Vous avez finalement fait tourner votre scraper. Des milliers de lignes extraites, un beau fichier exporté. Vous l’ouvrez et là, c’est le chaos.
Des balises HTML noyées dans vos colonnes de texte. Des dates dans trois formats différents, parfois quatre. Des doublons partout. Du spam mélangé à de vrais avis clients. Et une colonne de prix qui affiche “null” une ligne sur deux.
C’est ça, la réalité du data cleaning. Personne n’en parle quand on vous vend la promesse de la “data-driven decision”. Le scraping, c’est la partie facile. Rendre vos données cohérentes, précises et réellement exploitables, c’est là que le travail commence.
Et ce n’est pas un problème marginal. Selon le baromètre Datamatics 2024, seulement 21 % des entreprises françaises ont mis en place un programme complet de qualité des données. 65 % font du contrôle ponctuel. 14 % ne vérifient rien du tout.
Ce qu’on entend vraiment par data cleaning
Le data cleaning (ou nettoyage de données, parfois appelé data cleansing) désigne le processus de détection et de correction des erreurs, incohérences et doublons dans un jeu de données, afin de le rendre fiable pour l’analyse ou la prise de décision.
Sur le papier, ça semble simple. En pratique, dès qu’on travaille avec des données issues du web scraping, cinq problèmes reviennent systématiquement :
- La standardisation des formats : des dates en “12/03/2025”, “03-12-25” et “12 mars 2025” dans la même colonne, des numéros de téléphone avec ou sans indicatif, des adresses avec ou sans cedex
- La suppression des doublons : des fiches entreprises extraites plusieurs fois depuis PagesJaunes ou Societe.com, avec de légères variations orthographiques
- L’élimination du bruit : des balises <br>, <p>, des caractères spéciaux, des espaces insécables dans vos champs texte
- La gestion des valeurs manquantes : des cellules vides, des “N/A”, des “null” qui bloquent vos formules et faussent vos dashboards
- L’extraction d’entités : isoler un nom de marque dans un texte libre, extraire un prix depuis une phrase, récupérer une ville depuis une adresse complète
Ces cinq problèmes ne sont pas indépendants. Ils se cumulent, et chacun suffit à rendre un fichier inutilisable pour une analyse sérieuse.

Pourquoi les outils classiques ne suffisent plus
Excel et Google Sheets restent les réflexes de beaucoup d’équipes françaises. Pour 500 lignes et deux colonnes à corriger, ça passe. Mais dès qu’on parle de 50 000 fiches issues d’un nettoyage de données après scraping sur Leboncoin, de 200 000 avis Trustpilot ou d’un export hebdomadaire automatisé depuis plusieurs sources, la limite est immédiate.
Les solutions traditionnelles posent trois problèmes concrets :
Le passage à l’échelle : nettoyer manuellement un fichier de 10 000 lignes prend des heures. Automatiser ce travail avec des macros Excel suppose des compétences VBA que la plupart des équipes marketing ou commerciales n’ont pas.
La répétabilité : quand votre scraping tourne toutes les semaines, vous ne pouvez pas reprendre la même procédure manuelle à chaque fois. Il vous faut un pipeline de données de nettoyage reproductible.
La gestion du contenu scrappé : les balises HTML, les encodages UTF-8 mal gérés, les entités JavaScript sont des problèmes spécifiques aux données web. Excel n’a pas été conçu pour ça.
Selon une analyse d’IBM Global Data Management Survey, une mauvaise qualité des données coûte en moyenne 12,9 millions de dollars par an aux grandes entreprises. Pour une PME ou une ETI française, l’ordre de grandeur est différent, mais les mécanismes de perte sont identiques : décisions prises sur des chiffres incorrects, doublons dans le CRM, campagnes envoyées aux mauvaises adresses.
Les outils de nettoyage de données disponibles en France
Selon votre profil technique et le volume de données, plusieurs options s’offrent à vous.
Pour les équipes non techniques :
OpenRefine : outil open source gratuit, recommandé par data.gouv.fr pour le nettoyage de données textuelles. Idéal pour dédoublonner, standardiser des formats, corriger des incohérences sur des volumes moyens. Interface visuelle, pas de code requis.
Octoparse : pour les données issues du web scraping, le module de nettoyage intégré traite les données directement dans le pipeline de données de collecte, sans avoir à les exporter puis les retraiter dans un outil externe. Si votre problème commence au moment du scraping, c’est là qu’il faut le régler.
Pour les équipes techniques ou les volumes importants :
Talend Data Quality : éditeur d’origine française (désormais intégré à Qlik), référence sur le marché enterprise pour la standardisation, la déduplication et la gouvernance des données à grande échelle. Particulièrement adapté aux architectures ETL complexes.
Dataiku : plateforme française de data science collaborative, adaptée aux équipes qui veulent combiner nettoyage, transformation et machine learning dans un même environnement. Très utilisée dans les grandes entreprises françaises.
Python (pandas) : pour les profils développeurs, la bibliothèque pandas offre une flexibilité totale sur le nettoyage de données automatique. Elle suppose du temps de développement et de maintenance, mais reste la solution de référence pour les pipelines complexes.
OpenRefine via data.gouv.fr : pour les équipes des secteurs public ou associatif, c’est souvent la première recommandation officielle française pour la préparation de données.
Comment fonctionne le nettoyage de données dans Octoparse
Octoparse prend le problème à la racine : plutôt que de vous laisser exporter des données brutes à nettoyer ensuite, le moteur de nettoyage s’intègre directement dans le pipeline de données de collecte.
L’approche repose sur deux couches complémentaires.
La couche IA génère automatiquement des expressions régulières adaptées à vos données. Vous n’avez pas besoin de savoir écrire un regex pour extraire un prix, un nom de marque ou un code postal français. Le moteur analyse le contenu et propose les patterns de nettoyage correspondants.
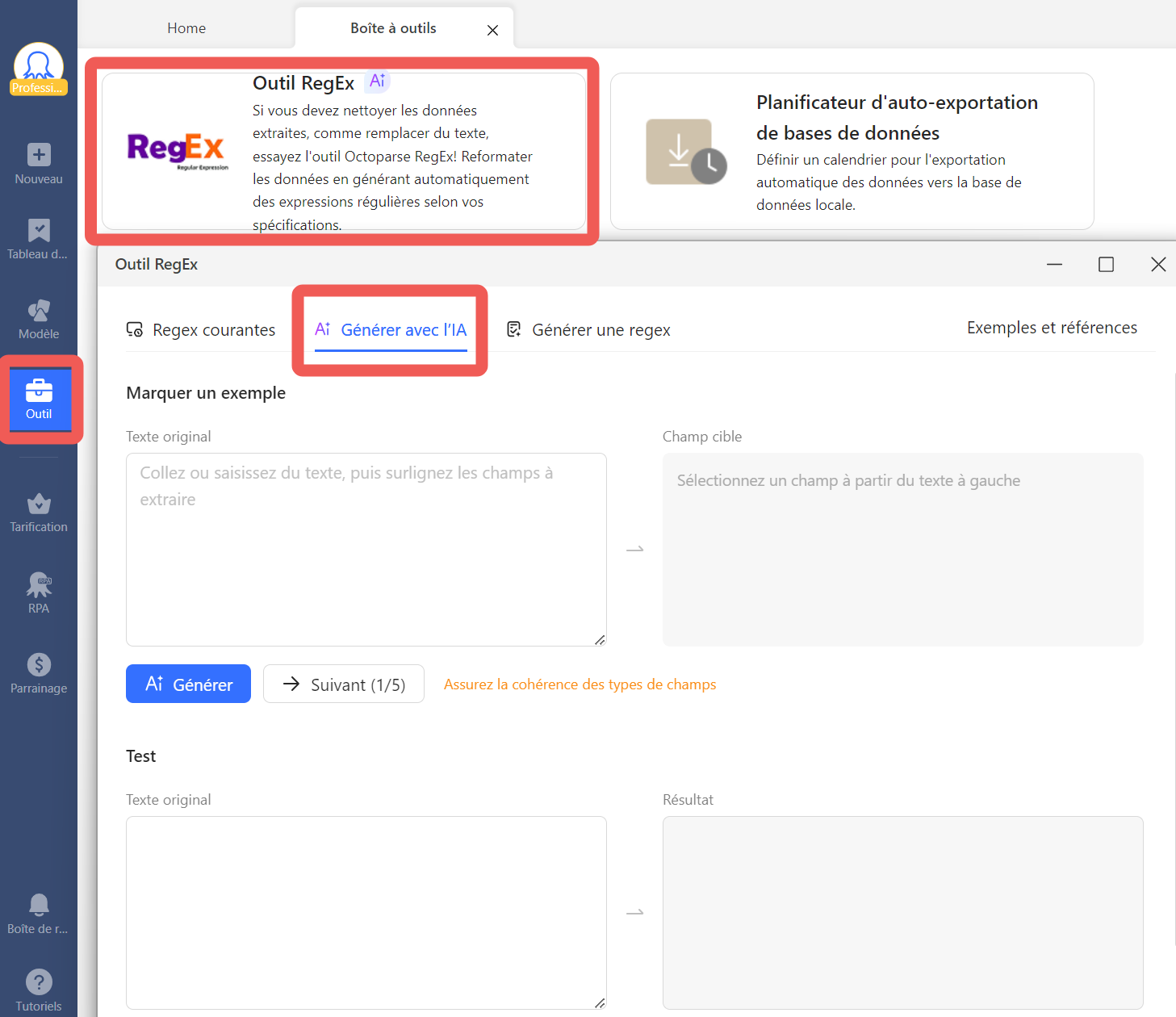
La couche de règles configurables prend en charge les tâches de précision : standardisation des formats de date, suppression des balises HTML, déduplication, extraction de champs spécifiques depuis un texte libre. Ces règles s’appliquent visuellement, sans ligne de code.
Les deux couches se combinent dans une interface no-code. Vos données sortent propres directement, sans étape de retraitement externe.
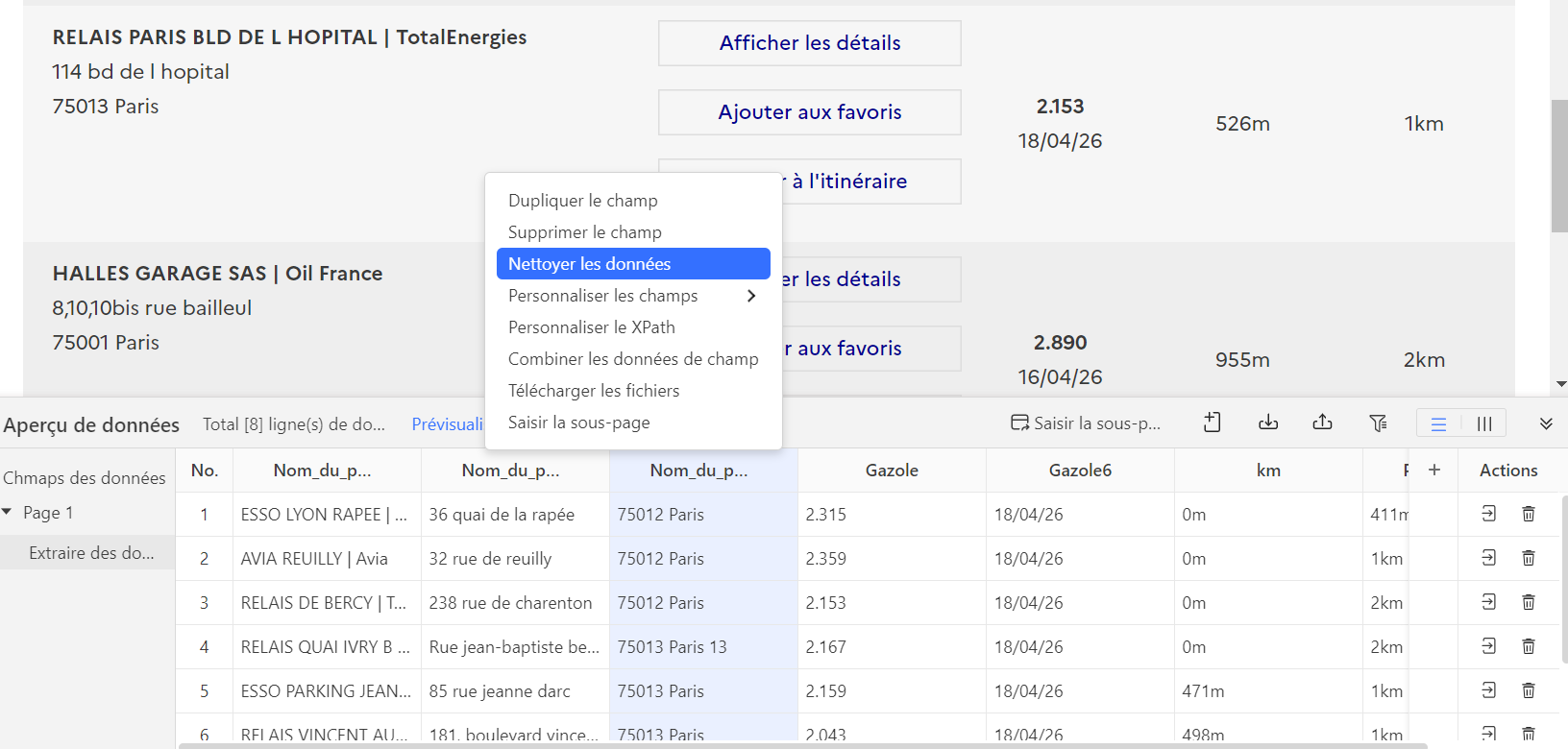
Voici les étapes principales dans Octoparse pour configurer le nettoyage :
- Dans votre tâche Octoparse, après avoir configuré l’extraction, cliquez sur le champ de données à nettoyer
- Sélectionnez “Nettoyer les données” dans le menu contextuel
- Choisissez le type de nettoyage : suppression HTML, extraction regex, déduplication, standardisation de format
- Pour les regex, utilisez l’option “Générer avec IA” pour laisser le moteur proposer le pattern adapté à vos données
- Testez le résultat en aperçu avant de lancer l’extraction complète
Cas d’usage concrets : ce que le data cleaning permet de traiter
Génération de leads B2B depuis des annuaires français
Les données extraites de PagesJaunes, Societe.com ou Kompass contiennent systématiquement des formats hétérogènes : numéros de téléphone avec ou sans le 0 initial, adresses avec ou sans code cedex, noms d’entreprises en majuscules ou en casse mixte. Le moteur de règles standardise ces formats automatiquement. La fonction de déduplication filtre les doublons avant l’export, pour que votre fichier de prospection soit directement utilisable dans votre CRM.
Si vous scrapez ces annuaires avec Octoparse, nos articles sur la prospection B2B via PagesJaunes et sur Google Maps comme source de leads vous donnent le contexte complet.
Veille tarifaire sur les sites e-commerce français
Scraper les prix sur Cdiscount, Amazon.fr ou Fnac produit souvent des colonnes mixtes : “29,99 €”, “29.99€”, “À partir de 29,99 €”. L’extraction par regex isole la valeur numérique propre, prête pour comparaison ou graphique. Pour aller plus loin sur la surveillance des prix, notre article sur le suivi des prix Amazon couvre les outils et méthodes disponibles.
Analyse d’avis clients depuis Trustpilot ou Google My Business
Les avis scrapés contiennent du texte libre mêlé à des balises HTML, des emojis, des caractères d’échappement. Le nettoyage HTML supprime le bruit, la déduplication élimine les redondances entre sources, et les pipelines avancés permettent d’ajouter une couche d’analyse de sentiment sur les données nettoyées. Notre article sur le scraping Trustpilot détaille la méthode d’extraction.
Collecte de données presse depuis Le Monde, Le Figaro ou des sites sectoriels
Les métadonnées d’articles (titre, auteur, date, catégorie) arrivent dans des formats variables selon les sites. La normalisation des dates en ISO 8601, la standardisation des noms d’auteurs et l’extraction des tags permettent de constituer une base d’articles exploitable pour la veille ou l’analyse de tendances. Nous avons traité ce cas dans notre article sur le scraping de Le Figaro.
Pour collecter ces coordonnées à grande échelle sans effort manuel, le Contact Details Scraper d’Octoparse extrait automatiquement emails, numéros de téléphone et liens sociaux depuis n’importe quel annuaire en ligne, directement intégrés dans votre pipeline de nettoyage :
https://www.octoparse.fr/template/contact-details-scraper

Exporter vers Excel, CSV, Google Sheets ou base de données en un clic.
Détecter et extraire automatiquement les données de n’importe quel site.
Nettoyer les données directement dans le pipeline : suppression HTML, déduplication, normalisation de formats.
Contourner les blocages grâce aux proxies IP rotatifs et à l’API avancée.
Planifier et automatiser vos extractions depuis le cloud.
RGPD et data cleaning : ce que dit la CNIL
En France, le nettoyage de données n’est pas seulement une question d’efficacité. C’est aussi une obligation légale dans certains cas.
La CNIL rappelle que le principe de minimisation des données (article 5.1.c du RGPD) impose de supprimer les données non pertinentes dès qu’elles sont identifiées, y compris celles collectées par scraping. Concrètement, si votre pipeline de collecte capture des données personnelles que vous n’avez pas besoin de conserver, vous avez l’obligation de les supprimer rapidement après la collecte.
Le nettoyage intégré au pipeline de scraping, plutôt qu’effectué après coup, facilite cette conformité. Vous définissez en amont les champs à conserver, les données personnelles à écarter ou à anonymiser, et le moteur applique ces règles à chaque extraction automatiquement.
Depuis juin 2025, la CNIL a par ailleurs durci son cadre sur les pratiques de moissonnage. La fiche CNIL sur le moissonnage de données et la page sur la réutilisation des données publiques à des fins commerciales sont les deux références à consulter avant de déployer un pipeline de collecte impliquant des données personnelles.
Notre article sur la légalité du scraping en France couvre ce sujet en détail dans le contexte francophone.
FAQ
- C’est quoi le data cleaning ?
Le data cleaning, ou nettoyage de données, est le processus qui consiste à identifier et corriger les erreurs, incohérences, doublons et valeurs manquantes dans un jeu de données, afin de le rendre fiable pour l’analyse. Il inclut la standardisation des formats, la déduplication, l’élimination du bruit et l’extraction d’entités structurées depuis du texte libre.
- Quels sont les 3 types de nettoyage de données les plus courants ?
Les trois opérations les plus fréquentes sont la déduplication (suppression des entrées en double), la standardisation des formats (dates, numéros de téléphone, adresses) et la suppression du bruit (balises HTML, caractères parasites, valeurs nulles). Dans le cadre du web scraping, on y ajoute souvent l’extraction d’entités spécifiques depuis du texte libre, comme un prix ou un code postal.
- Quel est le meilleur logiciel pour nettoyer des données ?
Tout dépend du volume et du profil technique. Pour des données issues du scraping web, Octoparse intègre un moteur de nettoyage directement dans le pipeline de collecte, ce qui évite une étape de retraitement externe. Pour les volumes enterprise, Talend (d’origine française) et Dataiku sont les références du marché français. Pour les besoins ponctuels sur des volumes moyens, OpenRefine reste l’option gratuite la plus utilisée en France, recommandée par data.gouv.fr.
- Pourquoi le nettoyage des données est-il nécessaire ?
Des données brutes issues du scraping ne sont pas directement exploitables : formats incohérents, doublons, balises HTML, valeurs manquantes. Sans nettoyage, vos analyses sont faussées, vos exports CRM créent des doublons, et vos dashboards affichent des chiffres incorrects. En France, le RGPD ajoute une dimension réglementaire : les données non pertinentes doivent être supprimées rapidement après la collecte.
- Le nettoyage de données peut-il se faire sans coder ?
Oui. Des outils comme Octoparse et OpenRefine permettent d’effectuer les opérations de nettoyage les plus courantes via une interface visuelle, sans écrire une seule ligne de code. Pour des besoins avancés comme les analyses de sentiment ou les règles métier complexes, une couche Python ou SQL peut être utile, mais elle reste optionnelle pour la grande majorité des cas d’usage.
- Comment fonctionne le nettoyage IA dans Octoparse ?
Le moteur IA d’Octoparse génère automatiquement des expressions régulières adaptées au contenu de vos données. Il analyse les patterns présents dans vos colonnes et propose des règles de nettoyage correspondantes, que vous ajustez visuellement. Cela évite d’avoir à écrire des regex manuellement pour extraire des prix, des codes postaux, des noms de marques ou tout autre type d’entité structurée.
- Le data cleaning est-il concerné par le RGPD en France ?
Oui. La CNIL impose de supprimer les données personnelles non pertinentes dès leur identification, y compris dans les données collectées par scraping. Intégrer le nettoyage au pipeline de collecte plutôt que de le faire après coup facilite cette conformité et réduit le risque d’exposition à des données sensibles inutiles. Depuis juin 2025, la CNIL a renforcé ses exigences sur ce point.



