OpenClaw est un agent IA open source qui exécute des tâches de code à votre place, sans abonnement Anthropic. Il s’installe localement, fonctionne avec n’importe quel modèle LLM (GPT-4, Mistral, LLaMA…), et représente l’alternative gratuite la plus populaire à Claude Code en 2026. Ce guide compare ses fonctionnalités réelles, ses limites et ses cas d’usage concrets.
Un ingénieur californien se réveille et apprend que son agent IA a passé la nuit à négocier l’achat d’une voiture à sa place. 4 200 dollars économisés sur le prix catalogue, sans un seul appel téléphonique de sa part. Une autre utilisatrice découvre, elle, qu’une réclamation d’assurance abandonnée a finalement été réouverte : son agent avait rédigé et envoyé une lettre de contestation, seul.
Ces deux histoires ont circulé sur les forums tech début 2026, documentées par leurs auteurs eux-mêmes. OpenClaw, l’agent IA open source derrière ces automatisations, a dépassé les 340 000 étoiles GitHub en moins de quatre mois, un rythme de croissance que Docker, Kubernetes ou React n’avaient jamais atteint.
Mais qu’est-ce qu’OpenClaw exactement, et comment fonctionne-t-il concrètement ? En quoi est-il différent d’un ChatGPT ou d’un Claude ? Quelles sont ses fonctionnalités réelles, et à quoi peut-il vraiment vous servir au quotidien ? Les réponses qui suivent s’appuient sur des cas documentés et des données vérifiées.
Qu’est-ce qu’OpenClaw, exactement ?
OpenClaw est un agent IA autonome open source, auto-hébergé, qui s’exécute sur votre propre machine ou serveur. Il ne se contente pas de répondre à vos questions : il exécute des tâches réelles en votre nom, comme envoyer des emails, gérer votre agenda, lancer des scripts, extraire des données de pages web, piloter un navigateur, ou répondre à des messages WhatsApp pendant que vous dormez.
Ce qui distingue OpenClaw d’un chatbot classique tient en un seul mot : l’action. ChatGPT génère du texte dans un onglet de navigateur. OpenClaw, lui, agit sur vos systèmes, en continu, depuis vos propres infrastructures. C’est d’ailleurs l’image que retenait Clubic dans son premier test : un J.A.R.V.I.S. qui tourne sur votre propre machine.
Concrètement : OpenClaw, c’est un agent IA open source qui tourne sur votre machine ou VPS, se connecte à vos messageries (WhatsApp, Telegram, Slack…) et gère vos tâches en continu, sans dépendre d’aucun service cloud tiers.
De Clawdbot à OpenClaw : l’histoire derrière le nom
Pour comprendre OpenClaw, il faut remonter à novembre 2025. Peter Steinberger, développeur autrichien et fondateur de PSPDFKit, lance un projet personnel baptisé Clawdbot, en référence directe au nom Claude d’Anthropic.
En moins de 72 heures, le dépôt GitHub dépasse les 60 000 étoiles. Anthropic intervient alors : une plainte pour atteinte à la marque contraint Steinberger à renommer le projet. Clawdbot devient d’abord Moltbot sous la contrainte juridique, puis OpenClaw officiellement le 30 janvier 2026, après un vote de la communauté sur les forums du projet. La presse (Wired, CNET, Axios) continue cependant souvent d’employer l’ancien nom Moltbot, ce qui explique la confusion fréquente dans les recherches.
Le 14 février 2026, Steinberger annonce sur son blog qu’il rejoint OpenAI pour « piloter la prochaine génération d’agents personnels ». Sam Altman confirme sur X qu’OpenClaw sera hébergé par une fondation en tant que projet open source, avec le soutien continu d’OpenAI. Le projet ne disparaît pas : il bascule simplement vers un modèle de gouvernance open source plus stable.
Moltbook : le réseau social réservé aux agents IA qui a compté 1,5 million de membres en une semaine
Aucun graphique de croissance GitHub ne résume aussi bien l’ampleur du phénomène OpenClaw que l’existence de Moltbook. Ce réseau social, lancé le 28 janvier 2026, pose une règle unique : seuls les agents IA peuvent poster. Les humains observent, mais n’interagissent pas.
En 72 heures, 32 000 agents s’y étaient inscrits. En une semaine : 1,5 million. Les agents y débattaient de conscience artificielle et, dans un incident largement médiatisé, ont fondé une religion numérique baptisée Crustafarianism (contraction de « crustacé » et de « rastafarianism »), avec des prophètes désignés via des scripts shell modifiant leurs propres fichiers de configuration.
Andrej Karpathy, cofondateur d’Eureka Labs et ancien responsable de l’IA Autopilot chez Tesla, a qualifié Moltbook de « la chose la plus incroyable, proche du décollage sci-fi, que j’aie vue récemment ». Au-delà du spectacle, Moltbook a révélé une vulnérabilité critique : la base de données backend était accessible sans authentification, donnant accès à 500 000 clés API et 35 000 adresses email. Un rappel que dans l’écosystème OpenClaw, la popularité n’a pas attendu les garde-fous.
Comment fonctionne OpenClaw ?
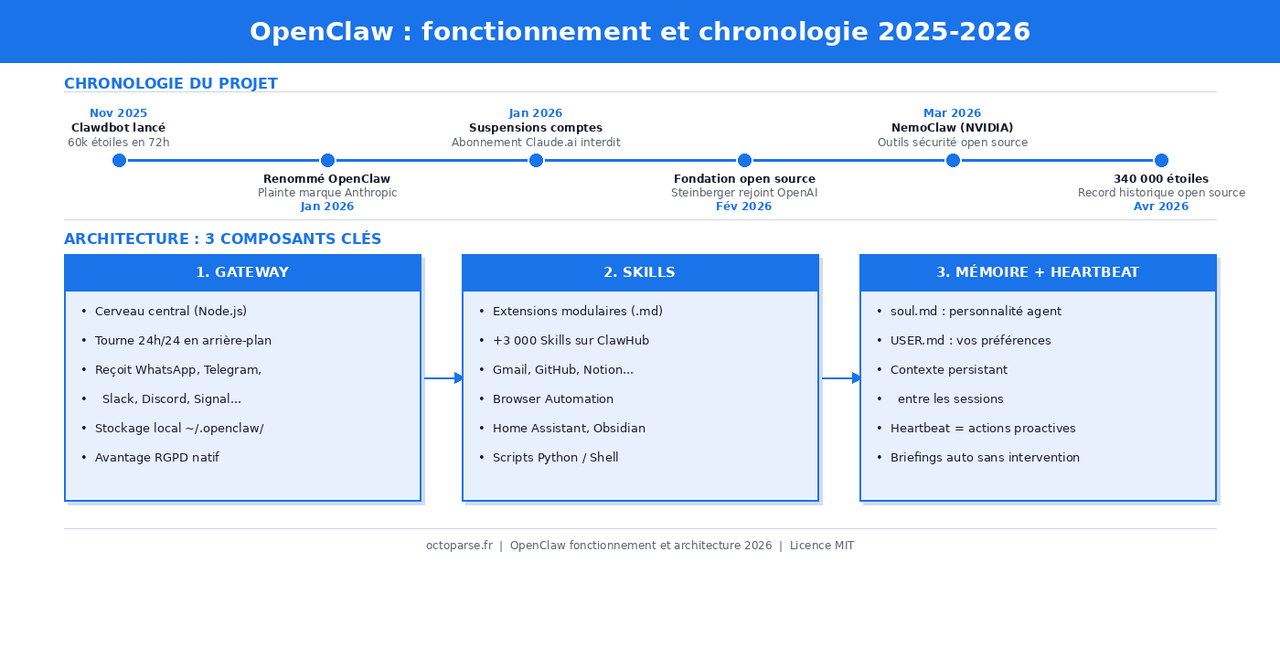
L’architecture d’OpenClaw repose sur trois composants interdépendants. Voici ce que chacun fait concrètement.
Le Gateway : le cerveau de l’opération
Ce qui distingue OpenClaw des agents cloud, c’est que tout reste chez vous. Le Gateway est le processus central qui tourne en tâche de fond sur votre machine ou VPS, 24h/24, sur le port 18789 par défaut. C’est lui qui reçoit vos messages depuis WhatsApp, Telegram, Slack, Discord, iMessage ou Signal, interroge le modèle IA de votre choix, orchestre les Skills et maintient la mémoire des tâches en cours.
Les données de configuration et l’historique des interactions sont stockés localement dans ~/.openclaw/, ce qui constitue un avantage concret pour la conformité RGPD (voir la section dédiée plus bas).
Techniquement, le Gateway fonctionne en trois étapes pour chaque message :
- Assemblage du contexte : récupération de l’historique de session, des fichiers workspace et des métadonnées de tâche
- Interrogation du modèle IA : envoi du prompt complet, itérations d’outils possibles (jusqu’à 20 passes pour les tâches complexes)
- Exécution des outils et stockage des résultats en session persistante
Les Skills : les mains d’OpenClaw
Les Skills sont des fichiers Markdown modulaires définis par un fichier skill.md et des scripts associés. Ils étendent les capacités d’OpenClaw dans un domaine précis : navigation web, gestion d’emails Gmail, interactions GitHub, scraping de pages web, ou encore pilotage de Notion ou Obsidian. Elles sont regroupées sur ClawHub, le registre officiel, qui en recense plus de 3 000 début 2026.
Exemples de Skills populaires sur ClawHub
- Gmail / Outlook : lecture, triage et envoi d’emails automatisés
- GitHub : suivi des PR, gestion des issues, revues de code
- Tavily Search : recherche web en temps réel
- Notion / Obsidian : création et mise à jour de bases de connaissances
- Browser Automation : navigation, scraping, screenshots sans code
- ElevenLabs : synthèse vocale et appels téléphoniques automatisés
- Home Assistant : pilotage de la domotique via messagerie
- n8n Skill (ClawHub) : connecteur natif vers les workflows n8n, utile pour les équipes no-code qui automatisent déjà avec n8n et veulent y intégrer OpenClaw
Comment installer une Skill OpenClaw ?
L’installation se fait en trois étapes depuis le terminal : cloner le dépôt de la Skill dans le répertoire ~/.openclaw/skills/, vérifier le contenu du fichier skill.md (description, permissions demandées, auteur), puis redémarrer le Gateway pour que la Skill soit reconnue. Depuis l’interface web d’openclaw.ai, l’installation se fait en un clic depuis le catalogue ClawHub. Avant toute installation, vérifiez systématiquement le nombre d’étoiles GitHub de la Skill, la date de dernière mise à jour et les permissions déclarées — une Skill légitime ne demande jamais vos credentials en clair.
En février 2026, 341 extensions malveillantes ont été retirées de ClawHub (trojans, infostealers). Vérifiez toujours le nombre d’étoiles et le contenu du fichier skill.md avant installation. Une Skill légitime ne demande jamais vos credentials en clair.
La mémoire persistante et le Heartbeat
Contrairement aux chatbots qui repartent de zéro à chaque conversation, OpenClaw maintient une mémoire à long terme dans des fichiers Markdown locaux (soul.md pour la personnalité de l’agent, USER.md pour vos préférences). Un mécanisme de heartbeat (similaire à un job cron) lui permet d’agir de façon proactive, sans attendre vos messages : backups automatiques, monitoring de builds, briefings matinaux, tri d’emails. C’est précisément ce qui sépare OpenClaw d’un chatbot ordinaire.
Pour comparer OpenClaw avec les principaux outils de coding IA du marché, notre comparatif OpenClaw vs Claude Code vs Cursor détaille les différences de positionnement, de coût et de cas d’usage.
Fonctionnalités d’OpenClaw : ce que l’agent sait faire
Au-delà du fonctionnement technique, voici les fonctionnalités concrètes qui expliquent l’adoption rapide d’OpenClaw auprès des équipes tech françaises :
| Fonctionnalité | Description | Niveau technique requis |
| Messagerie multi-canaux | WhatsApp, Telegram, Slack, Discord, Signal, iMessage, Teams | Faible |
| Mémoire persistante | soul.md, USER.md, historique sessions longue durée | Faible |
| Heartbeat proactif | Actions planifiées sans intervention humaine (cron-like) | Moyen |
| Skills modulaires | +3 000 extensions disponibles sur ClawHub | Faible à moyen |
| Multi-agents | Coordination de plusieurs agents avec rôles distincts | Élevé |
| Browser Automation | Navigation web, extraction de données en langage naturel | Moyen |
| Compatibilité MCP | Connexion standardisée à des outils externes | Moyen |
| API publique Octoparse | Déclenchement d’extractions structurées à grande échelle | Moyen |
Modèles IA compatibles : choisir le bon cerveau pour OpenClaw
| Modèle | Coût indicatif API | Confidentialité | Cas d’usage recommandé | Risque suspension |
| Claude Opus 4.6 / Sonnet 4.6 | ~0,003-0,015 €/1k tokens | Cloud Anthropic | Raisonnement complexe, tâches nuancées | Faible (clé API) |
| GPT-4o / GPT-5 (OpenAI) | Variable | Cloud OpenAI | Code, automatisations techniques | Faible |
| Gemini 2.0 Flash / Pro (Google) | ~0,0001-0,00125 €/1k tokens | Cloud Google | Multimodal, traitement d’images | Moyen (voir alerte) |
| DeepSeek R1 | ~0,0001 €/1k tokens | Cloud CN | Raisonnement, code, coût réduit | Faible |
| Kimi K2.5 | ~0,002 €/1k tokens | Cloud CN | Tâches économiques post-suspensions | Faible |
| Mistral 7B (Ollama) | 0 € (infra locale) | 100 % local | Français natif, rédaction FR | Aucun |
| Ollama (local) | 0 € (infra locale) | 100 % local | Confidentialité max, coût API zéro | Aucun |
Un point que beaucoup de nouveaux utilisateurs ignorent : utiliser votre abonnement Claude.ai (20 €/mois) pour piloter OpenClaw est explicitement interdit par Anthropic depuis janvier 2026, suite aux suspensions massives de comptes. Pour utiliser Claude comme modèle IA dans OpenClaw, il faut passer par une clé API Anthropic distincte, facturée à l’usage. C’est souvent moins cher qu’un abonnement mensuel si votre usage reste modéré.
Les tarifs indiqués correspondent aux tokens d’entrée (input). Les tokens de sortie sont facturés 3 à 5 fois plus cher selon le modèle. Pour Claude Sonnet 4.6 : $3/M tokens en entrée, $15/M en sortie. Chaque tâche OpenClaw déclenche 5 à 10 appels API distincts avec rechargement du contexte complet à chaque fois.
Depuis janvier 2026, plusieurs utilisateurs ont signalé des suspensions de compte Google après avoir utilisé Gemini via OpenClaw sans clé API dédiée. Utilisez toujours une clé API depuis Google AI Studio, jamais vos credentials Google personnels.
À quoi sert OpenClaw concrètement ? Cas d’usage réels
Automatisation personnelle et productivité
Briefing matinal automatique (l’agent scrape les flux RSS, Reddit et X/Twitter, déduplique et envoie un résumé sur Discord), triage de boîte mail, gestion de rappels, mise à jour d’un Notion ou d’un Obsidian depuis une conversation WhatsApp. Ces usages sont devenus courants chez les consultants et freelances français, notamment ceux qui jonglent entre plusieurs clients sans assistant dédié. Si vous débutez avec la collecte automatisée, les trois méthodes d’extraction les plus utilisées en 2026 sont détaillées dans un article dédié.
Nicolas Guyon, consultant IA parisien, fait tourner son agent OpenClaw « Jean-Claw » sur un Mac Mini dédié depuis début 2026. Au bout d’une semaine : 44 sources surveillées, un briefing envoyé sur Telegram à 7h05 chaque matin, et aucune intervention manuelle. Il en a tiré un retour d’expérience détaillé sur sept jours de fonctionnement en continu, publié sur son Substack.
Workflows développeur et DevOps
OpenClaw s’intègre nativement avec GitHub pour surveiller les PR, gérer les issues et déclencher des notifications. Des développeurs rapportent avoir fait tourner des agents de code pendant la nuit et avoir retrouvé des pull requests prêtes à relire le matin. Pour automatiser plus finement la collecte de données issues de vos outils de dev, la documentation de l’API Octoparse explique comment coupler extraction web et pipelines programmés.
Castelis, entreprise française spécialisée dans l’intégration de solutions cloud pour les PME, a publié un retour d’expérience documenté sur le déploiement de dix agents OpenClaw en parallèle sur un serveur Debian minimal (2 vCPU, 2 Go de RAM), coût d’infrastructure quasi nul. L’un des rares exemples documentés d’usage multi-agents par une entreprise française.
Extraction de données et automatisation web
La Browser Automation Skill permet à OpenClaw de naviguer et d’extraire des données en langage naturel. C’est une forme de web scraping piloté par agent, utile pour des tâches ponctuelles : vérifier un prix, surveiller une page, récupérer un résultat de recherche. Si votre objectif est la veille de marché, savoir quelles sources surveiller en priorité fait toute la différence sur la qualité du signal reçu.
Cette approche a ses limites dès que le volume ou la fiabilité deviennent critiques. OpenClaw n’est pas conçu pour scraper des milliers de pages structurées, gérer des CAPTCHAs ou produire des exports CSV/JSON reproductibles. Pour ces besoins spécifiques (génération de leads B2B, veille tarifaire, monitoring e-commerce), un outil avec des pipelines dédiés et une conformité RGPD intégrée est plus adapté.
Octoparse propose des modèles prêts à l’emploi pour les cas d’usage les plus courants : scraping Google Maps, surveillance Amazon et suivi TikTok.
Domotique et Home Assistant
OpenClaw se connecte à Home Assistant via une Skill dédiée, permettant de piloter des appareils connectés (lumières, thermostats, volets roulants, chaudière) depuis une conversation WhatsApp. Ce cas d’usage prend de l’ampleur dans la communauté, notamment sur forum.hacf.fr (Home Assistant Communauté Francophone) et le subreddit r/homeassistant.
Scraping marketing et analyse concurrentielle
Pour les équipes marketing, OpenClaw peut couvrir plusieurs tâches de veille en autonomie : surveillance des prix concurrents, extraction d’avis clients, monitoring des réseaux sociaux. Pour les équipes marketing sans développeur, comment automatiser la veille de marque avec le scraping couvre les cas d’usage les plus courants.
Pour les besoins de collecte structurée à plus grande échelle, deux modèles Octoparse s’intègrent directement :
https://www.octoparse.fr/template/google-search-scraper
https://www.octoparse.fr/template/contact-details-scraper
Pour explorer l’ensemble des modèles disponibles par cas d’usage, retrouvez nos scrapers dédiés aux réseaux sociaux, à Amazon et à l’extraction d’emails.
OpenClaw et le protocole MCP : connecter vos outils en moins de dix minutes
C’est dans cette logique de complémentarité que s’inscrit la compatibilité MCP d’OpenClaw. Depuis début 2026, le protocole MCP (Model Context Protocol, développé par Anthropic) s’est imposé comme référence pour connecter les agents IA à des outils externes de façon sécurisée.
OpenClaw est désormais compatible avec les serveurs MCP, ce qui ouvre des possibilités d’intégration bien au-delà des Skills natives. La procédure de configuration MCP prend moins de dix minutes si vous suivez ceguide pas à pas dédié aux équipes non techniques.
Si vous utilisez déjà Claude, transformer Claude en agent de collecte structurée via MCP prend moins d’une heure de configuration.
OpenClaw peut piloter Octoparse via son API publique, ce qui permet de déclencher des extractions, récupérer les résultats et les injecter dans vos pipelines de données. L’API Octoparse détaille tous les endpoints disponibles pour ce type d’intégration programmatique.
Exemple de workflow OpenClaw + API Octoparse
- L’agent OpenClaw surveille votre messagerie et détecte une demande d’extraction récurrente
- Via un script Shell ou Python (Skill personnalisée), il appelle l’API Octoparse pour déclencher un template de scraping
- Une fois l’extraction terminée, il interroge l’API pour récupérer les données exportées
- Il envoie un résumé structuré sur Slack ou par email, avec lien vers le fichier CSV/JSON
- Les données peuvent être versées dans Google Sheets ou un CRM via une étape supplémentaire
Sécurité OpenClaw : faille CVE, Skills malveillantes et checklist
En janvier 2026, les chercheurs de DepthFirst ont identifié la vulnérabilité CVE-2026-25253 sur NVD (CVSS 8.8/10) : une faille WebSocket permettant à un site web malveillant de voler le token d’authentification en un clic, puis d’obtenir une exécution de code arbitraire. La faille a été corrigée dans la version 2026.1.29. Sur ClawHub, 341 extensions malveillantes ont été recensées en février 2026 : trojans, infostealers et backdoors déguisés en outils crypto, avant d’être retirées.
Si vous utilisez une version antérieure à 2026.1.29, mettez à jour immédiatement.
En mars 2026, NVIDIA a lancé NemoClaw, un ensemble d’outils open source conçu pour ajouter des garde-fous de sécurité à OpenClaw : environnement d’exécution isolé et routeur de confidentialité. Une initiative qui témoigne de la maturité croissante de l’écosystème et intéresse particulièrement les équipes DSI françaises soucieuses de conformité.
Checklist sécurité minimale avant déploiement
- Mettre à jour OpenClaw vers la version >= 2026.1.29 (ou la dernière stable)
- Lier le Gateway à localhost uniquement (ne pas exposer le port 18789 sur l’internet public)
- Déployer sur un VPS ou une VM dédiée, et non sur votre machine principale de travail
- Vérifier chaque Skill installée depuis ClawHub : étoiles, réputation de l’auteur, contenu du fichier skill.md
- Activer les logs Gateway : tail -f ~/.openclaw/logs/gateway.log
- Appliquer le principe du moindre privilège : limiter les permissions aux strictement nécessaires
- Évaluer NemoClaw (NVIDIA) pour les déploiements en contexte professionnel avec données sensibles
OpenClaw et le RGPD : souveraineté des données
OpenClaw repose sur une architecture local-first (traitement et stockage des données en local) : la mémoire de l’agent, les conversations et les données traitées restent sur votre propre infrastructure. Seules les requêtes envoyées au modèle IA choisi (Claude, GPT-4o, etc.) transitent par des serveurs externes.
Points de vigilance pour une utilisation en conformité RGPD :
- Les appels API vers Anthropic, OpenAI ou Google transmettent des extraits de données à des serveurs hors UE : vérifiez les DPA de chaque fournisseur
- Ollama avec un modèle local élimine ce vecteur de sortie de données
- Les Skills tiers peuvent accéder à vos données : auditez leur code source avant installation
- Pour des usages entreprise impliquant des données clients, consultez votre DPO et référez-vous aux recommandations de la CNIL sur les systèmes d’IA autonomes avant tout déploiement en contexte professionnel
- Infomaniak (hébergeur suisse) offre une conformité RGPD renforcée pour les équipes traitant des données médicales ou financières
Pour les équipes qui traitent des données clients via des outils IA, comprendre ce que la CNIL autorise concrètement en matière de collecte automatisée reste le préalable indispensable.
OpenClaw prix : ce que ça coûte vraiment
À ne pas confondre :
OpenClaw le logiciel et le token CLAW : OpenClaw (logiciel) = gratuit, licence MIT. OPENCLAW (crypto-monnaie) = token spéculatif sans lien avec le logiciel. Le cours CLAW/EUR sur MEXC, Coinbase ou Bitget concerne un actif financier distinct.
| Poste de coût | Estimation mensuelle | Fournisseurs recommandés (FR/EU) |
| Hébergement VPS | 4-20 €/mois | OVH VPS Starter dès 4 €/mois, Scaleway ~4 € (Paris/Amsterdam), Hetzner CX21 ~5 € (Frankfurt), Infomaniak (Suisse, RGPD renforcé) |
| API IA (cloud) | 0-50 €/mois | Claude Sonnet 4.6 | GPT-4o mini | DeepSeek (selon usage) |
| API IA (Ollama local) | 0 € | Modèles locaux : coût infra locale uniquement |
| Abonnement openclaw.ai | ~10-30 €/mois | Option SaaS avec modèles inclus |
| Total usage personnel | 5-15 €/mois | VPS basique + API économique |
| Total équipe (PME) | 25-80 €/mois | VPS renforcé + multi-agents + API premium |
OpenClaw sur Mac Mini : quel modèle choisir en 2026 ?
Depuis mai 2026, Apple a supprimé le Mac Mini 256 Go à 599 $. Le modèle d’entrée de gamme coûte désormais 799 $, mais reste la machine la plus populaire pour faire tourner OpenClaw en local. Pour un usage quotidien avec Ollama, 16 Go de RAM suffisent ; pour des agents multi-tâches ou Claude Opus 4.6, visez 32 Go minimum.
Pour démarrer gratuitement, vous pouvez tester Octoparse sans carte bancaire et l’intégrer à votre workflow OpenClaw via notre guide MCP.
À qui s’adresse OpenClaw, et à qui est-il déconseillé ?
En France, l’essor d’OpenClaw coïncide avec une tendance de fond : les équipes tech cherchent à réduire leur dépendance aux outils SaaS à abonnement mensuel. Un agent auto-hébergé, configuré une fois et opérationnel en continu, répond à cette logique de coût maîtrisé. C’est aussi pourquoi les offres VPS d’entrée de gamme des hébergeurs français (OVH, Scaleway) figurent systématiquement dans les guides d’installation OpenClaw publiés par la communauté.
| Profil | Adapté ? | Pourquoi |
| Développeur, DevOps, tech freelance | Oui | Plein potentiel : CLI, Docker, SSH maîtrisés |
| Équipe data / BI (PME, startup) | Oui (avec encadrement) | Automatisations workflows + extraction légère |
| Chef de projet, ops non-technique | Partiellement | Interface web disponible mais config initiale technique |
| DSI / RSSI entreprise | Avec précautions | Audit sécurité, politique BYOM, DPA nécessaires |
| Marketeur, consultant sans équipe IT | Partiellement | L’orchestration agentique se combine utilement avec un outil de scraping dédié pour les besoins de collecte structurée |
| Grand public non technique | Non recommandé | Risque de misconfiguration, surface d’attaque élevée |
OpenClaw pour la veille automatisée : un cas d’usage avancé
L’un des cas d’usage les plus documentés par les utilisateurs avancés est la veille concurrentielle automatisée. Voici un workflow typique mis en place avec OpenClaw :
- Chaque matin à 7h, l’agent scrape plusieurs dizaines de flux RSS, Reddit, X/Twitter et Google News
- Il déduplique les articles, score leur pertinence selon vos thèmes de veille
- Il envoie un briefing structuré sur votre canal Discord ou Slack
- Pour les contenus nécessitant une extraction structurée (tableaux, prix, fiches produits), il appelle l’API Octoparse pour déclencher un template d’extraction ciblé
- Les données sont exportées en CSV et versées dans votre Google Sheets ou base de données
Ce type de pipeline associe l’orchestration agentique d’OpenClaw à la collecte structurée via l’API Octoparse. Pour les équipes data qui pratiquent déjà le scraping, c’est concrètement la même logique : OpenClaw orchestre, l’API Octoparse exécute, les données arrivent sans intervention.
OpenClaw et le scraping web : ce qu’il fait bien, et où il atteint ses limites

Exporter automatiquement vos données vers Excel, CSV, Google Sheets ou base de données.
Détecter et extraire les données de n’importe quel site web sans écrire une seule ligne de code.
Utiliser 500+ modèles prêts à l’emploi pour scraper Amazon, Google Maps, LinkedIn et plus.
Contourner les blocages anti-scraping grâce aux proxies IP rotatifs et à l’API avancée.
Automatiser vos extractions 24h/24 avec le scraping cloud programmé.
OpenClaw intègre une Browser Automation Skill capable de naviguer et extraire des données de pages web en langage naturel. C’est utile pour des tâches ponctuelles : vérifier un prix, surveiller une page, récupérer un résultat de recherche.
Dès qu’il s’agit d’extraction à l’échelle (plusieurs centaines de pages, données structurées, gestion des CAPTCHAs, pagination JavaScript, export CSV/JSON propre et reproductible), l’approche montre ses limites architecturales. La question n’est donc pas « OpenClaw ou Octoparse ? » mais : comment les faire travailler ensemble ?
| OpenClaw fait bien… | OpenClaw atteint ses limites pour… |
| Extraire le contenu d’une URL et le résumer | Scraper 500+ pages en parallèle avec rotation de proxies |
| Surveiller une page de prix et alerter si changement | Gérer les CAPTCHAs avancés (reCAPTCHA v3, Cloudflare) |
| Scraper un flux RSS et envoyer un digest quotidien | Produire des exports CSV/JSON structurés et reproductibles |
| Remplir des formulaires web simples | Maintenir des sessions authentifiées sur des sites complexes |
| Déclencher une extraction sur commande WhatsApp | Extraction multi-sources coordonnée à grande échelle |
Workflow complet : de la commande WhatsApp à l’export CSV automatique
Plusieurs équipes data francophones ont mis en place ce type d’automatisation pour leur veille concurrentielle. En voici l’ossature :
La documentation Octoparse OpenAPI détaille tous les endpoints disponibles pour ce type d’intégration.
OpenClaw en 2026 : forces, limites et comment l’intégrer dans vos workflows
OpenClaw a atteint 340 000 étoiles GitHub en moins de quatre mois, un rythme sans précédent dans l’histoire des frameworks open source d’IA agentique. Son architecture locale, sa modularité via les Skills, son mécanisme de heartbeat proactif et sa compatibilité avec les messageries du quotidien en font un outil crédible pour quiconque maîtrise les bases d’un déploiement serveur.
Ses limites sont tout aussi réelles : la configuration initiale reste technique, la sécurité demande de la rigueur, et certains besoins dépassent ses capacités natives, notamment l’extraction de données web à grande échelle, la génération de leads B2B ou la veille tarifaire e-commerce. C’est là que des outils conçus spécifiquement pour ces tâches prennent tout leur sens.
En 2026, la question n’est plus de savoir si l’IA mérite une place dans vos outils. C’est de savoir comment articuler orchestration agentique et collecte de données structurées dans vos workflows du quotidien.
OpenClaw orchestre les tâches, mais l’extraction structurée à grande échelle reste hors de sa portée native. Si vous voulez tester le pipeline sur vos données réelles, 14 jours d’accès gratuit permettent de valider l’intégration complète avant tout engagement.
FAQ : OpenClaw, fonctionnement et déploiement
- Qu’est-ce qu’OpenClaw ?
OpenClaw est un agent IA open source qui s’exécute sur votre propre machine et agit à votre place : il envoie des emails, gère votre agenda, navigue sur le web et exécute des tâches en continu, sans intervention humaine. Contrairement à un chatbot, il n’attend pas vos instructions — il agit de façon proactive via un mécanisme de heartbeat.
- À quoi sert OpenClaw concrètement ?
OpenClaw automatise vos tâches répétitives : tri d’emails, briefing matinal depuis des flux RSS, pilotage de votre domotique via WhatsApp, surveillance de pages web, ou déclenchement d’extractions de données. Il fonctionne 24h/24 en tâche de fond, sans que vous ayez besoin d’intervenir.
- Comment fonctionne OpenClaw concrètement ?
OpenClaw s’exécute comme un service Node.js persistant (le Gateway) qui écoute sur votre machine, reçoit les messages de vos applications de messagerie, interroge le modèle IA configuré et exécute les Skills correspondantes. La boucle complète : assemblage du contexte, appel au modèle, exécution des outils, stockage des résultats. Le mécanisme heartbeat lui permet en plus d’agir de façon proactive, sans attendre vos instructions.
- OpenClaw est-il difficile à installer ?
L’installation nécessite Node.js 22 ou supérieur et quelques commandes dans un terminal. Pour un utilisateur à l’aise avec la ligne de commande, compter 20 à 30 minutes pour un déploiement local fonctionnel. Sur un VPS OVH ou Hetzner, prévoir une heure supplémentaire pour la configuration réseau. Une option sans installation technique est disponible via openclaw.ai (à partir de 10 €/mois environ), avec interface web et modèles IA préconfigurés.
- OpenClaw est-il légal en France ?
Oui, OpenClaw est un logiciel open source sous licence MIT, légal en France comme dans l’ensemble de l’Union européenne. Son utilisation implique cependant de respecter le RGPD dès lors que l’agent traite des données personnelles. En contexte professionnel, une analyse d’impact (AIPD) peut être requise. La CNIL n’a pas émis de mise en garde spécifique contre OpenClaw à ce jour.
- OpenClaw est-il compatible avec le RGPD ?
L’architecture local-first d’OpenClaw est un avantage : les données restent sur votre infrastructure. Mais les appels API vers des modèles cloud transmettent des extraits de données hors UE. Pour une utilisation professionnelle, consultez votre DPO et préférez Ollama ou des fournisseurs disposant d’un DPA EU-conforme. Infomaniak est l’option privilégiée pour les équipes traitant des données médicales ou financières sensibles.
- Quelle est la différence entre OpenClaw et Claude Code ?
Claude Code est un assistant de coding intégré à l’IDE, qui s’active sur sollicitation. OpenClaw est un agent proactif, multi-canal, qui fonctionne en continu et peut initier des actions de façon autonome via le heartbeat. Les deux répondent à des besoins différents et peuvent se compléter dans un même pipeline de travail.
- OpenClaw peut-il faire du scraping web ?
Pour des tâches ponctuelles (vérifier un prix, surveiller une page), oui. Pour des besoins de collecte structurée à grande échelle (e-commerce, leads B2B, données tabulaires), un outil dédié est plus adapté. L’intégration via l’API permet de déclencher des extractions directement depuis OpenClaw et de récupérer les résultats dans vos pipelines.
Pour les besoins liés aux réseaux sociaux, consultez nos modèles Twitter Scraper et TikTok Scraper.
- OpenClaw peut-il s’exécuter sur un Mac Mini ou Raspberry Pi ?
Oui, c’est l’un des usages les plus populaires. Un Mac Mini M4 offre une puissance largement suffisante pour OpenClaw 24/7 avec des modèles locaux via Ollama. Le Raspberry Pi 5 est utilisé pour des cas plus légers. OpenClaw nécessite Node.js 22 ou supérieur.
- La faille CVE-2026-25253 est-elle corrigée ?
Oui. La vulnérabilité (CVSS 8.8) a été corrigée dans la version 2026.1.29, référencée sur NVD CVE-2026-25253. Si vous utilisez une version antérieure, mettez à jour immédiatement.
- Comment connecter OpenClaw au protocole MCP ?
OpenClaw supporte les serveurs MCP (Model Context Protocol). La procédure de connexion à un serveur MCP est documentée pas à pas pour les équipes non techniques. Pour l’intégration programmatique avec Octoparse, la documentation API Octoparse détaille les endpoints disponibles.
- Qu’est-ce que NemoClaw (NVIDIA) ?
NemoClaw est un ensemble d’outils open source lancé par NVIDIA en mars 2026, conçu pour ajouter des garde-fous de sécurité à OpenClaw : environnement d’exécution isolé et routeur de confidentialité. Particulièrement pertinent pour les équipes DSI françaises qui souhaitent déployer OpenClaw dans un contexte professionnel avec données sensibles.
- OpenClaw fonctionne-t-il en français ?
Oui. OpenClaw est agnostique en termes de langue : il utilise le modèle IA que vous configurez, et si ce modèle supporte le français (ce qui est le cas de Claude, GPT-4o, Mistral ou Gemini), toutes vos interactions peuvent se faire en français. Mistral 7B via Ollama est particulièrement apprécié des équipes françaises pour sa fluidité en langue natale et son coût nul côté API.
- Comment désinstaller OpenClaw complètement ?
Arrêtez le processus Gateway (Ctrl+C ou pm2 stop openclaw), puis supprimez le répertoire ~/.openclaw/ qui contient toutes vos données locales. Si vous avez utilisé Docker, supprimez le conteneur et le volume associé. Aucune donnée n’est stockée côté serveur tiers, sauf les historiques conservés par les APIs cloud que vous utilisez (Anthropic, OpenAI, etc.).
- OpenClaw est-il vraiment gratuit ?
Oui, OpenClaw est gratuit et open source (licence MIT). Le logiciel lui-même ne coûte rien. Les seuls coûts sont liés au modèle IA que vous choisissez : avec Ollama en local, le coût est zéro. Avec Claude Sonnet 4.6 via API, comptez environ 0,003 à 0,015 € pour 1 000 tokens.
- Quelle est la différence entre OpenClaw et ChatGPT ?
ChatGPT génère du texte dans un onglet de navigateur. OpenClaw agit sur vos systèmes : il envoie des emails, gère votre agenda, scrape des pages web et répond à vos messages WhatsApp pendant que vous dormez. C’est un agent autonome, pas un chatbot.



