La plupart des tutoriels de web scraping vous montrent trois lignes de code, et ça a l’air simple. Sauf que sur un vrai site en production, vous tombez sur ça :
Pas de données. Juste une coquille vide.
Ce n’est pas un bug de votre code. C’est la réalité des sites web modernes : ils ne servent plus leurs données directement dans le HTML. Ils attendent qu’un navigateur exécute JavaScript pour afficher le contenu. Et si votre outil de scraping n’exécute pas JavaScript, il ne voit rien.
C’est exactement là qu’intervient le navigateur headless.
Qu’est-ce qu’un navigateur headless ?
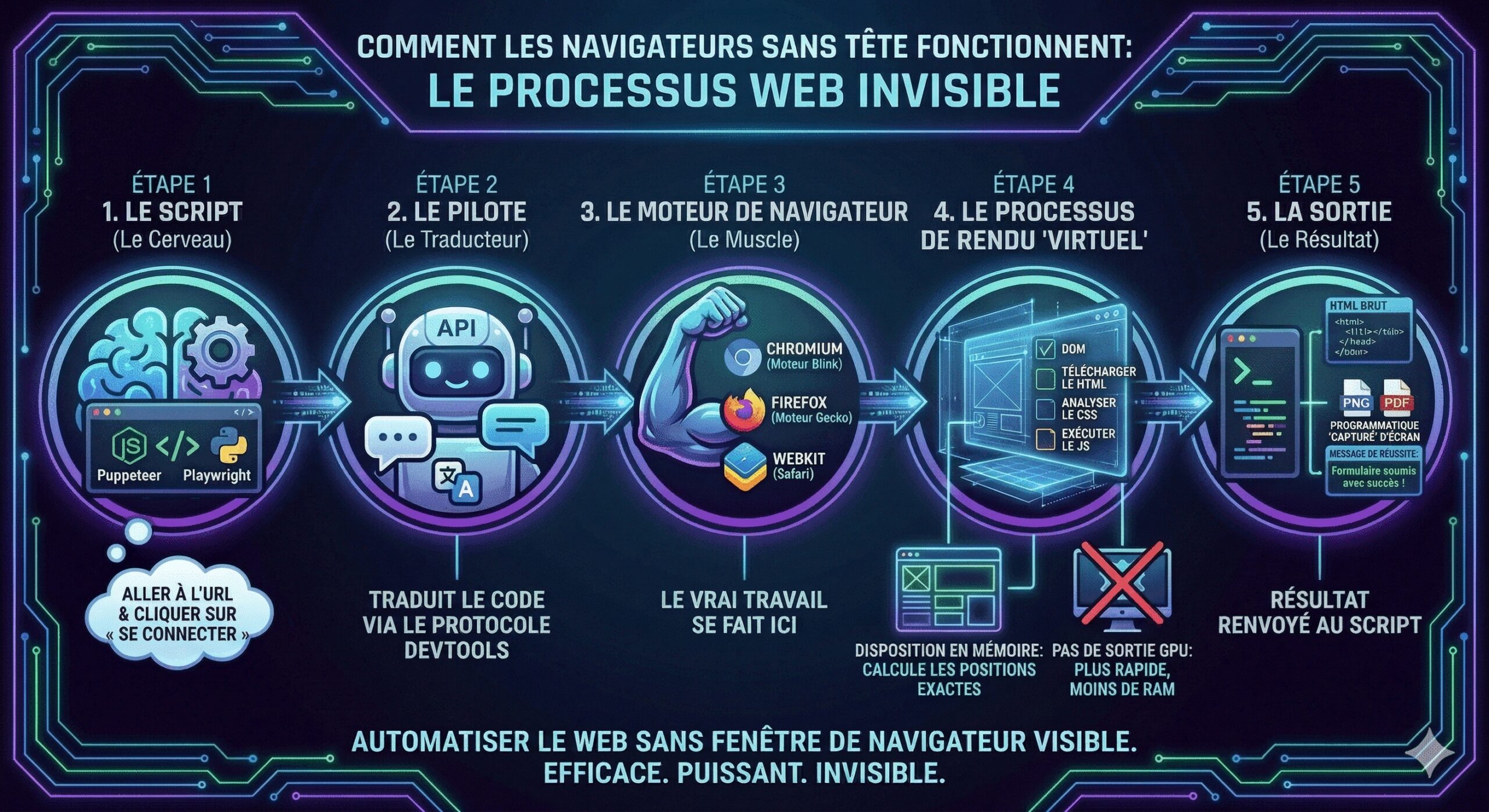
Un navigateur headless, c’est un navigateur web complet — Chrome, Firefox ou WebKit — qui tourne sans interface graphique.
Pas de fenêtre. Pas d’onglets. Pas de barre d’adresse. Uniquement le moteur de rendu, opérationnel en arrière-plan et contrôlable par du code.
L’équipe Chromium décrit elle-même ce mode comme “un environnement non surveillé”, où le navigateur complet s’exécute sans interface visible. Ce qui importe, c’est ce qu’il fait malgré l’absence d’interface :
- Il charge la page complète et génère le DOM
- Il exécute JavaScript, y compris les requêtes AJAX et les appels API
- Il gère les cookies, les sessions de connexion et les formulaires
- Il interagit avec les boutons, les menus déroulants, les carousels
- Il passe les vérifications anti-bot basiques (fingerprinting de navigateur)
En pratique : là où requests.get() récupère un squelette HTML, un navigateur headless récupère la page telle qu’elle apparaît dans votre Chrome. C’est la différence entre gratter un mur et ouvrir une porte.
Pourquoi cURL et Python Requests échouent sur les sites modernes
Prenons un exemple concret. Vous tentez :
Vous vous attendez à récupérer une liste de produits. Vous obtenez :
Voilà ce qui se passe réellement lors du chargement d’une page moderne :
- Le serveur envoie une page HTML vide (le “shell”)
- Le navigateur télécharge et exécute JavaScript
- JavaScript appelle l’API interne pour récupérer les données produit
- JavaScript injecte ces données dans le DOM — la page s’affiche
cURL s’arrête à l’étape 1. Il ne peut pas exécuter l’étape 2. Donc il ne voit jamais les étapes 3 et 4.
Ce problème touche une large majorité des sites français que vous voudrez scraper : Cdiscount, ManoMano, SeLoger, Leboncoin, Indeed.fr — tous s’appuient sur du contenu chargé dynamiquement. Ce n’est pas une configuration marginale, c’est le standard actuel du développement web.
Un navigateur headless résout exactement ce problème : il exécute l’intégralité du cycle de chargement de la page avant d’extraire les données.
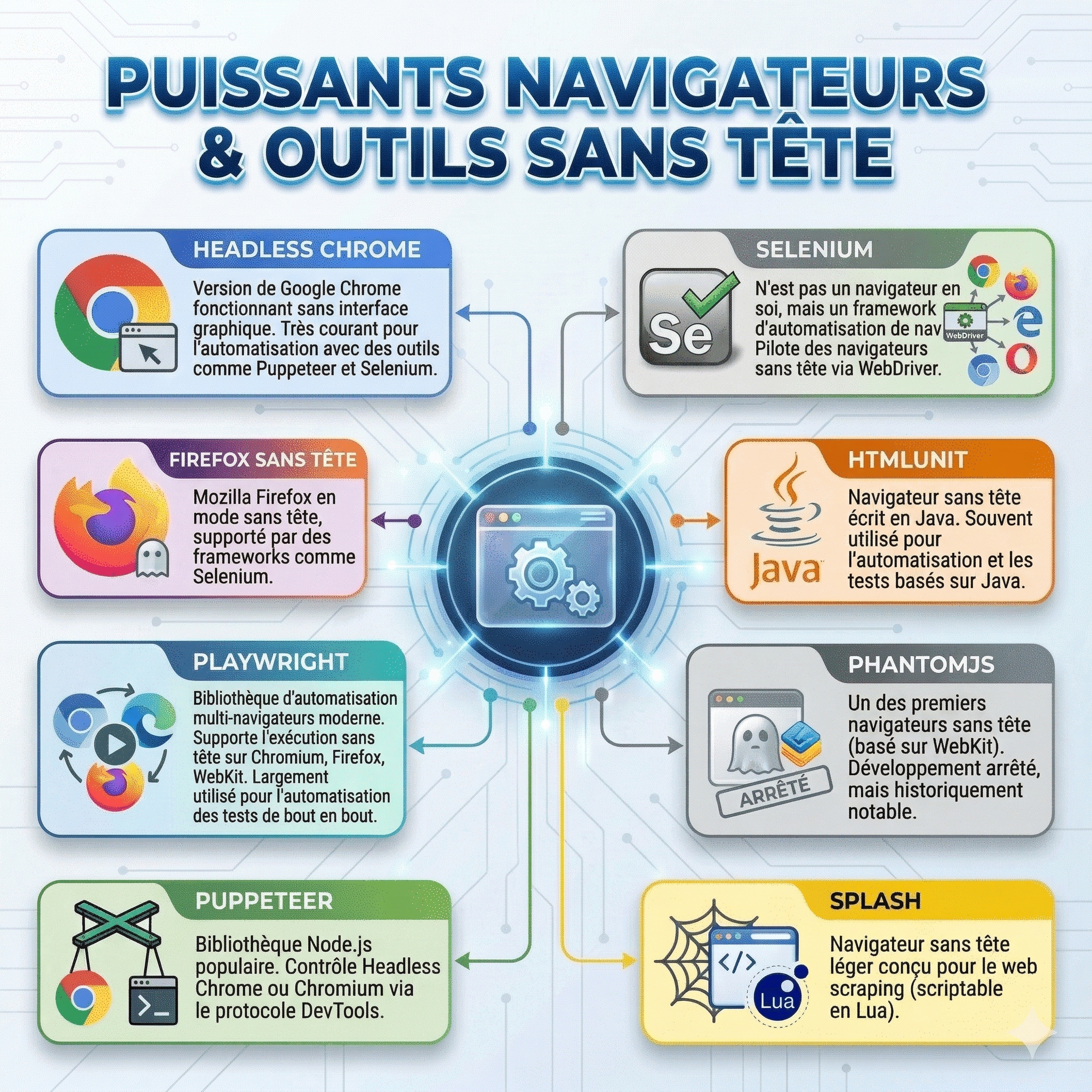
Playwright, Puppeteer, Selenium : lequel choisir ?
Trois outils dominent le marché de l’automatisation de navigateur headless. Voici une comparaison franche, sans langue de bois.
Playwright
Développé par Microsoft (par l’équipe qui avait construit Puppeteer chez Google), Playwright est devenu le standard de fait pour les nouveaux projets en 2026.
Ses atouts principaux :
- Support natif de Chromium, Firefox et WebKit — ce qui permet de varier les empreintes navigateur pour contourner certains systèmes anti-bot
- API unifiée pour Python, JavaScript, Java et C#
- Gestion native de l’attente des éléments, des téléchargements, des iframes
- Meilleure gestion du parallélisme que Selenium
Si vous démarrez un nouveau projet de scraping JavaScript aujourd’hui, Playwright est le choix par défaut.
Puppeteer
Le pionnier. Lancé par Google en 2017, Puppeteer reste très utilisé dans les équipes qui ont du code JavaScript existant à maintenir.
Ses limites sont connues : support Chromium uniquement, et peu de raisons de l’adopter sur un nouveau projet face à Playwright. Il reste cependant excellent pour l’automatisation Chrome-only et la génération de PDF ou screenshots.
Selenium
Selenium a formé des générations de développeurs QA. Il supporte le plus grand nombre de langages (Python, Java, C#, Ruby, JavaScript) et dispose d’une documentation massive sur la communauté OpenClassrooms, Stack Overflow, et les forums francophones.
Son point faible : la couche WebDriver ajoute de la latence par rapport aux protocoles DevTools utilisés par Playwright et Puppeteer. À grande échelle, cet overhead se fait sentir.
Un point important pour les utilisateurs Selenium : depuis 2023, le mode --headless historique est officiellement déprécié. Si vous utilisez Selenium 4, utilisez --headless=new ou migrez vers Playwright.
Lightpanda
Un outil moins connu mais à surveiller côté français : Lightpanda est un navigateur headless léger développé pour l’automatisation web, avec une empreinte mémoire réduite par rapport à Chromium. Encore en phase de maturation, mais intéressant pour des cas d’usage spécifiques (scraping haute fréquence sur infrastructure contrainte).
| Outil | Navigateurs | Langage | Courbe d’apprentissage | Idéal pour |
| Playwright | Chromium, Firefox, WebKit | Python, JS, Java, C# | Moyenne | Nouveaux projets multi-sites |
| Puppeteer | Chromium | JavaScript / Node.js | Faible | Automatisation Chrome |
| Selenium | Chrome, Firefox, Safari, Edge | Python, Java, C#, Ruby, JS | Élevée | Équipes QA legacy |
| Octoparse | Gestion automatique | Sans code | Très faible | Scraping métier à grande échelle |
Votre premier script Playwright en quelques minutes
Installation :
Script basique pour extraire du contenu dynamique :
Ce script lance Chrome en mode headless, ouvre la page, attend le chargement complet du réseau, puis extrait les données. Exactement ce que vous feriez manuellement — mais automatisé.
Ce que les tutoriels ne vous disent pas : le vrai coût d’un navigateur headless
Un navigateur headless, c’est puissant. Mais en conditions réelles de production, la complexité s’accumule vite.
Le script de 30 lignes du tutoriel devient rapidement :
- Gestion des retry : les requêtes échouent aléatoirement, il faut des mécanismes de reprise
- Rotation de proxies : votre IP se fait bloquer après quelques centaines de requêtes
- Résolution de CAPTCHAs : Cloudflare Turnstile, DataDome (solution française, d’ailleurs), hCaptcha — tous détectent les navigateurs headless
- Fingerprinting : les systèmes anti-bot analysent le rendu WebGL, les empreintes canvas, les mouvements de souris simulés, et des dizaines d’autres signaux
- Gestion de la pagination et des sessions : login, cookies de session, scroll infini
- Orchestration cloud : scheduling, export CSV/Excel, monitoring des erreurs
En 2026, les systèmes comme DataDome (créé en France) ou Cloudflare ne vérifient plus seulement votre User-Agent. Ils analysent des centaines de signaux comportementaux et techniques. Contourner ces protections de façon fiable demande un travail conséquent en maintenance continue.
Ce n’est pas insurmontable, mais c’est du temps que beaucoup d’équipes n’ont pas.
Pour approfondir la gestion des proxies dans un contexte de scraping : Comment utiliser un serveur proxy pour le web scraping
Une alternative sans code : quand Playwright n’est pas la bonne réponse
Si votre objectif est de scraper régulièrement des données pour alimenter un CRM, surveiller les prix concurrents ou générer des leads, coder et maintenir un navigateur headless n’est pas forcément le meilleur usage de vos ressources.
C’est le cas d’usage qu’Octoparse adresse directement.
Ce qu’Octoparse gère à votre place :
- L’orchestration des instances de navigateur headless
- La rotation automatique des proxies IP
- La résolution des CAPTCHAs et l’adaptation aux protections anti-bot
- L’ajustement du fingerprinting pour paraître comme un utilisateur réel
- Le scheduling, l’exécution cloud et l’export vers Excel, CSV ou base de données
En pratique, Octoparse choisit automatiquement la stratégie de rendu adaptée à chaque site : moteur léger pour les pages statiques, mode headless complet pour le contenu dynamique, voire mode visible si nécessaire pour certaines protections avancées.

Transformer les sites web vers Excel, CSV, Google Sheets ou base de données.
Auto-détecter les sites Web et extraire les données sans aucun codage.
Scraper les sites populaires en quelques clics avec les modèles pré-construits.
Ne se trouver jamais bloqué grâce aux proxies IP et à l’API avancée.
Service Cloud pour programmer le scraping de données.
Pour démarrer :
- Rendez-vous sur octoparse.fr et créez un compte gratuit
- Téléchargez l’application desktop
- Créez une tâche personnalisée ou utilisez un modèle prédéfini
Pour les sites parmi les plus scrapés en France — Pages Jaunes, Leboncoin, SeLoger, Cdiscount, Amazon.fr — des modèles prêts à l’emploi existent. Lisez aussi : Top 12 des sites web les plus scrapés en France
Si votre besoin est de scraper 1 000 pages, d’automatiser l’exécution quotidienne et d’exporter vers Excel sans gérer d’infrastructure, Octoparse répond à ce cas d’usage sans ligne de code.
Pour un usage plus avancé incluant des agents IA, vous pouvez aussi connecter Octoparse à Claude via le protocole MCP : Comment utiliser Claude pour scraper des sites web en 2026
Le cadre légal en France : ce que dit la CNIL sur le scraping
C’est une question que posent régulièrement les équipes marketing et les responsables data en France.
La position de la CNIL (juin 2025) est claire : le web scraping n’est pas interdit en lui-même par le RGPD. Une organisation privée peut y recourir sur la base de l’intérêt légitime, sous réserve de mettre en place des garanties adaptées.
En pratique, voici les lignes à ne pas franchir :
- Ne pas scraper de données personnelles sans base légale (nom, email, téléphone d’un particulier)
- Respecter le fichier robots.txt et les conditions d’utilisation du site cible
- Ne pas constituer de bases de prospection commerciale sans informer les personnes concernées (article 14 du RGPD)
- Limiter la collecte au strict nécessaire — notamment si la page mélange données publiques et données personnelles
Pour les usages de veille tarifaire, d’analyse concurrentielle ou d’agrégation de données publiques, le scraping est généralement légal en France. Pour tout doute sur un cas spécifique, consultez votre DPO ou un avocat spécialisé.
Lire aussi : Comment scraper une page web en JavaScript sans coder
Navigateur headless, cURL ou Octoparse : la règle de décision
Pas besoin de choisir au hasard. Voici la grille que j’utilise :
Utilisez cURL ou Python Requests quand :
- Le site sert du HTML statique sans JavaScript
- L’API du site est accessible directement (vérifiez l’onglet Réseau des DevTools)
- Vous avez besoin de la plus faible latence possible pour du scraping haute fréquence
Utilisez Playwright ou Puppeteer quand :
- Le contenu est chargé dynamiquement via JavaScript
- Une connexion ou un formulaire est requis
- Vous avez besoin d’un contrôle total sur chaque étape (scroll infini, interactions complexes)
- Vous intégrez le scraping dans un pipeline de données maison
Utilisez Octoparse quand :
- L’objectif est opérationnel : scraper régulièrement, exporter proprement, sans maintenance code
- Votre équipe n’a pas de développeur dédié au scraping
- Vous scrapez des milliers de pages sur des sites qui changent régulièrement
- Vous avez besoin d’un résultat rapidement, pas dans trois semaines après debugging
Pour aller plus loin sur les outils disponibles : 17 outils de scraping gratuits à ne pas manquer
FAQ
- Qu’est-ce qu’un navigateur headless ?
Un navigateur headless est un navigateur web complet (Chrome, Firefox, WebKit) qui s’exécute sans interface graphique. Il charge les pages, exécute JavaScript et interagit avec les éléments comme un vrai navigateur — mais piloté par du code, sans qu’aucune fenêtre ne s’affiche. Utilisé principalement pour le scraping de contenu dynamique, les tests automatisés et l’automatisation de tâches web répétitives.
- C’est quoi le mode headless ?
Le mode headless désigne le mode de fonctionnement d’un navigateur sans rendu visuel. Activé via des options comme --headless dans Chrome ou via les APIs Playwright/Puppeteer, il permet d’exécuter toutes les opérations du navigateur (chargement de page, exécution JavaScript, soumission de formulaires) sans consommer de ressources graphiques. Plus rapide et moins gourmand en mémoire qu’un navigateur avec interface.
- Les navigateurs headless peuvent-ils se faire bloquer ou détecter ?
Oui. Les systèmes anti-bot modernes — notamment DataDome (entreprise française) ou Cloudflare Turnstile — analysent des centaines de signaux : rendu WebGL, empreintes canvas, comportement de la souris, fréquence des requêtes, IP répétées. Un navigateur headless mal configuré se fait détecter rapidement. Pour du scraping à grande échelle, il faut gérer la rotation d’IP, le fingerprinting et les délais entre requêtes.
- Playwright ou Puppeteer : lequel choisir en 2026 ?
Pour un nouveau projet, Playwright. Il supporte plusieurs navigateurs (Chromium, Firefox, WebKit), ce qui est utile pour varier les empreintes et contourner certaines détections. Son API est plus moderne et il bénéficie d’un développement actif. Puppeteer reste pertinent si vous avez une base de code JavaScript existante qui l’utilise, mais il y a peu de raisons de le choisir pour un projet from scratch.
- Selenium est-il encore pertinent en 2026 ?
Pour les tests QA en entreprise et les équipes avec un historique Selenium important, oui. Pour le scraping web pur, Playwright est généralement plus adapté. Notez que le mode --headless historique de Selenium est officiellement déprécié depuis 2023 — utilisez --headless=new avec Selenium 4 ou migrez.
- Quand utiliser Octoparse plutôt qu’un navigateur headless ?
Quand l’objectif n’est pas “comment scraper” mais “comment avoir ces données de manière fiable tous les jours, sans y passer des heures de maintenance”. Si vous devez scraper des milliers de pages régulièrement, exporter vers Excel ou CSV, et que vous n’avez pas une équipe dev dédiée à la maintenance du scraper, Octoparse est souvent plus efficace qu’une solution Playwright maison.
- Le scraping web est-il légal en France ?
Le scraping de données publiques non personnelles est généralement légal. La CNIL précise que le recours au web scraping est possible sur la base de l’intérêt légitime, avec des garanties adaptées. En revanche, scraper des données personnelles sans base légale, ou en violant les conditions d’utilisation d’un site, expose à des risques juridiques. En cas de doute, consultez un professionnel du droit numérique.



