Si vous débutez dans le web scraping, maîtriser le crawling de listes est une étape incontournable.
Le crawling de listes est la tâche d’extraction de données web la plus courante, plus de 70 % des opérations d’extraction concernent des listes. La tarification, la veille concurrentielle, la création de leads – toutes suivent des modèles répétitifs qui peuvent être traités de façon systématique.
La façon la plus rapide de réussir consiste à repérer les sites les plus adaptés au crawling de listes, d’appliquer un ensemble de règles d’extraction uniformes à chaque élément, et de concevoir dès le départ en tenant compte de la pagination, des limites de fréquence et des protections anti-bots. Ce guide vous montre exactement comment faire.
Crawling de liste vs Crawling général du web
Le crawling de listes est ciblé et structuré. Au lieu de visiter chaque page, vous vous concentrez sur un ensemble précis de pages partageant le même modèle – par exemple, une catégorie de produits, un site d’offres d’emploi ou une liste d’avis – et vous extrayez les mêmes champs de chaque item (titre, prix, description, etc.).
Le crawling web général, en revanche, consiste à visiter le plus grand nombre possible de pages et à indexer leur contenu – comme le fait Google en explorant internet pour constituer ses résultats de recherche. Il est large, superficiel et conçu pour découvrir de nouvelles pages.
Pour faire simple :
Crawling général = « Trouve-moi tout »
Crawling de liste = « Récupère exactement ce type de données sur chaque élément de cette liste »
Le crawling de liste implique souvent de gérer la pagination, le défilement infini et les motifs répétitifs, tandis que le crawling général suit simplement des liens sans se soucier de la structure des données.
Quels types de sites web conviennent le mieux au crawling de liste ?
Après avoir exploré des milliers de sites, j’ai constaté que certaines caractéristiques prédisent systématiquement le succès. Je vous invite également à télécharger Octoparse pour découvrir le Top 12 des sites web les plus scrappés en 2025, ainsi que des modèles exclusifs.
Où apparaissent le plus souvent les listes ?
| Catégorie | Exemples | En quoi cela est important |
| Médias sociaux | Profils Instagram, annuaires d’employés LinkedIn, hashtags Twitter | Recherche de concurrents, marketing d’influence, cartographie des talents |
| E-commerce | Variations de produits Amazon, annonces terminées eBay | Intelligence tarifaire, étude de marché |
| Données professionnelles | Tours de financement AngelList, dépôts GitHub | Recherche d’investissements, recrutement |
| Local / Cartes | Fiches Google My Business | Audits SEO locaux, veille concurrentielle |
1 Sites de commerce électronique et catalogues de produits
Quand je visite des sites tels que des pages produits de fabricants ou des annonces sur les marketplaces,
je recherche :
- Des champs de données cohérents d’un article à l’autre.
- Le prix, le titre, la description et les images qui apparaissent toujours aux mêmes endroits avec peu de variations.
- Des motifs de pagination clairs et des structures d’URL prévisibles pour faciliter une extraction systématique.
- Les pages produits d’Amazon sont la référence absolue en matière de crawling de listes.
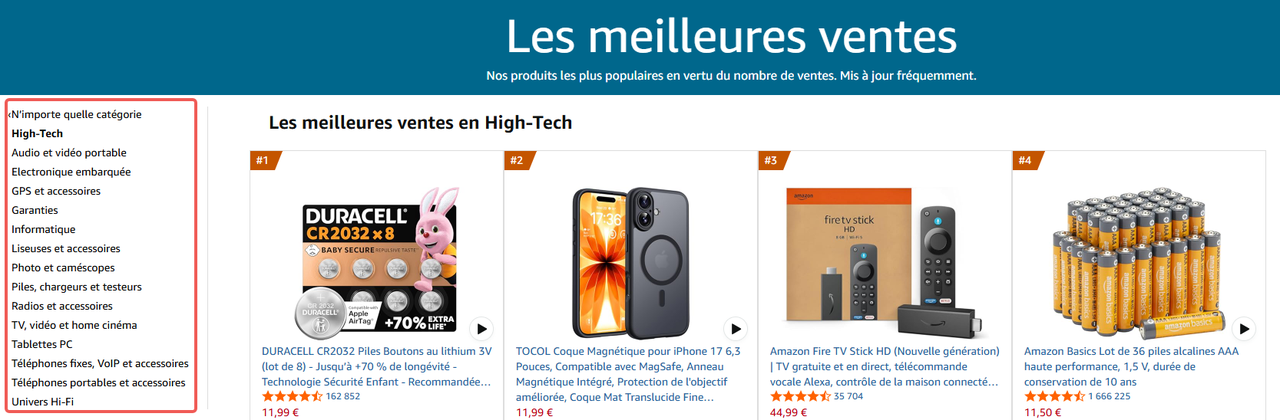
Chaque fiche produit suit le même modèle, la pagination fonctionne de manière prévisible, et la structure des données reste cohérente même lorsque le design change.
👉 Essayez ce modèle pour extraire les meilleures ventes sur Amazon en quelques clics dès maintenant :
https://www.octoparse.fr/template/amazon-best-sellers-scraper
2 Annuaires d’entreprises et listes de services
Des sites comme Pages Jaunes ou des annuaires spécialisés présentent les informations des entreprises dans des formats standardisés. Les coordonnées, horaires d’ouverture et données d’avis suivent des structures uniformes, que vous consultiez par localisation ou par catégorie. Ce type d’annuaires, notamment ceux mentionnés dans le Guide des annuaires français pour le référencement professionnel, permettent une extraction facile et efficace des données structurées.
Lorsque j’analyse ces sites d’annuaires, je vérifie que les fiches d’entreprises comportent les mêmes champs d’information et que l’organisation reste logique.
À part cela, le filtrage par géolocalisation et la navigation par catégorie doivent fonctionner de manière prévisible sur l’ensemble du site.
3 Sites d’offres d’emploi et plateformes de carrière
Les sites d’offres d’emploi utilisent des formats standardisés qui garantissent une extraction fiable. Les informations sur les salaires, les données de localisation, les détails des entreprises et les dates de publication apparaissent de manière cohérente dans toutes les annonces.
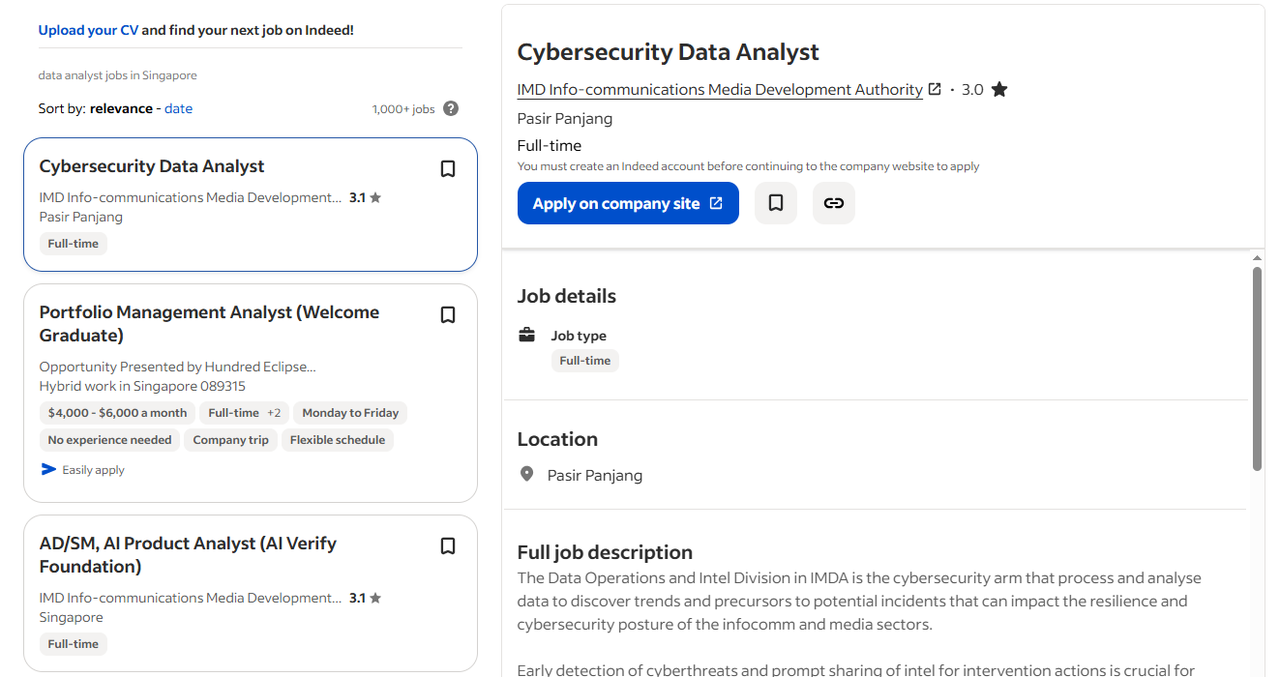
J’ai obtenu d’excellents résultats en crawlant des sites comme Indeed ou les pages carrières des entreprises, car ils reposent sur la nécessité pour les utilisateurs de comparer rapidement des postes similaires. Cette exigence commerciale impose une présentation de données cohérente, ce qui en fait des cibles idéales pour le crawling.
👉 Cliquez sur le modèle ci-dessous pour collecter les informations ciblées sur Indeed :
https://www.octoparse.fr/template/indeed-job-scraper-by-url
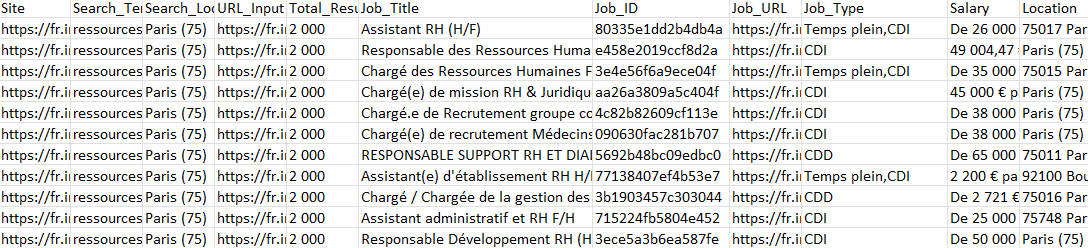
Ce tableau représente une partie des données que j’ai collectées avec ce modèle, et Octoparse permet de répondre à vos besoins de collecte massive de données sur n’importe quel site.
4 Plateformes d’avis et de contenu
Les sites d’avis présentent les retours des utilisateurs selon des structures uniformes, avec des systèmes de notation cohérents et une organisation par ordre chronologique.
Les agrégateurs d’actualités comme Le Figaro et les plateformes de contenu utilisent des aperçus d’articles standardisés accompagnés de métadonnées de publication.
Le point commun entre les sites cibles performants : ils présentent des informations similaires avec une mise en page identique. Lorsqu’on retrouve les mêmes champs de données reproduits avec peu de variations, cela signifie que vous avez trouvé un site idéal pour le crawling de listes.
👉 Je vous recommande vivement le modèle GRATUIT Trustpilot Avis Scraper d’Octoparse, n’hésitez pas à l’essayer dès maintenant :
https://www.octoparse.fr/template/trustpilot-reviews-scraper
Comment reconnaître un site propice au crawling?
Avant de déterminer si je peux ou non effectuer un crawling de liste sur un site, je réalise une évaluation rapide en 5 minutes. Cette étape m’aide à décider si le site sera coopératif ou s’il résistera à mes tentatives d’extraction.
Examiner le contenu du code source de la page
Pour accéder au contenu du code source de la page, il suffit de faire un clic droit sur n’importe quel élément de la liste et de sélectionner « Inspecter ».
Ensuite, recherchez les éléments HTML contenant vos données cibles, des noms de classes cohérents pour des éléments similaires, ainsi qu’un balisage structuré comme JSON-LD.
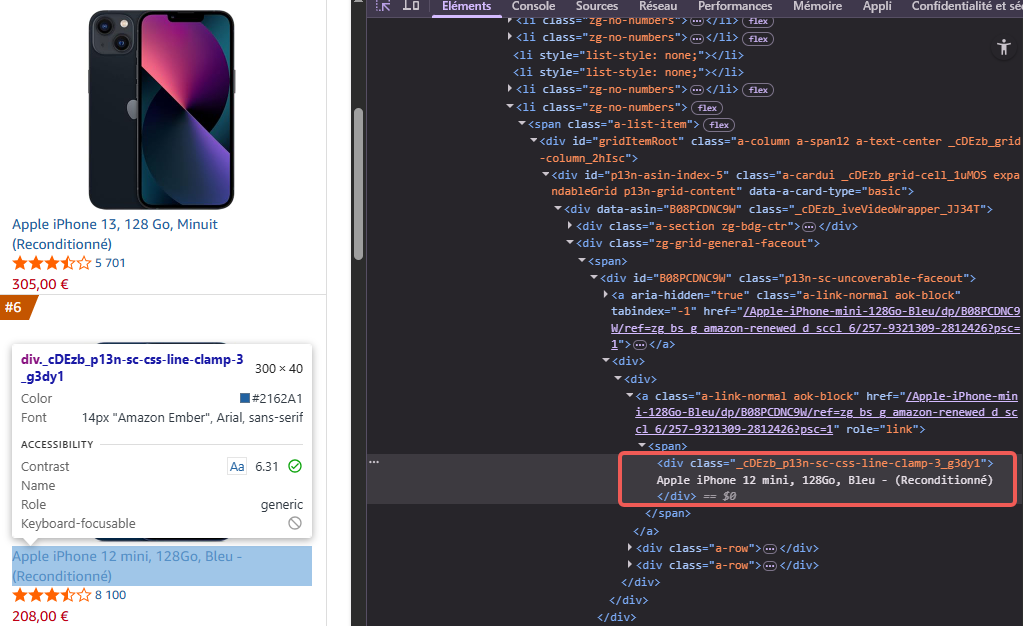
Si vous pouvez voir clairement vos données cibles dans le code source HTML, le site est exploitable par crawling.
Note : les divs vides ou le texte de substitution qui se remplissent via JavaScript indiquent un contenu dynamique nécessitant des techniques plus avancées.
Vérifier les schémas de structure des URL
Les listes exploitables en crawling utilisent des schémas d’URL prévisibles pour la navigation.
Je recommande de repérer ces schémas dans la pagination, par exemple :
- example.com/produits?page=1 qui progresse logiquement vers page=2, ou
- des structures basées sur la catégorie comme example.com/electronique/p2
Les signaux d’alarme sont les URL qui ne changent pas ou comportent des tokens complexes générés par JavaScript.
Une fois, j’ai passé plusieurs jours sur un site où toutes les pages avaient la même URL mais contenait un contenu différent chargé via JavaScript, la pagination étant complètement dynamique.
Tester le comportement de navigation
Ce que je ferais, c’est naviguer manuellement en cliquant sur trois ou quatre pages.
Les numéros de page doivent fonctionner de manière cohérente, le bouton de retour du navigateur doit fonctionner correctement, et les éléments de la liste doivent se charger immédiatement, sans délai.
Lorsque vous rencontrez une pagination défectueuse, une navigation incohérente ou des séquences de chargement complexes, il peut être nécessaire d’ajuster la configuration de votre crawler, par exemple en écrivant un XPath spécifique pour la pagination.
Contrôler la gestion de la limitation du débit
Ouvrez rapidement cinq ou six pages dans de nouveaux onglets du navigateur.
Si certaines pages ne se chargent pas, affichent des défis CAPTCHA ou indiquent « trop de requêtes », cela signifie que votre crawling automatisé est peut-être trop agressif.
Différents types de sites pour le crawling de listes
Lorsque je souhaite éviter de coder et de déboguer, je privilégie Octoparse pour le crawling de listes, car il gère la complexité technique tout en me permettant de me concentrer sur l’obtention des données dont j’ai besoin.

Transformer les sites web vers Excel, CSV, Google Sheets ou base de données.
Auto-détecter les sites Web et extraire les données sans aucun codage.
Scraper les sites populaires en quelques clics avec les modèles pré-construits.
Ne se trouver jamais bloqué grâce aux proxies IP et à l’API avancée.
Service Cloud pour programmer le scraping de données.
Vous pouvez le télécharger GRATUITEMENT, il fonctionne sous Windows (version Mac également disponible).
Les structures de données des listes varient d’un site à l’autre, donc j’adapte toujours ma méthode en fonction du type de liste avec laquelle je travaille.
Voici comment je gère les trois structures de liste les plus courantes :
1 Comment crawler des listes sous forme de tableaux
Après avoir vérifié que les données cibles se présentent sous forme de liste de tableaux, la première chose que je fais est d’ouvrir Octoparse. Et puis je colle l’URL de la liste que je souhaite crawler.
Le logiciel charge la page dans son navigateur intégré, ce qui me permet de voir exactement ce avec quoi je travaille.
Dans ce cas, je suis en train de crawler BOURSIER.COM, qui est une page typique de liste sous forme de tableau.
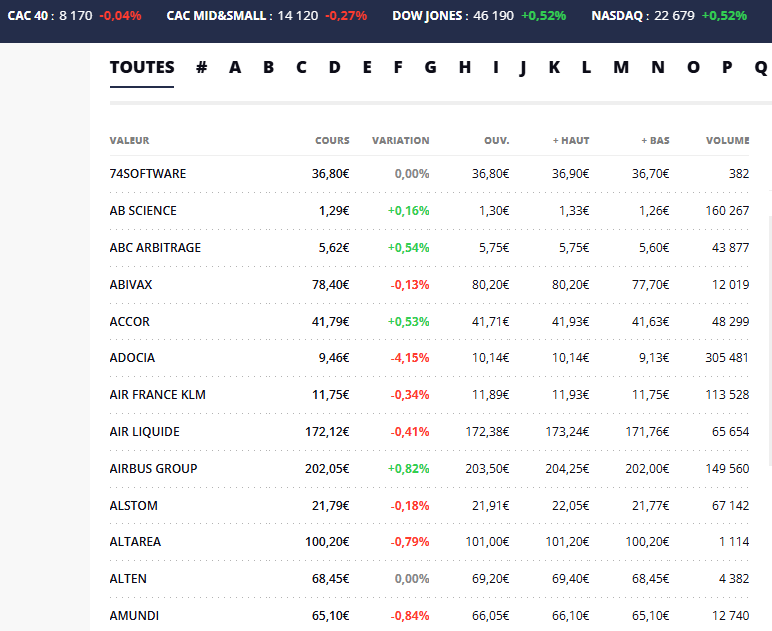
Ensuite, j’utilise la fonction « Autodétection des données de la page web », qui scanne rapidement la page et met en évidence les éléments du tableau, en sélectionnant automatiquement les lignes et les colonnes.
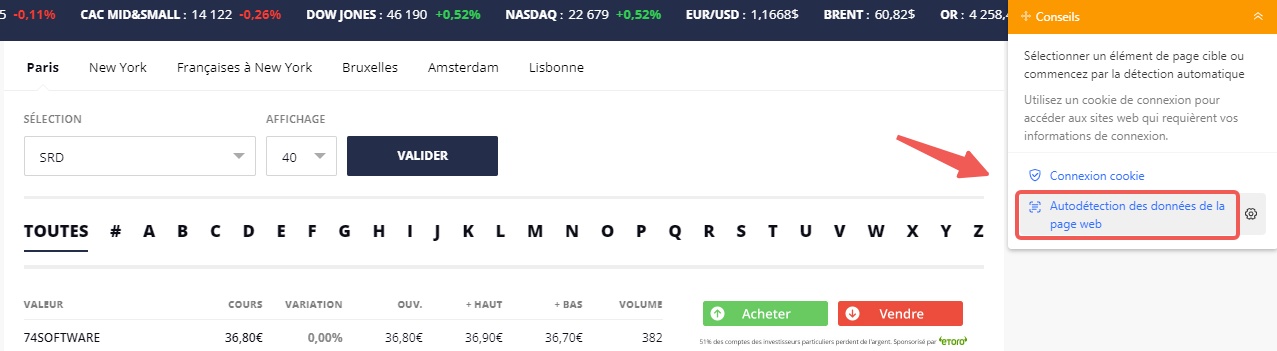
Si la détection automatique oublie quelque chose, je sélectionne manuellement la première cellule de la première ligne, puis j’étends la sélection jusqu’à ce que toute la ligne soit en vert.
Ensuite, Octoparse trouve pour moi les autres lignes ayant une structure similaire.
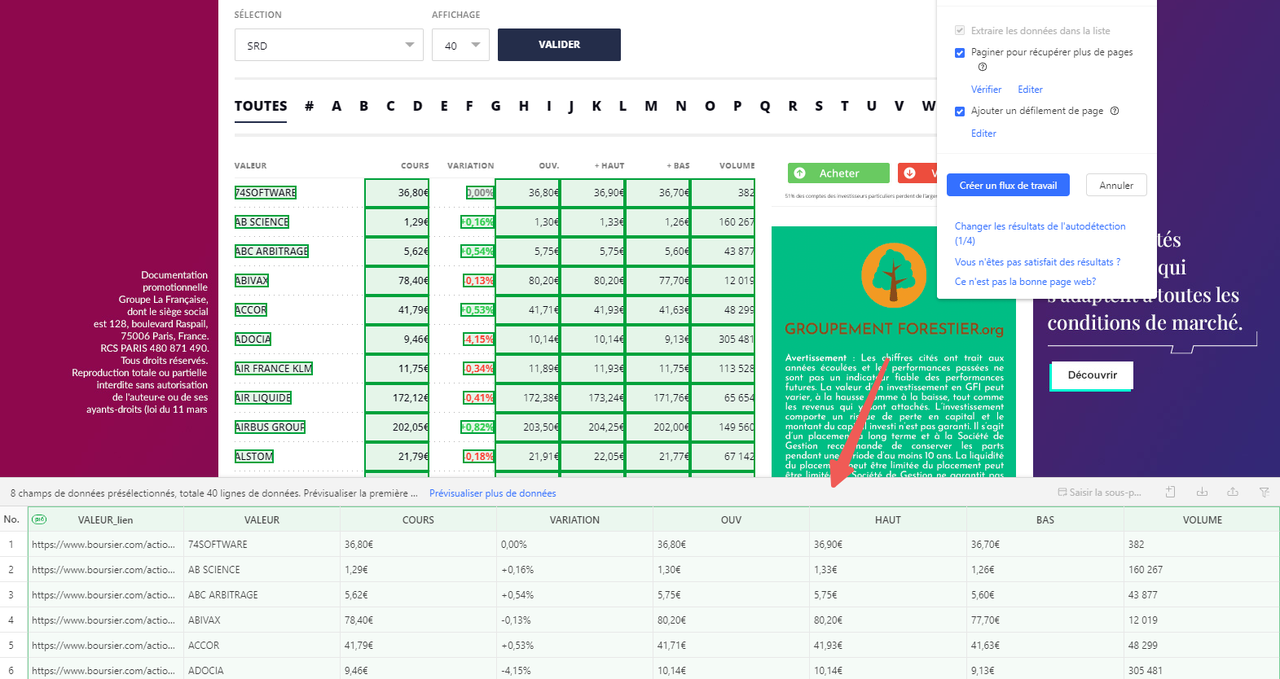
Je vérifie que toutes les colonnes dont j’ai besoin sont bien présentes, je renomme les en-têtes pour plus de clarté et supprime les champs inutilisés.
Si le tableau s’étend sur plusieurs pages, je configure la pagination en indiquant à Octoparse comment cliquer sur “Bouton page suivante” pour scraper les pages suivantes.
Alors je réalise une extraction test pour m’assurer que toutes les lignes et toutes les cellules sont correctement capturées, avant de lancer le crawling complet et d’exporter les données au format Excel ou Google Sheets.
2 Crawler les données à l’intérieur d’onglets ou d’interfaces à onglets
Parfois, les sites web utilisent des onglets pour organiser des listes de données sur une seule page – comme les variantes de produits, les spécifications ou les avis des utilisateurs dans des panneaux séparés.
Je charge la page contenant ces onglets et configure des actions pour cliquer successivement sur chaque onglet, afin de rendre leur contenu visible pour l’extraction. Ensuite, j’utilise la fonction de détection automatique ou une sélection manuelle pour capturer les données situées dans chaque onglet.
Si la page comporte plusieurs onglets ou des listes imbriquées, je configure une boucle pour que Octoparse visite et extraille dynamiquement toutes les sections tabulaires.
Une astuce essentielle consiste à ajouter des temps d’attente appropriés dans le flux de travail lors du changement d’onglet, pour laisser le temps au contenu de la page de se charger complètement, surtout si ces onglets chargent leurs données via JavaScript ou AJAX.
3 Explorer les structures de pages de listings et de pages de détails
Pour les sites web qui affichent des listes de produits ou d’articles avec des liens vers des pages de détails, le processus de crawling se divise généralement en deux étapes principales :
Tout d’abord, extraire l’aperçu depuis la page de listing, puis cliquer sur chaque lien pour accéder à la page de détails et recueillir des informations complémentaires.
Je commence par entrer l’URL de la page de listing dans Octoparse et je lance la fonction de détection automatique pour repérer tous les éléments présents sur la page. Cela crée une boucle qui extrait des données communes comme le titre du produit, le prix ou un résumé.
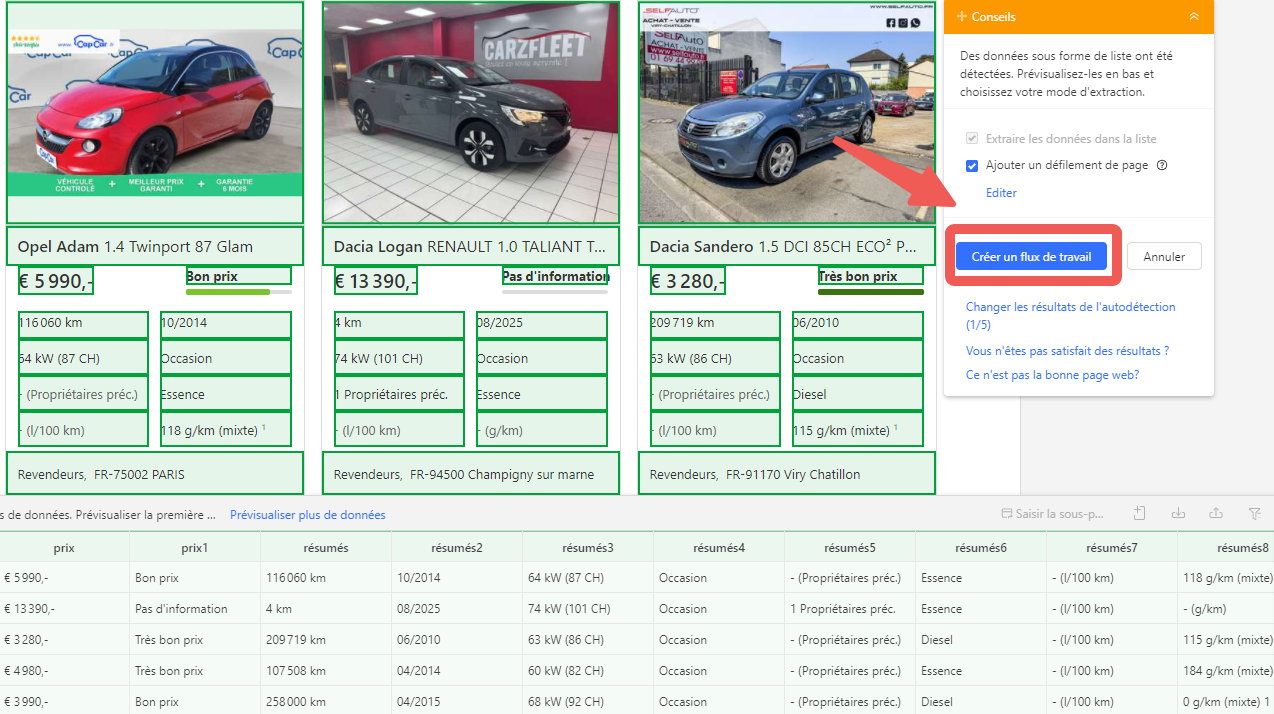
Et puis, je configure le flux de travail d’Octoparse pour cliquer automatiquement sur chaque image survoiture d’occasion et cliquer sur “Choisir les éléments similaires” vers la page de détails pour finir la créatoin d’une boucle, où je paramètre l’extraction d’informations plus précises – comme la description complète, les spécifications ou les avis. Ce cas est également courant lors de télécharger les images d’un site web.
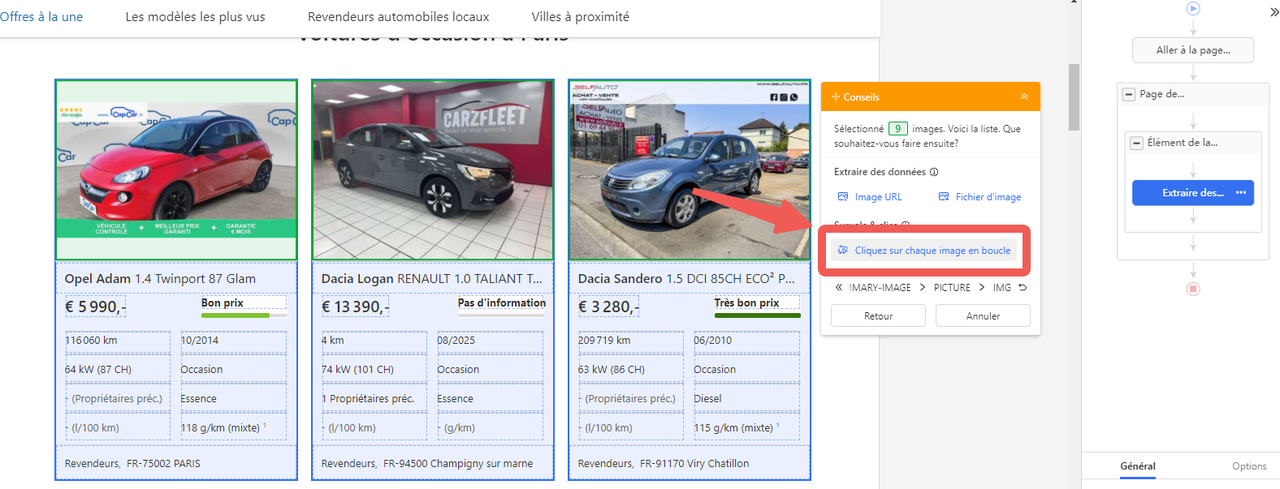
Je mets également en place la pagination pour qu’Octoparse puisse charger et collecter des données sur plusieurs pages de listing.
Après avoir vérifié que tout fonctionne parfaitement lors d’un test, je lance le crawling en entier. Cette méthode me permet de constituer rapidement des jeux de données riches, combinant résumés et détails approfondis, ce qui est considéré comme une étape supplémentaire dans le flux de travail d’extraction de données.
📌 Pourquoi j’aime cette approche hiérarchique
Diviser le processus selon le type de liste le rend simple à comprendre pour les débutants, tout en offrant aux lecteurs plus techniques la possibilité d’approfondir si ils le souhaitent.
De plus, l’interface visuelle, intuitive et basée sur le clic de Octoparse rend même les crawls de listes complexes accessibles à tous.
Si vous souhaitez en savoir davantage sur l’une de ces techniques, j’ai ajouté des liens vers des tutoriels détaillés qui vous guident étape par étape.
Problèmes courants lors du crawling de listes et comment les résoudre
1 Absence de données ou données partielles
Cela signifie généralement que la page n’a pas été complètement chargée ou que la sélection a manqué certains éléments. Pour résoudre ce problème :
Augmentez le délai d’attente avant action pour l’étape « Aller à la page web » afin de laisser plus de temps au chargement.
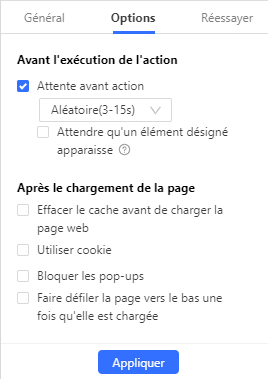
Parfois, ajouter une étape de défilement permet de charger toute la liste avant l’extraction.
Je prends aussi soin de prévoir de courtes pauses entre les étapes, surtout lorsque le contenu est dynamique.
2 La pagination saute des pages ou manque des données
Une pagination mal configurée entraîne souvent une perte d’informations. Je :
Vérifie que le XPath du bouton « Page suivante » est précis et stable.
Teste la pagination manuellement dans Octoparse pour m’assurer qu’elle passe bien d’une page à l’autre de façon séquentielle.
Parfois, étendre le délai d’attente pour le chargement AJAX aide à charger complètement chaque page avant de passer à la suivante.
3 Doublons dans les données exportées
Les doublons proviennent souvent d’erreurs de pagination, comme Octoparse qui clique deux fois sur la même page ou boucle incorrectement.
Mes solutions :
Raffiner le XPath de pagination ou changer de mode de boucle.
Utiliser la suppression automatique des doublons proposée par Octoparse lors des exécutions en cloud.
Ajouter une logique pour détecter et sauter les pages en double si nécessaire.
Bien sûr, vous pouvez également consuler le tutoriel pour suivre étape par étape et en apprendre davantage.
4 La tâche se bloque ou se fige en cours d’exécution
Les sites dynamiques ou très JavaScript peuvent provoquer des blocages.
Il faut :
Vérifier les journaux d’événements et d’erreurs pour repérer le problème.
Augmenter les délais d’attente, ajouter des défilements ou insérer des pauses manuelles.
Envisager de diviser les crawls importants en plusieurs petites parties.
5 CAPTCHA ou blocages rencontrés
Les CAPTCHAs peuvent complètement arrêter le crawling.
Je gère cela en :
Utilisant la étape de résolution CAPTCHA d’Octoparse pour les types courants comme ReCAPTCHA.
Mettre en place une rotation de proxies et varier les entêtes de requête pour donner une apparence moins automatisée.
Ralentir la vitesse du crawl et ajouter des délais aléatoires entre chaque requête.
💡 En savoir plus
Gain de temps avec Octoparse pour accélérer votre processus de web scraping
Comment je nettoie et prépare mes données extraites
Après avoir extrait une liste de données, il est courant de rencontrer certains problèmes qui peuvent compliquer votre analyse par la suite.
Par exemple, vous pourriez constater :
- Des lignes en double montrant le même élément plusieurs fois.
- Des informations manquantes dans certains enregistrements.
- Des dates, prix ou catégories écrits de multiples façons différentes.
- Des balises HTML aléatoires ou des symboles étranges dans les champs de texte.
Voici ce que je fais pour garantir que mes données affinées soient dans un bon état :
- Supprimer les lignes en double Les doublons peuvent troubler l’analyse et faire compter deux fois les mêmes éléments. J’utilise des outils comme la fonction « Supprimer les doublons » dans Excel ou, en Python, la méthode df.drop_duplicates() dans Pandas pour les éliminer.
- Combler ou supprimer les données manquantes Si des prix ou des dates manquent, j’essaie de faire des moyennes ou d’utiliser des entrées similaires pour remplir les lacunes. Si trop de données manquent, je supprime ces lignes.
- Uniformiser les formats Je m’assure que toutes les dates suivent le même format et que les prix utilisent le même style monétaire. Par exemple, que “$19.99” et “19,99 USD” deviennent tous deux “19.99”.
- Nettoyer les champs de texte Parfois, les descriptions contiennent du code web résiduel ou des symboles bizarres. Je supprime les balises HTML et les espaces superflus pour garder les descriptions propres.
Outils que j’utilise pour le nettoyage des données
- Excel ou Google Sheets :
Idéal pour de petites quantités de données ou des corrections rapides de données désordonnées.
- Python avec la bibliothèque Pandas :
Parfait pour de plus grandes quantités de données ou pour des opérations de nettoyage plus avancées, comme supprimer les doublons, remplir les valeurs manquantes et formater les colonnes.
Un outil sans codage qui permet de nettoyer des données désordonnées en regroupant des entrées similaires et en corrigeant les incohérences.
Voici un exemple simple en Python pour supprimer les doublons et remplir les prix manquants :
Une bonne étape de nettoyage des données me fait gagner du temps par la suite, améliore la précision de mes analyses et me permet de faire confiance aux insights issus de mes listes extraites.
Questions fréquentes sur le crawling de listes
- Comment gérer le contenu de listes chargé dynamiquement, comme le défilement infini ou le contenu dans des onglets ?
De nombreux sites modernes utilisent JavaScript pour charger dynamiquement les éléments de liste lorsque vous faites défiler la page ou cliquez sur des onglets.
Pour cela, utilisez des outils capables d’exécuter du JavaScript, comme le navigateur intégré d’Octoparse ou Selenium. Il peut être nécessaire de simuler des actions de défilement ou de clic sur les onglets, et d’ajouter des temps d’attente afin de laisser le contenu se charger avant l’extraction.
- Comment éviter que mon crawler soit bloqué lorsqu’il scrape des listes dynamiques ?
Utilisez la rotation d’IP via des proxies, ralentissez la vitesse des requêtes avec des délais aléatoires, changez d’user-agent et respectez les limites de vitesse du site.
Octoparse propose un support pour les proxies IP et la résolution de CAPTCHA pour limiter les risques de blocage.
- Est-il possible de scraper des données derrière une connexion ou une liste protégée par authentification ?
Lorsqu’un site nécessite de se connecter pour voir les données souhaitées, votre crawler doit gérer automatiquement le processus de login.
Voici comment je procède simplement avec Octoparse :
- Ouvrir la page de login dans le navigateur intégré d’Octoparse.
- Cliquer sur la zone utilisateur, choisir « Saisir le texte », et taper votre nom d’utilisateur.
- Cliquer sur la zone de mot de passe, choisir « Saisir le texte », et taper votre mot de passe.
- Cliquer sur le bouton « Se connecter », puis choisir « Cliquer sur un bouton » pour valider la connexion. Pour garantir une nouvelle connexion à chaque session, il faut effacer les cookies avant de charger la page (configurez cela dans « Aller à la page Web > Options > Effacer le cache avant de charger la page Web).
- Vous pouvez aussi sauvegarder les cookies après la connexion via « Aller à la page web > Options > Utiliser le cookie de la page actuelle » pour éviter de vous reconnecter à chaque fois (valable jusqu’à expiration du cookie).
- Si un CAPTCHA apparaît, entrez-le manuellement.
Pour un guide détaillé sur Extraire les données derrière une connexion, n’hésitez pas à consulter nos ressources.
- Peut-on se faire sanctionner en crawlant des listes accessibles publiquement ? En général, crawler des pages de listes publiques (comme des catalogues de produits ou des annuaires) est autorisé.
Cependant, certains sites interdisent explicitement l’automatisation dans leurs conditions d’utilisation, ce qui peut entraîner un blocage d’IP ou des poursuites légales. Je recommande toujours de vérifier la politique du site et, si vous avez un doute, de demander la permission.
Conclusion
Le crawling de listes est au cœur de la plupart des opérations d’extraction de données sur le web aujourd’hui, et savoir comment récupérer des données structurées à partir de pages chargées de listes fait toute la différence.
L’astuce consiste à reconnaître quand un site est propice au crawling, à éviter les pièges courants comme une pagination cassée ou des CAPTCHAs, et à utiliser des outils comme Octoparse pour simplifier le processus – même si vous n’êtes pas développeur.
N’oubliez pas non plus l’aspect légal : respecter les politiques du site, se conformer aux lois sur la protection de la vie privée et ne collecter que les données que vous avez l’autorisation d’utiliser.
Lorsque vous maîtrisez ces principes, le crawling de listes devient un outil pratique et puissant pour rassembler les données de haute qualité dont vous avez besoin.
Si vous souhaitez approfondir ces techniques ou avez besoin d’aide, n’hésitez pas à nous contacter à support@octoparse.com.



