Un agent IA qui raisonne bien mais manque de données fiables, c’est comme un analyste brillant enfermé dans une salle sans internet. Il peut structurer, inférer, synthétiser, mais il ne peut agir que sur ce qu’il sait déjà, c’est-à-dire ses données d’entraînement, souvent vieilles de plusieurs mois.
Le web scraping est la réponse à ce problème. Cet article montre comment connecter concrètement un agent IA à Octoparse via le protocole MCP, et détaille 3 cas d’usage concrets prêts à mettre en place.
Les 9 exemples d’IA agentique en entreprise illustrent les cas d’usage que ce tutoriel permet de mettre en place techniquement.
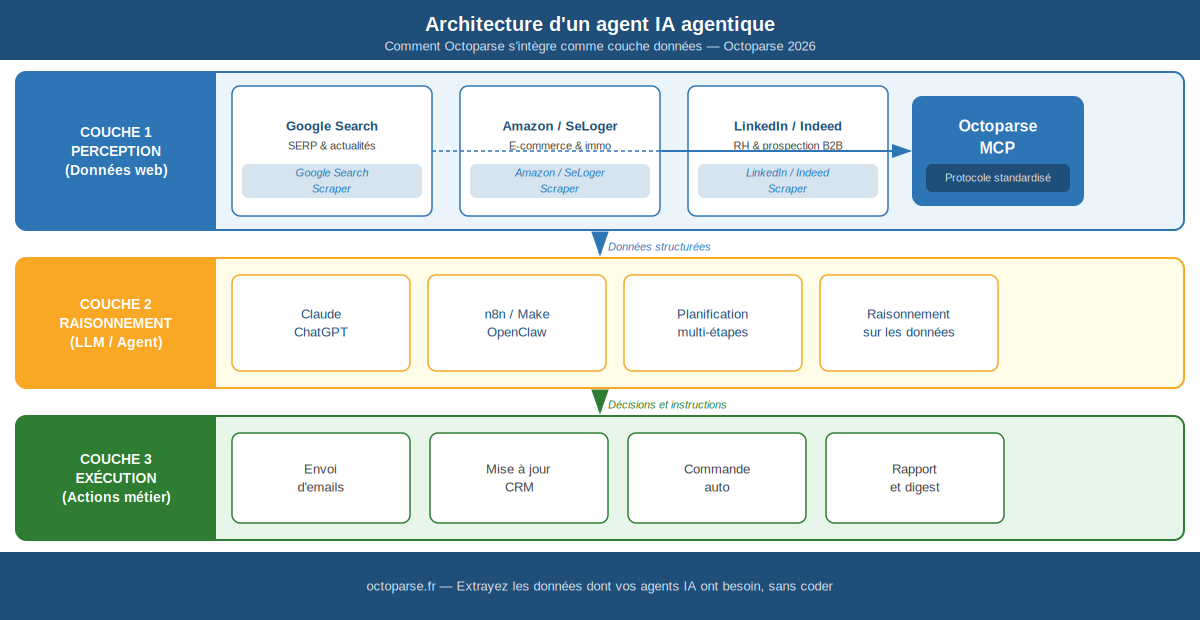
Pourquoi un agent IA a besoin d’une couche données dédiée
Un agent IA opère selon une boucle en trois couches :
- Perception : l’agent collecte les informations dont il a besoin pour raisonner.
- Raisonnement : le LLM analyse ces données, planifie les étapes et décide des actions.
- Exécution : l’agent agit sur le monde réel (envoie un email, met à jour un CRM, déclenche une commande).
La couche de perception est le talon d’Achille. La plupart des agents déployés en production échouent non pas à cause du raisonnement du LLM, mais parce que leurs données d’entrée sont périmées, incomplètes ou mal structurées.
| Source de données | Avantages | Limites |
| API dédiée | Données structurées, fiables | Couverture limitée, coût élevé |
| Moteur de recherche | Accès large, temps réel | Données brutes, peu structurées |
| Web scraping | Universel, données actualisées | Nécessite un outil adapté |
Le web scraping permet d’extraire des données structurées depuis n’importe quelle source web, sans dépendre d’une API tierce. C’est la solution la plus flexible pour alimenter un agent IA avec des données variées et actualisées.
Le protocole MCP : l’interface standardisée entre agent et données
Le protocole MCP (Model Context Protocol) est un standard open source qui définit comment un agent IA communique avec des outils externes. Une fois Octoparse configuré comme serveur MCP, n’importe quel agent compatible (Claude, ChatGPT, n8n, Make) peut lui envoyer des instructions de collecte et recevoir des données structurées en retour, sans développement supplémentaire.
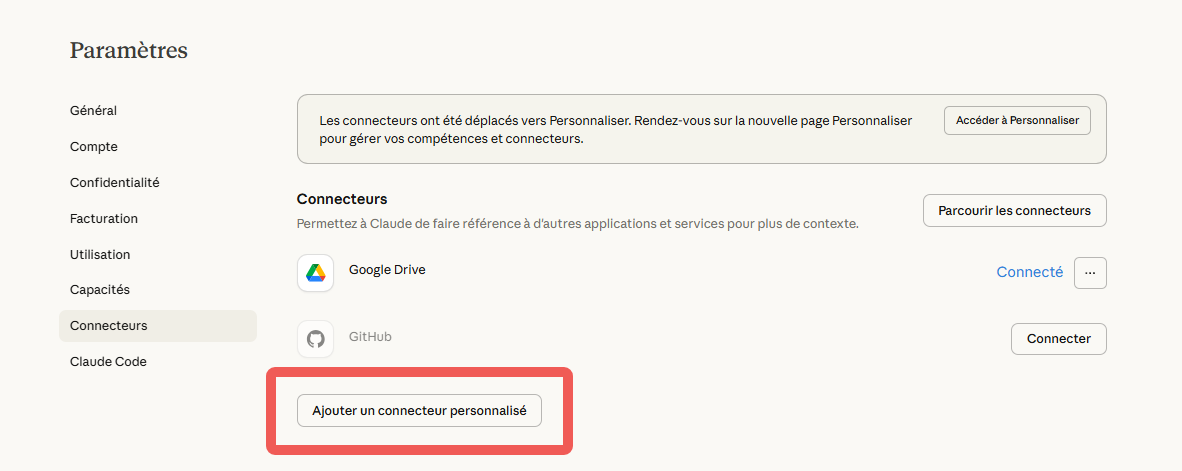
Connecter Octoparse à votre agent IA via MCP : guide pas à pas
Ce tutoriel utilise Claude comme agent de référence. La procédure est identique pour ChatGPT, n8n et Make. Le guide d’installation complet est disponible sur la documentation MCP Octoparse.
Étape 1 : créer votre compte Octoparse et générer une clé API
Créez votre compte Octoparse gratuitement, puis accédez à votre espace utilisateur pour générer une clé API.
Étape 2 : installer le serveur MCP Octoparse
Dans votre terminal, exécutez la commande d’installation. Octoparse MCP est compatible avec tous les environnements MCP standard.
Étape 3 : configurer Octoparse dans votre agent IA
Ajoutez Octoparse comme serveur MCP dans la configuration de votre agent. Pour Claude Desktop, éditez le fichier de configuration JSON et ajoutez l’entrée Octoparse avec votre clé API.
Étape 4 : tester la connexion et lancer votre premier scraping
Relancez votre agent et demandez-lui de lister les outils disponibles. Octoparse doit apparaître dans la liste. Vous pouvez ensuite lui demander d’extraire des données depuis une URL.
La configuration détaillée de Claude avec Octoparse MCP est couverte dans Claude scraping web avec Octoparse MCP.

Intégration directe avec Claude, ChatGPT, n8n et Make via le protocole MCP, sans aucun développement.
Extrayez des données structurées depuis n’importe quelle page web : e-commerce, presse, annuaires, réseaux sociaux.
Plus de 500 modèles prêts à l’emploi pour démarrer en quelques minutes sur les sources les plus utilisées en France.
Proxies rotatifs et gestion anti-détection intégrés : vos collectes tournent en production sans interruption.
Service Cloud avec planification automatique : programmez vos extractions et récupérez vos données sans intervention manuelle.
3 cas d’usage concrets : agent IA et web scraping en pratique
Cas 1 : veille tarifaire e-commerce avec un agent IA
Objectif : surveiller automatiquement les prix concurrents sur Amazon et déclencher une alerte dès qu’un écart significatif est détecté.
- Collecte quotidienne : l’agent interroge Octoparse MCP pour extraire les prix des produits cibles sur Amazon.
- Comparaison : le LLM compare les données collectées avec les prix de référence stockés.
- Alerte : si l’écart dépasse le seuil défini, l’agent envoie une notification ou met à jour le tableau de bord.
Ce cas d’usage est particulièrement pertinent pour les équipes e-commerce françaises qui surveillent des plateformes comme Cdiscount, Fnac ou La Redoute, où les prix varient plusieurs fois par jour.
Tous les modèles d’extraction Amazon sont regroupés sur la page Amazon Scraper.
Modèle spécifique :
https://www.octoparse.fr/template/amazon-product-scraper-by-keywords
Ce cas couvre uniquement la couche de collecte. Pour les stratégies de surveillance tarifaire, les meilleurs outils de suivi des prix Amazon complètent ce panorama.
Cas 2 : collecte automatisée de données scientifiques
Objectif : extraire automatiquement les articles pertinents depuis Google Scholar sur un sujet de recherche défini, et les structurer dans un fichier exploitable.
- Requête : l’agent reçoit un sujet de recherche et un ensemble de mots-clés.
- Collecte : il interroge Octoparse MCP qui scrappe Google Scholar et retourne titres, auteurs, abstracts et DOI.
- Structuration : le LLM organise les résultats par pertinence et génère un résumé de littérature.
- Export : les données structurées sont exportées en CSV ou intégrées dans l’outil de gestion bibliographique.
Ce cas d’usage est particulièrement adopté dans les équipes de recherche des universités françaises et des organismes comme l’INSERM ou le CNRS, où le volume de publications à traiter est considérable.
Modèle Octoparse :
https://www.octoparse.fr/template/google-scholar-scraper
Pour une vue d’ensemble des outils IA dédiés à la recherche, voir les 8 meilleurs outils IA gratuits pour la recherche scientifique.
Cas 3 : surveillance des médias et de l’e-réputation en continu
Objectif : surveiller en continu les mentions de votre marque dans la presse en ligne et produire un résumé quotidien avec analyse de sentiment.
- Collecte continue : l’agent programme une collecte récurrente via Octoparse MCP sur une liste de sources médias définies.
- Filtrage : le LLM identifie les articles contenant les mots-clés surveillés.
- Analyse : pour chaque article pertinent, l’agent évalue le sentiment et extrait les points clés.
- Rapport : un résumé structuré est généré et envoyé par email ou publié dans un espace partagé.
En France, ce type de veille est utilisé par les équipes communication et relations presse des ETI et grandes entreprises, notamment pour surveiller leur exposition dans des médias comme Le Monde, Les Echos ou BFM Business.
Modèle Octoparse :
https://www.octoparse.fr/template/smart-article-scraper
Pour la collecte depuis des sources de presse spécifiques, voir récupérer des données d’actualités sur Le Figaro.
Déployer un agent IA avec web scraping : points de vigilance
Quelques contraintes pratiques à avoir en tête :
- Les sites dynamiques et anti-bots : certains sites protègent leur contenu avec des CAPTCHAs. Octoparse intègre une gestion des proxies et des mécanismes anti-détection.
- Le coût des appels LLM : un agent qui collecte et analyse en continu génère des coûts API non négligeables. Commencez par des collectes planifiées plutôt que temps réel.
- La conformité RGPD : pour toute collecte impliquant des données personnelles, respectez les principes de minimisation et de finalité. La CNIL a publié en 2026 des lignes directrices sur le scraping.
- La supervision des actions critiques : un agent qui peut déclencher des commandes ou envoyer des emails en autonomie doit inclure des points de validation humaine pour les actions irréversibles.
FAQ — Questions fréquentes sur le scraping web avec un agent IA
- Pourquoi un agent IA a-t-il besoin de données web en temps réel ?
Un LLM raisonne à partir de ses données d’entraînement, qui ont plusieurs mois de retard. Pour des cas d’usage comme la veille tarifaire, la prospection ou le suivi de marché, l’agent a besoin d’informations actualisées pour prendre des décisions pertinentes.
- Quelle est la différence entre une API et le web scraping pour alimenter un agent IA ?
Une API fournit des données structurées depuis un service qui la propose explicitement. Le web scraping extrait des données depuis n’importe quelle page web, même sans API disponible. Les deux approches sont complémentaires.
- Le web scraping avec un agent IA est-il légal en France ?
Le scraping de données publiquement accessibles est admis dans un cadre précis : respecter le fichier robots.txt, ne pas contourner de mesures de protection technique, et se conformer au RGPD pour toute donnée personnelle. Les lignes directrices publiées par la CNIL en 2026 clarifient ces conditions.
- Comment connecter Octoparse à un agent IA sans coder ?
Via le protocole MCP. Une fois le serveur Octoparse MCP installé, votre agent peut interroger Octoparse directement pour extraire des données depuis n’importe quelle source web. La procédure complète pour Claude, ChatGPT, n8n et Make est détaillée dans le guide d’installation Octoparse MCP.
- Quels sites peut-on scraper avec Octoparse et un agent IA ?
Octoparse peut extraire des données depuis la grande majorité des sites web publics : e-commerce, presse, annuaires, réseaux sociaux, plateformes d’emploi, sites immobiliers. La page des modèles disponibles recense les sources préconfigurées.
- Peut-on utiliser Octoparse MCP gratuitement ?
Oui. Octoparse propose une version gratuite qui permet de tester l’intégration MCP avec un volume de collecte limité, suffisant pour configurer et valider vos premiers cas d’usage. L’offre gratuite inclut l’accès aux modèles préconfigurés et à l’API. Les volumes plus importants nécessitent un abonnement payant, dont les tarifs sont détaillés sur la page de tarification.
Une question sur la configuration de votre agent IA ? Écrivez-nous : support@octoparse.com



