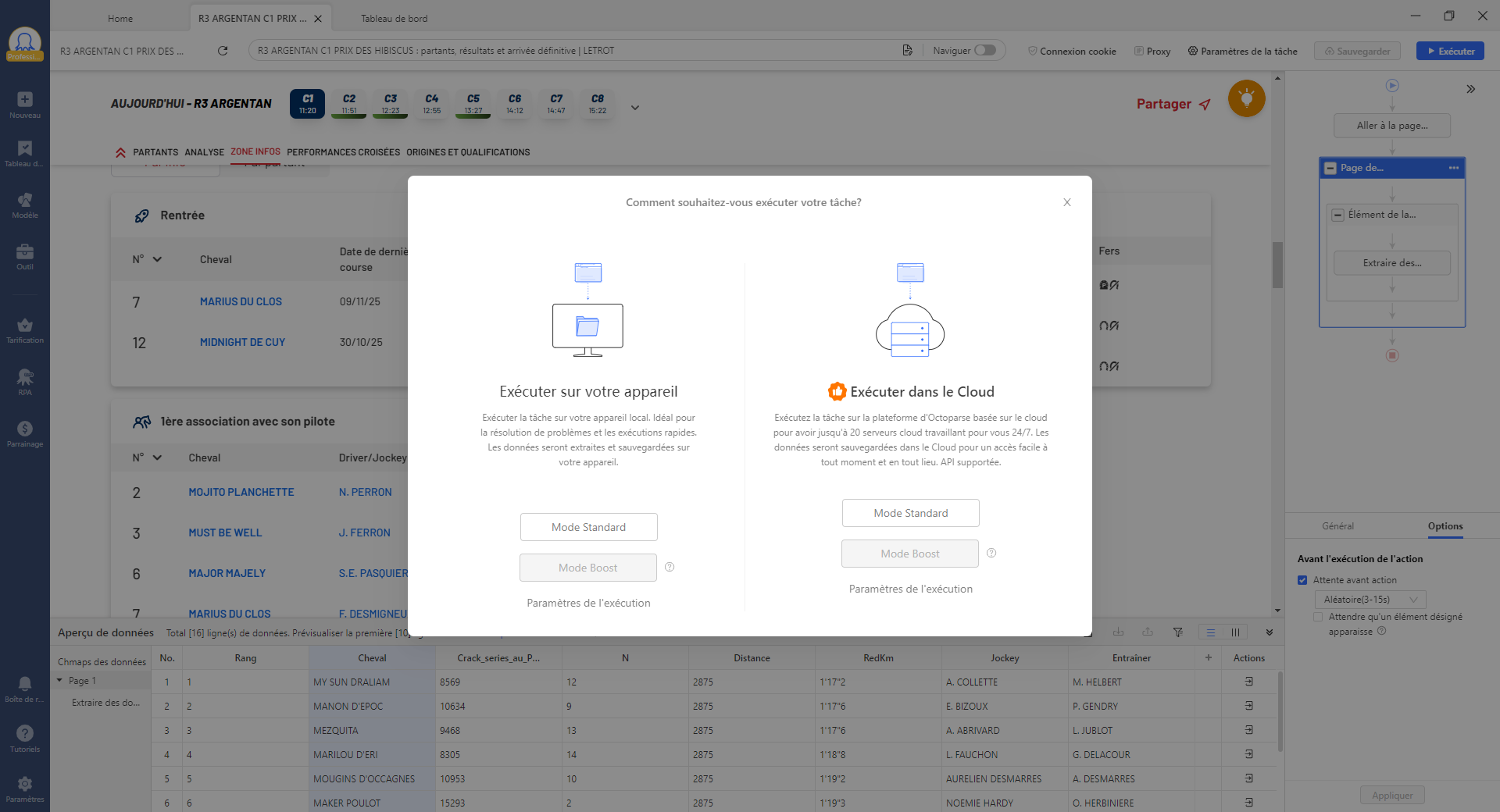
Étape 4 : lancer l’extraction et exporter en CSV
Une fois le workflow validé, cliquez sur Exécuter. Vous pouvez choisir entre :
- Extraction locale : les données sont collectées sur votre machine (gratuit)
- Extraction cloud : la tâche tourne sur les serveurs Octoparse, 24h/24, planifiable (plans payants)
À la fin de l’extraction, exportez vos données en CSV, Excel, JSON ou directement vers Google Sheets. Le fichier est immédiatement exploitable dans Python (Pandas), R, ou tout outil de data visualisation.

Transformer les sites hippiques vers Excel, CSV, Google Sheets ou base de données.
Auto-détecter les tableaux de courses et extraire les données sans aucun codage.
Scraper France Galop, LeTROT et d’autres sources en quelques clics avec les modèles pré-construits.
Ne jamais se retrouver bloqué grâce aux proxies IP rotatifs et à l’API avancée.
Planifier vos extractions dans le cloud pour une base de données hippiques toujours à jour.
Pour les développeurs : scraper les données PMU en Python
Si vous maîtrisez Python, vous pouvez écrire votre propre scraper. Voici une implémentation de base avec requests et BeautifulSoup, ciblant une page de résultats LeTROT.
À noter : depuis fin 2024, PMU.fr a renforcé ses mécanismes anti-bot. Les méthodes
requests+BeautifulSoupseules ne suffisent plus sur certaines pages dynamiques de PMU.fr. LeTROT, dont les pages de résultats sont accessibles sans connexion, reste une source fiable avec cette méthode.
Installation des bibliothèques
Récupération de la page HTML
Analyse du HTML et extraction des données
Export en CSV
L’API non documentée de PMU.fr : ce qu’il faut savoir
PMU.fr expose une API JSON officieuse, utilisée en interne. Elle permet d’accéder aux programmes, aux partants et aux résultats de manière structurée. Voici un exemple d’appel pour récupérer le programme d’une réunion :
Points d’attention :
- Cette API n’est pas publiée officiellement par PMU. Elle peut être modifiée ou désactivée sans préavis.
- Les identifiants d’endpoints varient selon la réunion (R1, R2…) et la course (C1, C2…). Il faut d’abord appeler l’endpoint de programme pour récupérer les identifiants valides de la journée.
- En cas de requêtes trop fréquentes, l’IP peut être temporairement bloquée.
Si la stabilité dans le temps est une priorité, une approche sans code est plus adaptée : elle ne nécessite aucune adaptation lorsque la structure de la page évolue, et les extractions peuvent être planifiées directement depuis l’interface. C’est particulièrement utile si vous souhaitez maintenir une base de données hippiques à jour chaque semaine sans intervention manuelle.
Données hippiques et IA : construire un modèle prédictif pas à pas
En 2025, le PMU a intégré l’intelligence artificielle à son propre CRM Salesforce pour mieux analyser le comportement de ses parieurs. Des projets communautaires francophones comme Turf BZH ou TurfMining exploitent déjà des pipelines de données automatisés pour alimenter leurs modèles de pronostic. Le traitement automatisé des données hippiques n’est plus réservé aux équipes techniques : les outils disponibles en 2026 permettent de mettre en place ce type de workflow en quelques heures.
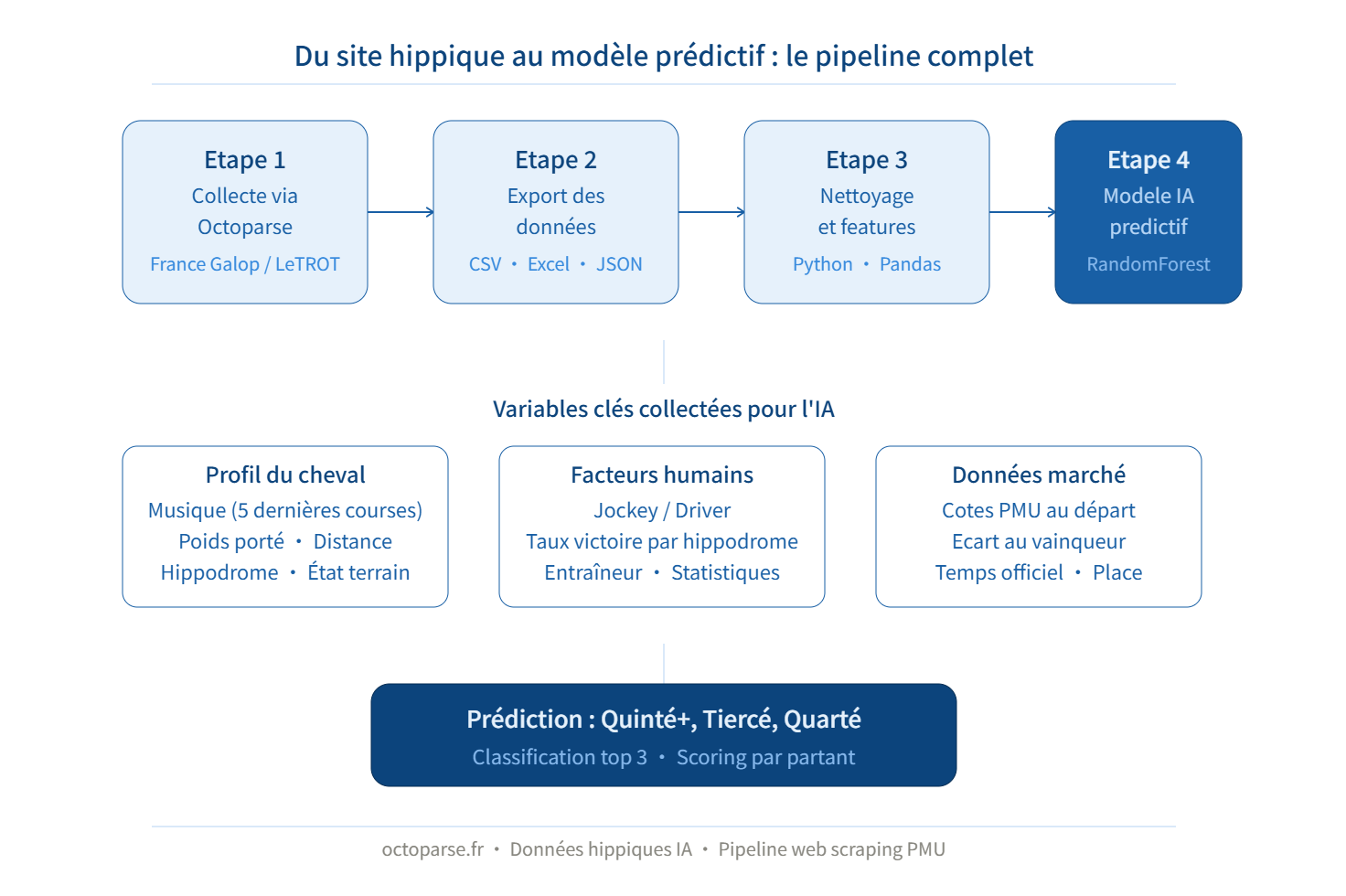
Une fois vos données exportées en CSV, elles sont directement exploitables pour construire un modèle prédictif. Voici le workflow complet, de la donnée brute à la prédiction :
Étape 1 : chargement et nettoyage des données hippiques
Étape 2 : construction des features pour le modèle prédictif
Les variables les plus pertinentes pour un modèle de prédiction hippique, selon les pratiques de la communauté turfiste française (TurfMining, Turf BZH, Boturfers) :
Étape 3 : entraînement du modèle de classification RandomForest
À garder à l’esprit : les performances d’un modèle prédictif hippique dépendent avant tout de la qualité et de la quantité des données d’entraînement. Plus l’historique est long et les variables nombreuses, plus le modèle sera fiable. Aucun algorithme ne supprime la part d’aléatoire inhérente aux courses hippiques.
Pour structurer vos données après extraction, l’article sur le nettoyage de données avec Octoparse couvre les étapes de normalisation les plus courantes.
Les paris hippiques sont réservés aux personnes majeures. Interdit aux moins de 18 ans. Si vous utilisez ces données à des fins de jeu, jouez de manière responsable : fixez-vous des limites de mise et de temps. L’Autorité nationale des jeux (ANJ) met à disposition une ligne d’écoute gratuite et confidentielle au 09 74 75 13 13.
FAQ – Questions fréquentes sur la collecte de données hippiques
- Peut-on récupérer les données PMU gratuitement en CSV ?
Oui. Octoparse propose un plan gratuit qui permet l’extraction locale sans limite de temps. Vous pouvez ainsi collecter les résultats de courses depuis France Galop ou LeTROT et les exporter en CSV directement depuis l’interface, sans aucun frais. L’extraction cloud (planifiée, en arrière-plan) est disponible sur les plans payants.
- Est-il nécessaire de savoir coder pour collecter des données hippiques ?
Non. Octoparse fonctionne entièrement en mode pointer-cliquer : vous sélectionnez visuellement les données que vous souhaitez extraire, et l’outil génère automatiquement le workflow. Aucune ligne de code, aucune configuration de serveur.
- Peut-on scraper d’autres sources que France Galop (LeTROT, ZeTurf, Geny…) ?
Oui. Octoparse s’adapte à n’importe quelle page web accessible publiquement. La méthode est identique à celle décrite dans ce tutoriel : vous ciblez l’URL, vous sélectionnez les éléments à extraire, vous exportez. Pour les sites qui chargent dynamiquement (JavaScript), Octoparse intègre un moteur de rendu compatible.
- Les données hippiques collectées peuvent-elles alimenter un modèle d’IA prédictif ?
Absolument. Les fichiers CSV exportés depuis Octoparse sont directement lisibles par Pandas (Python) ou R, les deux environnements les plus courants pour l’entraînement de modèles de machine learning. Plusieurs projets francophones (TurfMining, Turf BZH, Boturfers) exploitent ce type de pipeline pour construire des algorithmes de pronostic hippique.
- Quels types de paris hippiques bénéficient le plus de l’analyse de données ?
Le Quinté+ est le pari le plus analysé par les turfistes data-driven : il requiert de trouver les cinq premiers chevaux, dans l’ordre ou en combiné. La richesse des variables disponibles (musique du cheval, cotes, jockey, terrain) le rend particulièrement adapté à la modélisation statistique. Le Tiercé et le Quarté suivent la même logique, avec un nombre de partants à sélectionner inférieur.
- Le web scraping de sites hippiques est-il légal en France ?
La réponse dépend du contexte d’utilisation. En droit français, les bases de données bénéficient d’une protection spécifique au titre du droit sui generis des producteurs de bases de données (Directive européenne 96/9/CE, transposée dans le Code de la propriété intellectuelle). Extraire une partie substantielle d’une base de données protégée peut être considéré comme une atteinte à ces droits, même si les données sont accessibles publiquement.
Quelques repères pratiques :
- Consultez les CGU de chaque site avant toute collecte. PMU.fr, France Galop et LeTROT ont des conditions d’utilisation spécifiques sur la réutilisation des données.
- Respectez le fichier robots.txt du site cible : il indique les pages que l’opérateur souhaite exclure de tout scraping automatique.
- Espacez vos requêtes d’au moins quelques secondes pour ne pas surcharger le serveur.
- Réservez la collecte à un usage personnel ou de recherche. La revente ou la diffusion publique des données collectées présente des risques juridiques élevés.
En cas de doute, consultez un avocat spécialisé en propriété intellectuelle. Octoparse ne fournit pas de conseil juridique.
- Jusqu’où remonte l’historique des courses disponible sur PMU.fr ?
PMU.fr ne conserve en général qu’un à deux ans de résultats accessibles directement sur le site. Pour constituer un historique plus long, indispensable pour entraîner un modèle de machine learning, il faut soit collecter les données de manière continue depuis plusieurs saisons, soit combiner plusieurs sources (France Galop et LeTROT conservent des archives plus étendues sur leurs propres pages). C’est une des raisons pour lesquelles automatiser la collecte dès maintenant a plus de valeur qu’attendre.
- Quelle différence entre les données de galop (France Galop) et les données de trot (LeTROT) ?
Les deux disciplines ont des structures de données assez différentes. Le galop (France Galop) recense principalement les courses de plat et d’obstacles, avec des variables comme le poids porté, le temps officiel et la distance. Le trot (LeTROT) ajoute le type d’attelage (attelé ou monté) et la réduction kilométrique, qui est l’indicateur de performance central dans cette discipline. Si vous construisez un modèle prédictif, il est conseillé de séparer vos datasets selon la discipline plutôt que de les fusionner.
Lancer votre première extraction de données hippiques
La filière hippique française représente plus de 40 000 emplois et plusieurs milliards d’euros de mises chaque année. Derrière cette industrie, la demande pour des données structurées, fiables et régulièrement mises à jour ne fait qu’augmenter.
Que vous soyez turfiste souhaitant affiner vos analyses du Quinté+, data scientist en train de construire un modèle prédictif, ou développeur d’un service de pronostics, la collecte automatisée est aujourd’hui accessible sans barrière technique. France Galop et LeTROT publient des données en HTML statique bien structuré, exploitables dès la première extraction.
L’article sur l’analyse sportive avec le web scraping approfondit les cas d’usage si vous souhaitez exploiter ces données au-delà des courses hippiques.
Le plan gratuit d’Octoparse couvre l’extraction locale sans limite de durée, ce qui est suffisant pour constituer un historique de plusieurs saisons de courses. Les plans payants ajoutent l’extraction cloud planifiée, utile si vous souhaitez maintenir votre base de données à jour chaque semaine sans intervention manuelle.



