Les outils d’exploration Web sont des logiciels informatiques qui utilisent des techniques d’exploration de données pour identifier ou découvrir des modèles à partir d’un grand ensemble de données. Dans notre époque, les données, c’est de l’argent. Mais le problème est que les informations sont énormes, diverses et redondantes parfois. Des outils de minage vous aideront à obtenir les bonnes informations. Dans cet article, je vais vous dresser une liste de quelques outils d’exploration Web populaires sur le Web.
3 genres d’exploration de Web
Exploration de Contenu Web
Le processus de collecte de données utiles à partir d’un site Web. Ce contenu comprend des nouvelles, des critiques, des informations sur l’entreprise, des catalogues de produits, etc.
Exploration de l’Utilisation du Web
Le processus d’identification ou de découverte de modèles à partir de grands ensembles de données. Ces modèles vous permettent de prédire le comportement des utilisateurs ou des choses similaires. Il y a deux types de technologies de modèles : les outils d’analyse de modèles et les outils de découverte de modèles.
Exploration de Structures Web
Aussi appelé comme minage de liens. C’est le processus de découverte de la relation entre des pages Web reliées par des information ou des liens directs.
Top 7 des Outils d’Exploration de Données sur le Web
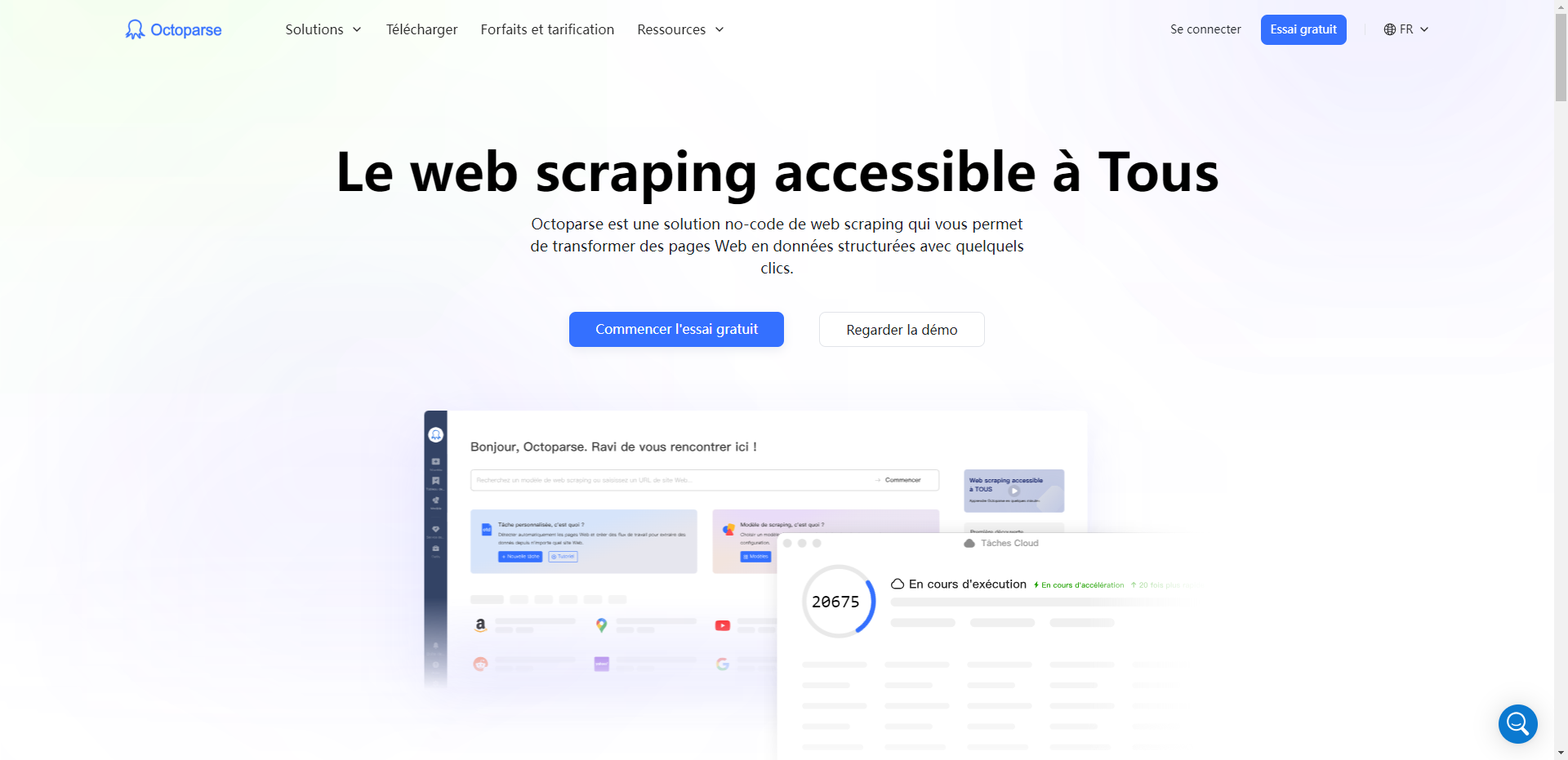
1. Octoparse
Octoparse est un outil d’exploration de données Web simple mais puissant qui a automatisé l’extraction de données Web. Il vous permet de créer des crawlers visiblement. Chaque crawler est un robot qui “indiquera” à Octoparse : vers quel site Web se rendre ; où se trouvent les données que vous prévoyez d’explorer ; quel type de données vous voulez, etc.
Systèmes d’Exploration pris en charge : Windows, MacOS
Domaine d’Exploration de Web : l’exploration de Contenu Web
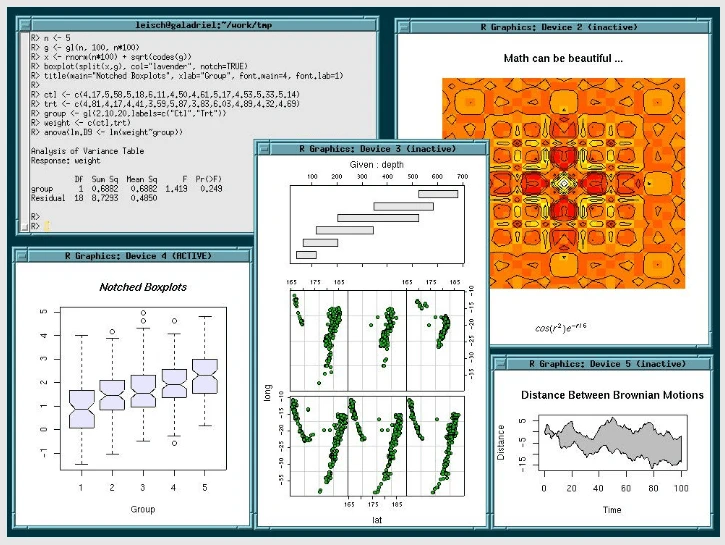
2. R
R est un langage ou un environnement GRATUIT pour les calculs statistiques et les graphiques. Il est accessible à partir de langages de script tels que Python, Ruby, Perl, etc.
Systèmes d’Exploration pris en charge: platforms UNIX, Windows, MacOS
Domaine d’Exploration de Web: Exploration de l’Utilisation du Web
3. Oracle Data Mining (ODM)
Oracle Data Mining est un logiciel d’exploration de données fourni par Oracle. Oracle Data Mining est implémenté dans le noyau d’Oracle Database, dont les modèles d’exploration de données est sont les objets de base de données de première classe. Le processus d’exploration de données dans Oracle utilise les fonctionnalités intégrées de la base de données Oracle pour maximiser l’évolutivité et utiliser efficacement les ressources de système.
Systèmes d’Exploration pris en charge : Microsoft Windows
Domaine d’Exploration de Web : l’Exploration de l’Utilisation du Web
4. Tableau
Tableau propose une série de produits de visualisation de données interactifs axés sur la Business Intelligence. Tableau permet un aperçu instantané en rendant les données interactives visuellement attrayantes (appelées tableaux de bord). Ce processus ne prend que quelques secondes ou minutes au lieu de des mois ou des années et est réalisé avec une interface glisser-déposer conviviale.
Systèmes d’Exploration pris en charge : Mac, Microsoft Windows
Domaine d’Exploration de Web : l’Exploration de l’Utilisation du Web
5. Scrapy
Scrapy est un framework de source ouverte pour la collecte de données à partir de sites Web. Il est écrit en Python et vous pouvez y configurer des règles pour extraire des données Web.
Systèmes d’Exploration pris en charge: Linux, Windows, Mac et BSD
Domaine d’Exploration de Web: l’Exploration de Contenu Web
6. HITS algorithm
HITS, abréviation de Hyperlink-Induced Topic Search, également connu sous le nom de hubs et d’autorités, est un algorithme d’analyse de liens qui évalue les pages Web.
Lors de l’utilisation de l’algorithme HITS, la première étape est de récupérer les pages les plus pertinentes avec la requête de recherche. Cette action est appelée la racine et peut être obtenue par prendre les premières pages renvoyées par un algorithme de recherche basé sur du texte. L’ensemble de base est généré par développer la racine avec toutes les pages Web qui y sont liées. Les pages Web de l’ensemble de base et tous les hyperliens entre ces pages forment un sous-graphe ciblé.
Domaine d’Exploration de Web: Exploration de Structures Web

7. PageRank Algorithm
L’Algorithme PageRank est un Algorithme Populaire d’Exploitation de Structure Web.
PageRank est un algorithme d’analyse de liens qui attribue les coefficients de pondération numérique à chaque élément de l’ensemble de documents hyperliés, tels que le World Wide Web, dans le but de “mesurer” son importance relative au sein de l’ensemble. L’algorithme peut être appliqué à toute collection d’entités avec des citations et des références réciproques.
Domaine d’Exploration de Web: Exploration de Structures Web