Firecrawl fait beaucoup parler de lui depuis son lancement en 2024. Soutenu par Y Combinator et plébiscité par des équipes comme Shopify ou Zapier, cet outil open source permet de transformer n’importe quelle page web en texte structuré prêt pour un LLM. Si vous évoluez dans l’univers de l’IA ou du data engineering, vous en avez probablement entendu parler.
Mais derrière la promesse technique, une réalité s’impose rapidement : Firecrawl est conçu pour les développeurs. Sans notions de Python ou d’API, l’outil est inutilisable. Pour les équipes marketing, les PME, les agences ou les profils non-techniques qui veulent simplement récupérer des données web, il existe des alternatives bien plus accessibles.
Cet article fait le point, du point de vue d’un utilisateur non-technique : un avis honnête sur Firecrawl, ses vraies limites en 2026, et cinq alternatives concrètes pour extraire des données web sans toucher à une ligne de code.
Pour un panorama plus large des outils disponibles, un comparatif des meilleurs web scrapers gratuits est également disponible sur le blog.
Qu’est-ce que Firecrawl ?
Firecrawl est une API de scraping web créée par Mendable.ai, lancée en 2024 et soutenue par Y Combinator. En un appel API, elle transforme le contenu brut d’une page HTML en markdown propre. Si le concept d’extraction de données web vous est encore peu familier, un article dédié couvre les bases en détail.
Le projet est open source (licence MIT, disponible sur GitHub) et compte plus de 97 000 étoiles en mai 2026. Il gère nativement le rendu JavaScript, les sites dynamiques et les redirections, ce qui le distingue des scrapers HTML classiques.
Les quatre modes de fonctionnement
- Scrape : extraction d’une seule URL, retourne markdown, HTML ou JSON.
- Crawl : exploration récursive d’un site entier, avec contrôle de profondeur.
- Map : génère la liste complète des URL d’un domaine en quelques secondes.
- Extract : extraction structurée pilotée par IA, avec définition d’un schéma JSON cible.
L’outil propose également un mode Search qui combine recherche web et extraction de contenu en une seule requête.
Avis sur Firecrawl : les points forts et les vraies limites
Firecrawl : ce que l’outil fait bien
- Output prêt pour l’IA : le markdown généré est propre et cohérent, les balises inutiles sont supprimées automatiquement.
- Gestion du JavaScript : les sites React, Vue et Angular sont rendus côté serveur avant extraction, sans configuration supplémentaire.
- Intégration LLM directe : Firecrawl s’intègre nativement avec LangChain, LlamaIndex et Pinecone, ce qui facilite la construction de pipelines RAG.
- MCP server : depuis début 2025, Firecrawl propose un serveur MCP compatible Claude, permettant aux agents IA de scraper en autonomie.
- Open source : le code est auditable, et l’auto-hébergement est possible pour les équipes avec les ressources techniques nécessaires.
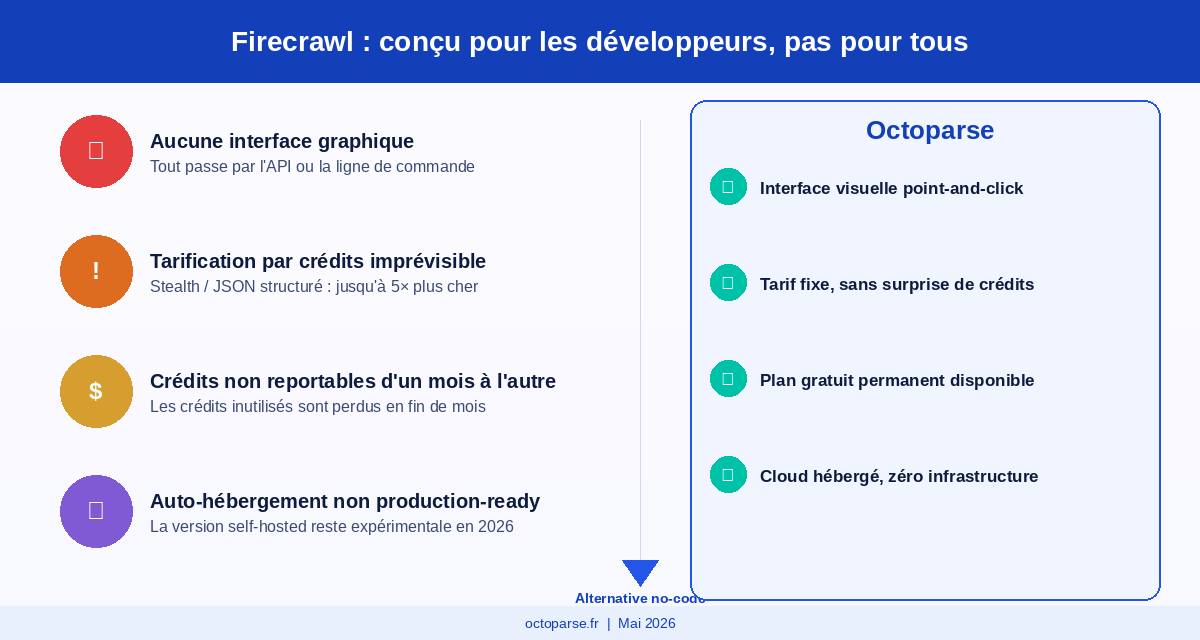
Les limites concrètes de Firecrawl pour les non-développeurs
- Réservé aux développeurs : il n’existe aucune interface graphique. Toutes les interactions passent par l’API ou la ligne de commande. Sans notions de Python ou de Node.js, l’outil est inutilisable.
- Tarification par crédits imprévisible : 1 crédit = 1 page en conditions standard, mais le mode Stealth ou l’extraction structurée consomment jusqu’à 5 crédits par page. Sur des campagnes longues, la facture monte vite.
- Crédits non reportables : les crédits non utilisés en fin de mois sont perdus, sans exception sur les plans Standard et Growth.
- Auto-hébergement pas encore production-ready : la version self-hosted reste expérimentale en 2026, ce qui limite l’intérêt pour les équipes soucieuses de la souveraineté des données.
- Support limité sur les plans bas de gamme : en dessous du plan Growth, le support client se résume à la documentation et aux issues GitHub.
Sur GitHub, plusieurs issues ouvertes début 2026 signalent des comportements incohérents sur la consommation de crédits : certains appels en mode Stealth sont facturés même en cas d’échec de l’extraction. Le support sur les plans inférieurs au Growth se limite à la documentation et aux échanges publics sur le dépôt GitHub, ce qui peut poser problème pour des équipes en production sans ressources techniques dédiées.
Tarifs Firecrawl en 2026
| Plan | Crédits/mois | Prix/mois (annuel) | Requêtes simultanées |
| Free | 1 000 (usage unique) | 0 $ | 2 |
| Hobby | 5 000 | 16 $ | 5 |
| Standard | 100 000 | 83 $ | 50 |
| Growth | 500 000 | 333 $ | 100 |
| Scale | 1 000 000 | 599 $ | 200 |
| Enterprise | Sur devis | Sur devis | Personnalisé |
À noter : les crédits se remettent à zéro chaque mois et ne sont pas reportables. Le mode Stealth ou le format JSON structuré multiplie la consommation par 3 à 5.
Pourquoi chercher une alternative à Firecrawl ?
Firecrawl excelle dans un contexte précis : pipelines de données alimentant des LLM, avec un développeur pour l’intégrer et le maintenir. Hors de ce périmètre, plusieurs profils se retrouvent rapidement bloqués :
- Vous travaillez dans le marketing, la vente ou la veille concurrentielle et vous avez besoin de données web sans passer par votre équipe technique.
- Votre volume de scraping ne justifie pas les 83 $/mois du plan Standard, surtout si vos besoins sont occasionnels ou saisonniers.
- Vous avez besoin de planifier des extractions régulières sans gérer une infrastructure serveur.
- Vous exportez directement vers Excel, Google Sheets ou un CRM, sans pipeline de développement intermédiaire.
- Vous opérez dans un contexte où la conformité RGPD est un critère de sélection de l’outil.
Si vous vous reconnaissez dans l’un de ces cas, la suite de cet article est faite pour vous.
Les 5 meilleures alternatives à Firecrawl en 2026
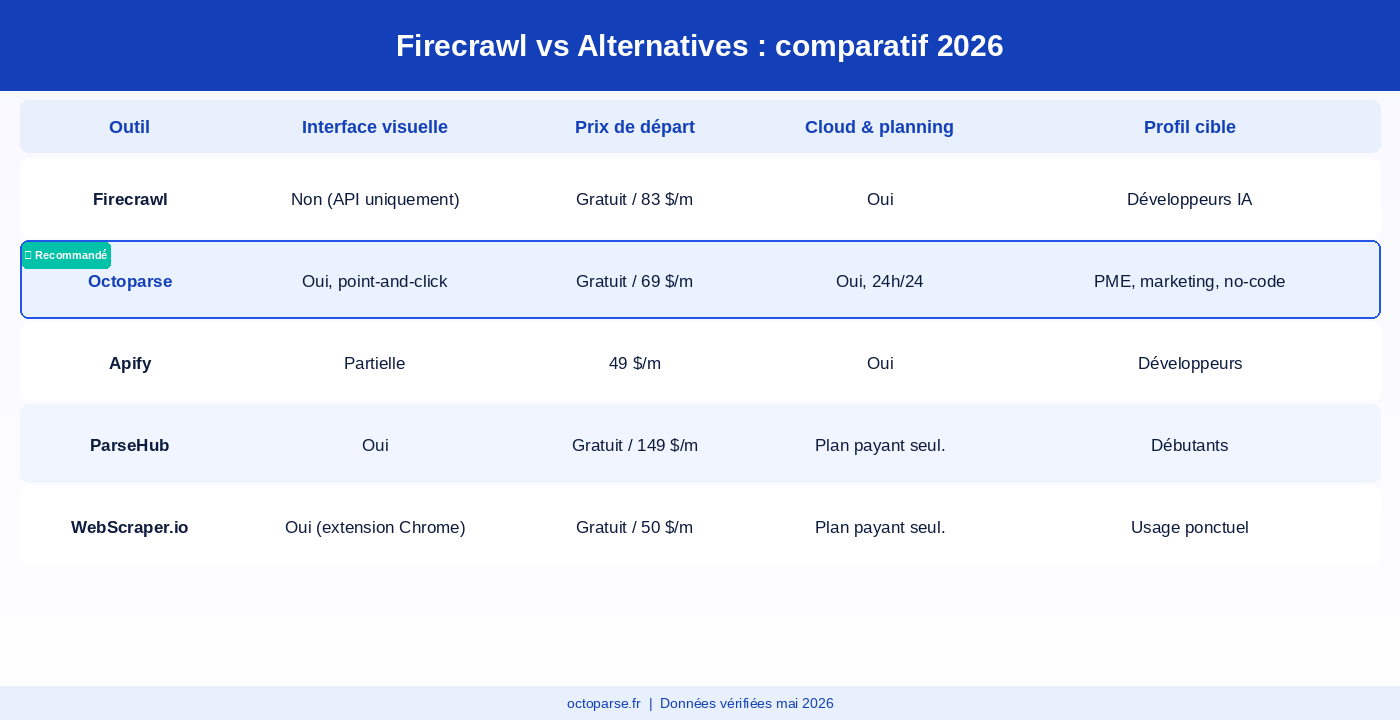
1 Octoparse : la meilleure alternative no-code à Firecrawl
Si Firecrawl est conçu pour les développeurs, Octoparse a été pensé pour l’inverse : permettre à n’importe qui d’extraire des données structurées d’un site web sans écrire une seule ligne de code.
L’interface est visuelle : vous collez une URL, vous cliquez sur les éléments que vous voulez extraire, et Octoparse génère automatiquement la logique de scraping. Les données peuvent ensuite être exportées vers Excel, CSV, Google Sheets ou une base de données, et planifiées pour tourner en continu dans le cloud.
Lancé en 2015 par Octopus Data Inc., Octoparse compte aujourd’hui plus de 2 millions d’utilisateurs dans 140 pays. L’outil est régulièrement cité dans les comparatifs de logiciels de scraping, avec une note de 4,8/5 sur G2 et 4,7/5 sur Capterra pour la facilité d’utilisation.
Ce qu’Octoparse fait mieux que Firecrawl pour les non-développeurs
- Interface point-and-click : aucune connaissance technique requise pour créer un extracteur fonctionnel.
- Modèles pré-construits : des centaines de templates prêts à l’emploi pour les sites les plus courants (Amazon, LinkedIn, Google Maps, TikTok, etc.).
- Cloud scheduling : planifiez vos extractions toutes les heures, tous les jours ou à la fréquence souhaitée, sans serveur à gérer.
- Anti-blocage intégré : rotation d’IP et contournement de CAPTCHA inclus dans tous les plans payants.
- Export direct vers Google Sheets : vos données arrivent directement dans vos outils de travail habituels.
Octoparse est particulièrement adapté aux équipes marketing, aux agences, aux profils e-commerce et aux PME françaises qui veulent automatiser la veille concurrentielle, l’extraction de leads ou le monitoring de prix sans dépendre de leur service IT.
Le plan gratuit est permanent, sans carte bancaire requise, et couvre jusqu’à 50 000 lignes exportées par mois vers Excel ou Google Sheets. Si vous cherchez à récupérer des données web sans faire appel à un développeur, c’est probablement l’endroit le plus logique pour commencer. Tester Octoparse gratuitement.
Tarifs Octoparse
| Plan | Prix/mois (annuel) | Tâches | Cloud |
| Gratuit | 0 $ | 10 | Non |
| Standard | dès 69 $ | 100 | Oui |
| Professionnel | dès 249 $ | 250 | Haute priorité |
| Enterprise | Sur devis | 750+ | Dédié |

Exporter vers Excel, CSV, Google Sheets ou base de données en quelques clics.
Détecter automatiquement les données d’un site web sans aucun codage.
Lancer un scraping sur les sites les plus courants grâce aux modèles pré-construits.
Contourner les blocages grâce à la rotation d’IP et à l’API avancée.
Planifier et automatiser le scraping dans le cloud, 24h/24 et 7j/7.
2 Apify : la plateforme pour les développeurs qui veulent aller plus loin
Apify est souvent cité comme la première alternative sérieuse à Firecrawl dans les comparatifs techniques. Mais sa cible est clairement identifiée : les développeurs et les équipes data qui veulent créer des scrapers personnalisés et les déployer à l’échelle.
Sa force principale est son marketplace de plus de 6 000 Actors : des scrapers pré-construits pour des centaines de sites. Si quelqu’un a déjà résolu votre problème de scraping, vous pouvez utiliser son Actor sans coder. En revanche, personnaliser un Actor ou en créer un nouveau depuis zéro reste réservé aux profils techniques.
- Plans : à partir de 49 $/mois (Free limité disponible)
- Idéal pour : développeurs, data engineers, équipes tech
- Limite principale : sans compétences en JavaScript ou Python, les possibilités de personnalisation sont très réduites
Si vous cherchez un outil que vous pouvez configurer vous-même sans aide technique, Apify n’est pas le bon choix.
3 Bright Data : la solution enterprise pour les volumes critiques
Bright Data est le leader mondial de la collecte de données web à grande échelle. Son infrastructure couvre plus de 72 millions d’adresses IP résidentielles dans 195 pays, ce qui en fait une référence pour contourner les systèmes anti-bot les plus sophistiqués.
Cependant, son positionnement est résolument enterprise : les prix sont sur devis, les contrats mensuels démarrent généralement à plusieurs centaines d’euros, et la prise en main suppose une expérience technique solide. Ce n’est pas une solution pour les équipes de moins de dix personnes sans budget data dédié.
- Plans : sur devis (généralement dès 500 $/mois)
- Idéal pour : entreprises avec volumes massifs, projets d’IA à grande échelle
- Limite principale : coût prohibitif pour les PME, complexité de mise en place
4 ParseHub : le compromis no-code pour les cas simples
ParseHub propose une interface visuelle, comme Octoparse, mais avec des fonctionnalités moins étendues. L’outil convient bien pour scraper des sites statiques ou faiblement dynamiques. Il gère le JavaScript et les formulaires de base.
Sa limite principale est le cloud : le plan gratuit exécute les tâches localement uniquement, et les options de planification et de parallélisation restent en retrait par rapport aux solutions plus complètes.
- Plans : Gratuit / Standard à 149/mois; Pro à 499/mois
- Idéal pour : utilisateurs non-techniques avec des besoins simples et un budget serré
- Limite principale : pas de cloud sur le plan gratuit, moins robuste sur les sites complexes
5 WebScraper.io : l’extension Chrome pour démarrer sans friction
WebScraper.io est une extension Chrome gratuite qui permet de construire des sitemaps de scraping directement dans le navigateur. C’est l’outil idéal pour un usage ponctuel ou pour tester une logique de scraping sans créer de compte.
Si vous souhaitez comparer les extensions de scraping pour Chrome disponibles sur le marché, un comparatif dédié est disponible sur le blog.
L’extension gère les sites dynamiques et la navigation à travers plusieurs pages. Pour les extractions volumineuses ou récurrentes, les limites de l’extension se font vite sentir : une migration vers une solution cloud dédiée devient inévitable.
- Plans : Extension gratuite / Cloud dès 50 $/mois
- Idéal pour : test rapide, extraction ponctuelle, débutants
- Limite principale : pas adapté aux extractions volumineuses ou planifiées
6 Crawl4AI et Scrapy : alternatives open source à Firecrawl pour les développeurs
Pour les développeurs qui cherchent une alternative open source à Firecrawl, Crawl4AI (Python, compatible LLM, licence MIT) et Scrapy (framework Python mature) sont des options solides, à condition d’être à l’aise avec le code. Ces deux outils fonctionnent uniquement en ligne de commande et ne proposent pas d’interface graphique.
Comment choisir son outil de scraping selon son profil
La meilleure alternative à Firecrawl dépend avant tout de votre contexte. Voici un guide de sélection rapide :
| Votre profil | Outil recommandé | Pourquoi ? |
| Non-développeur, PME, marketing | Octoparse | Interface visuelle, cloud, export direct |
| Développeur / data engineer | Apify ou Firecrawl | API puissante, marketplace, flexibilité |
| Volumes massifs, enterprise | Bright Data | Infrastructure IP mondiale, SLA garanti |
| Budget limité, usage ponctuel | WebScraper.io (Chrome) | Gratuit, sans installation |
| Cas simples, profil non-tech | ParseHub | Interface accessible, plan gratuit |
| Projet open source, dev Python | Crawl4AI ou Scrapy | Contrôle total, auto-hébergé |
Si votre priorité est d’obtenir des données rapidement, sans dépendre d’un développeur et sans gérer d’infrastructure, Octoparse reste le choix le plus cohérent pour une équipe francophone en 2026. Un essai gratuit sans carte bancaire est disponible pour tester les fonctionnalités complètes.
Octoparse en pratique : cas d’usage pour le marché français
Au-delà de la comparaison technique, voici comment des équipes françaises utilisent concrètement Octoparse au quotidien :
Veille concurrentielle e-commerce
Extraire automatiquement les prix, les descriptions et les avis produits sur les sites de vos concurrents (Cdiscount, Fnac, ManoMano) pour ajuster votre stratégie tarifaire en temps réel. Les données arrivent directement dans un Google Sheet partagé avec votre équipe. Octoparse propose des modèles Amazon Scraper prêts à l’emploi pour démarrer en quelques minutes.
En France, le secteur du retail en ligne a connu une intensification des guerres de prix depuis 2024. Des équipes e-commerce de PME françaises utilisent Octoparse pour monitorer les fluctuations de prix sur plusieurs dizaines de références en temps réel, sans ressource technique dédiée.
Génération de leads B2B
Extraire des informations d’entreprises depuis des annuaires professionnels (Pages Jaunes, Kompass) ou depuis Google Maps pour alimenter votre CRM. En combinant Octoparse avec un outil de cold outreach, vous pouvez réduire significativement le temps consacré à la prospection B2B manuelle.
Pour aller plus loin sur ce sujet, un comparatif des meilleurs extracteurs d’emails est disponible sur le blog.
Monitoring de données publiques
Surveiller les publications sur data.gouv.fr, les appels d’offres du BOAMP (Bulletin officiel des annonces de marchés publics) ou les nouvelles réglementations sur légifrance.gouv.fr, et recevoir une alerte dès qu’une entrée correspond à vos critères. Les extractions planifiées dans le cloud Octoparse tournent sans intervention humaine, 24h/24. Pour les équipes qui souhaitent une prise en main rapide, le guide complet pour les débutants couvre l’essentiel en moins d’une heure.
FAQ
- Firecrawl est-il gratuit ?
Oui, Firecrawl propose un plan gratuit permanent avec 1 000 crédits (mai 2026). Cela permet de scraper environ 1 000 pages en conditions standard. Pour des usages réguliers ou à volume, le plan Hobby démarre à 16 $/mois (5 000 crédits). Les crédits ne se reportent pas d’un mois à l’autre.
- Firecrawl fonctionne-t-il sans coder ?
Non. Firecrawl est une API : toutes les interactions passent par des appels HTTP ou des scripts Python/Node.js. Il n’existe pas d’interface graphique permettant de scraper un site sans écrire de code. Si vous cherchez un outil sans code, des solutions comme Octoparse sont conçues spécifiquement pour ce cas d’usage.
- Le web scraping est-il légal en France ?
Le web scraping de données publiquement accessibles n’est pas interdit en France. Sa légalité dépend cependant de plusieurs conditions cumulatives. La CNIL a publié en juin 2025 une fiche pratique reconnaissant que le scraping peut reposer sur l’intérêt légitime, à condition de minimiser les données collectées, de respecter le fichier robots.txt et d’exclure toute donnée sensible.
Quelques points à retenir pour une pratique conforme :
- Les données personnelles (emails, noms, téléphones) ne peuvent pas être collectées sans base légale valide au regard du RGPD.
- Le droit sui generis européen protège les bases de données ayant nécessité un investissement substantiel : leur extraction systématique peut être sanctionnée même si les données sont publiques.
- Depuis le 11 août 2026, la loi Bloctel encadre strictement la prospection téléphonique B2C : scraper des numéros de particuliers pour les démarcher est désormais passible d’amendes jusqu’à 375 000 € pour une personne morale.
Pour la prospection B2B à partir de données professionnelles publiques (Pages Jaunes, Kompass), les règles habituelles du RGPD s’appliquent. En cas de doute sur votre cas d’usage, consultez un juriste spécialisé en droit numérique. Pour approfondir ce point, l’article Scraper Pages Jaunes légalement en 2026 détaille les conditions d’une prospection B2B conforme au cadre français.
- Quelle est la meilleure alternative à Firecrawl sans code ?
Octoparse est l’alternative no-code la plus complète à Firecrawl en 2026 : interface visuelle, cloud scheduling, rotation d’IP, et export vers Excel ou Google Sheets. Le plan gratuit permet de commencer sans carte bancaire. Pour les besoins plus simples et ponctuels, WebScraper.io (extension Chrome) est une bonne option d’entrée de gamme.
- Octoparse est-il moins cher que Firecrawl ?
Les deux outils proposent un plan gratuit. Pour les usages payants, Firecrawl démarre à 16/mois (5 000 crédits, facturation annuelle) et Octoparse à 69 /mois pour 100 tâches cloud avec planification incluse. La comparaison directe est difficile car les modèles de facturation sont différents : Firecrawl facture à la page extraite, Octoparse facture au nombre de tâches actives. Pour des besoins non-techniques avec exports réguliers vers Excel ou Google Sheets, Octoparse offre un meilleur rapport fonctionnalités/prix. Pour des pipelines IA à fort volume de pages, Firecrawl Standard à 83 $/mois peut être plus adapté.
- Firecrawl vs Octoparse : quelle différence principale ?
Firecrawl s’adresse aux développeurs qui construisent des pipelines de données pour des applications IA. Octoparse s’adresse aux utilisateurs non-techniques qui veulent extraire et exploiter des données sans coder. Les deux outils font du scraping, mais leurs interfaces, modèles de tarification et cas d’usage cibles sont radicalement différents.
- Octoparse propose-t-il un plan gratuit ?
Oui. Le plan gratuit d’Octoparse est permanent, sans limite de temps et sans carte bancaire requise. Il inclut 10 tâches de scraping, une extraction locale et jusqu’à 50 000 lignes exportées par mois vers Excel, CSV, JSON ou HTML. Créer un compte gratuitement.
- Firecrawl a-t-il un serveur MCP compatible avec les agents IA ?
Oui. Firecrawl propose depuis début 2025 un serveur MCP (Model Context Protocol) qui permet à des agents IA, notamment Claude, de scraper des pages web en autonomie dans le cadre d’un workflow agentique. C’est une fonctionnalité appréciée des développeurs qui construisent des pipelines RAG ou des agents de veille automatisée. Pour les équipes non-techniques, cette intégration reste complexe à mettre en place sans compétences en développement.
Octoparse propose également une intégration MCP adaptée aux profils qui souhaitent connecter leurs extractions de données à des workflows IA sans coder.
- Quelle est la différence entre Firecrawl et un outil de web scraping classique ?
Un outil de scraping classique (Octoparse, ParseHub, WebScraper.io) extrait des données structurées depuis une page web : prix, noms, descriptions, coordonnées. L’objectif est d’obtenir un tableau de données exploitable dans Excel ou un CRM.
Firecrawl a une finalité différente : il convertit le contenu d’une page web en texte propre au format markdown, pensé pour être ingéré par un modèle de langage (LLM). Son usage principal est l’alimentation de pipelines d’IA, de systèmes RAG ou d’agents autonomes. Ce n’est pas un extracteur de données tabulaires au sens classique du terme.



