En parlant de créer un blog rapidement, on pense à profiter du blog scraping pour alimenter la curation de contenu. Pour dire les choses simplement, c’est l’acte de scraper une grande quantité d’articles de blog sur Internet, d’en sélectionner les meilleurs et de les présenter d’une manière significative et organisée.
Un blog nouvellement créé peut se développer très rapidement avec la bonne stratégie. L’une des meilleures façons est la création de votre propre base de source matérielle du blog, ce qui demande des recherches analytiques en parcourant plusieurs articles un par un. Cependant, il n’est pas facile de trouver du contenu de haute qualité pour votre blog s’il n’y a pas d’assistance comme un outil efficace de recueillir les ressources collectées.
Voici une meilleure méthode que je veux partager avec vous.
En deux étapes, vous trouverez le contenu le plus approprié pour votre blog avec Octoparse.
Identifier les sites Web liés à votre blog
Chaque site web est généralement axé sur un sujet ou un domaine spécifique. Si vous parvenez à bien préciser le thème principal de votre propre blog, cela deviendra pour vous plus aisé d’identifier les sources d’informations pertinentes. Votre recherche peut débuter par un repérage des sites web spécialisés, performants et influents sur le sujet, sources d’information professionnelles par exemple, qui drainent du trafic et de l’engagement. Il est conseillé de les lister, de les faire figurer dans vos favoris, en prenant le soin d’inclure leurs URL, d’indiquer leur orientation thématique, leur niveau d’autorité, etc., en vue de construire cet ensemble clé pour votre curation de contenu qui va faciliter la collecte sur le marché des articles de qualité et le suivi de l’actualité dans votre secteur.
Extraire les contenus du blog avec Octoparse
Allez-y ! Allez trouver les articles intéressants traitant de votre sujet pour votre blog. Pour un nouveau blog, le contenu populaire – est plus important que le contenu pertinent – reste encore la priorité. En conséquence, vous devez vous préoccuper préférentiellement des articles populaires, ce qui, lorsque vous réalisez l’extraction des données avec Octoparse, suppose de connaître le nombre de vues de l’article, son classement, etc. Certes, l’URL, la description, le titre, la catégorie, l’intégralité des articles des posts craping sont les éléments clés.
Par exemple, si je voulais cibler le growthhacking digital, une des sources appropriées est BDM (blogdumoderateur), qui donne un panorama des métiers du marketing et de la tech.
Voici les étapes détaillées que j’ai extraites des informations issues des articles de la catégorie « Marketing » du site BDM avec Octoparse, dans le but d’enrichir ma démarche de curation de contenu.
Préparations : télécharger Octoparse et l’installer, décider de l’URL cible :
https://www.blogdumoderateur.com/marketing/
Étape 1 : entrer l’URL dans Octoparse et puis cliquer sur “Démarrer”
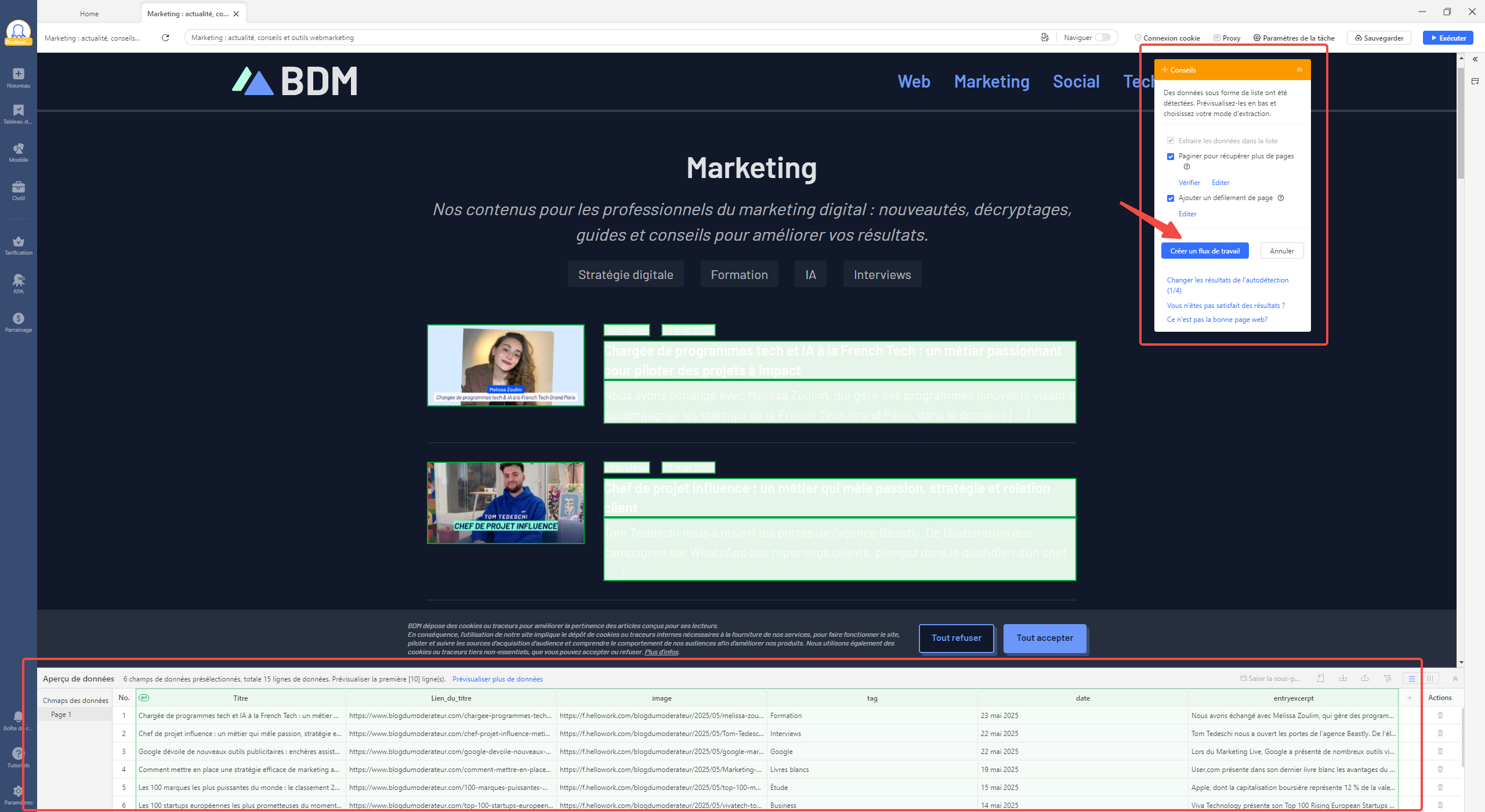
Étape 2 : lancer l’auto-détection
Il suffit, tout d’abord, d’activer la fonction « Auto-détection » depuis le panneau de conseils. Une fois cette étape terminée, il est essentiel de vérifier les données extraites dans la section « Aperçu de données ». Dans le cas présent, j’ai choisi de supprimer le champ nommé « entryexcerpt », car les descriptions qui y figurent sont incomplètes. Ces dernières peuvent être récupérées directement depuis les pages des articles. Dès que les ajustements sont effectués, il convient de cliquer sur « Créer un flux de travail » afin qu’Octoparse génère automatiquement le schéma d’extraction. À ce stade, la pagination ainsi que la boucle de collecte sont mises en place avec succès.
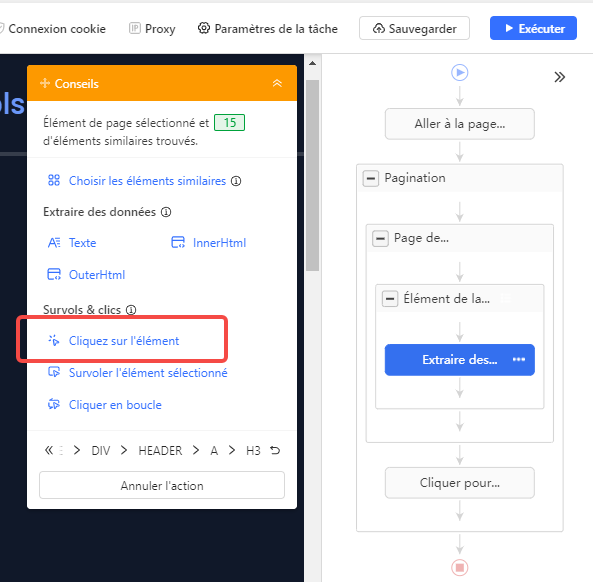
Étape 3 : choisir les données à extraire
Il arrive que certaines informations soient accessibles uniquement à partir de sous-pages. Dans ce cas-là, vous pouvez ajouter l’action en cliquant sur les éléments sur l’écran et puis en choisissant. Cliquez sur l’élément pour régler votre propre workflow. Je vais extraire la description, l’auteur, le temps de publication, le sponsor, etc. Si nécessaire, vous pouvez modifier les noms des champs dans l’aperçu de données en temps réel.
Étape 4 : Exporter les données désirées
L’extraction de données peut être exécutée sur l’ordinateur local ou sur le Cloud, plus rapide, plus pratique (qui est un service exclusif aux utilisateurs premium, pour demander un essai gratuit de 14 jours).
Les données peuvent être exportées vers Excel, CSV ou d’autres systèmes via API.
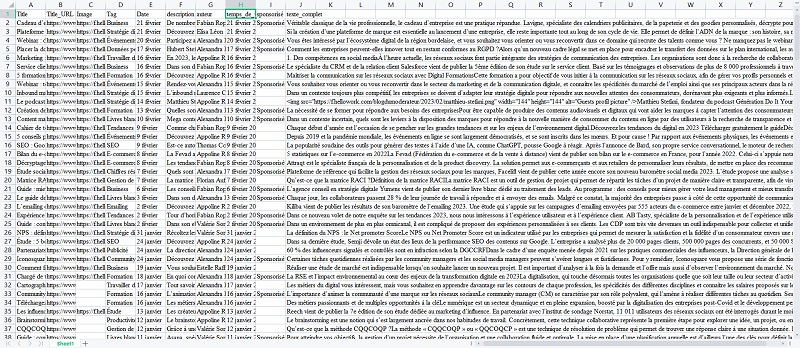
Voilà les données que j’ai récupérées. Elles contiennent le titre, l’URL du blog, l’URL de l’image de couverture, le tag, la date de la publication, la description, l’auteur, le temps de publication, le sponsor, le texte complet des articles. Les informations ainsi collectées peuvent donner des idées pour la sélection de nouveaux sujets de votre blog.
Les modèles prédéfinis pour vous
De plus, nous fournissons plus de 500 modèles prédéfinis dans le monde par rapport notamment aux secteurs tels que l’e-commerce, les médias sociaux, l’immobilier… Et pour certains des modèles qui exigent la facturation par ligne, vous êtes en mesure d’estimer le volume de données nécessaires et de les payer en fonction de vos besoins pendant le web scraping. C’est-à-dire une méthode plus flexible pour s’adapter à la quantité de données collectées. Si vous êtes plus intéressé par la collecte de données de contenu, cliquez sur le lien de Smart Article Scraper ci-dessous pour trouver le modèle suggestif :
https://www.octoparse.fr/template/smart-article-scraper
Blogs recommandés populaires en France
On vous propose les sites de quelques blogs français populaires et pertinents pour la curation de contenu en marketing, tech, entrepreneuriat, etc. Cela vous aidera à bien planifier votre crawler du blog adapté à vos besoins :
- Blogdumoderateur
- FrenchWeb
- Made in Marseille
- WebRankInfo
- Les Echos Start
- Digitiz France
- Le Journal du Net
- WebMarketing Conseil
Conclusion
Avec Octoparse, le web scraping de blog est simple et je suis sûr que ça vous aidera dans vos activités de curation de contenu. Si cela vous intéresse, n’hésitez pas à télécharger Octoparse et à suivre les étapes pour obtenir les données dont vous avez besoin.

Transformer les sites web vers Excel, CSV, Google Sheets ou base de données.
Auto-détecter les sites Web et extraire les données sans aucun codage.
Scraper les sites populaires en quelques clics avec les modèles pré-construits.
Ne se trouver jamais bloqué grâce aux proxies IP et à l’API avancée.
Service Cloud pour programmer le scraping de données.
Bien sûr, il ne s’agit pas de la dernière des actions que vous devrez mener pour arriver à écrire un blog qui, malgré les efforts que vous devez déployer, est à mettre à jour régulièrement avec une meilleure qualité de vos articles. En l’occurrence, cet article ne présente qu’une de ces méthodes commune à d’autres pour écrire un blog.
Bonus : voilà une vidéo en anglais sur le scraping de données d’actualités depuis Reuters.com. J’espère que cela vous est utile.



