BeautifulSoup compte parmi les bibliothèques Python les plus utilisées au monde pour le web scraping : plus de 14 000 étoiles sur GitHub, une communauté active depuis 2004, une documentation de référence que la plupart des développeurs Python ont déjà consultée. Mais si vous n’êtes pas développeur, ou si votre besoin est simplement d’extraire des données sans écrire ni maintenir du code, BeautifulSoup n’est pas l’outil qu’il vous faut.
Cet article compare BeautifulSoup et Octoparse sur les points qui comptent vraiment dans la pratique : facilité de prise en main, gestion des sites dynamiques, contournement de l’anti-scraping, et capacité à monter en charge.
Objectif : vous aider à choisir l’outil adapté à votre profil, sans détour.
Qu’est-ce que BeautifulSoup ?
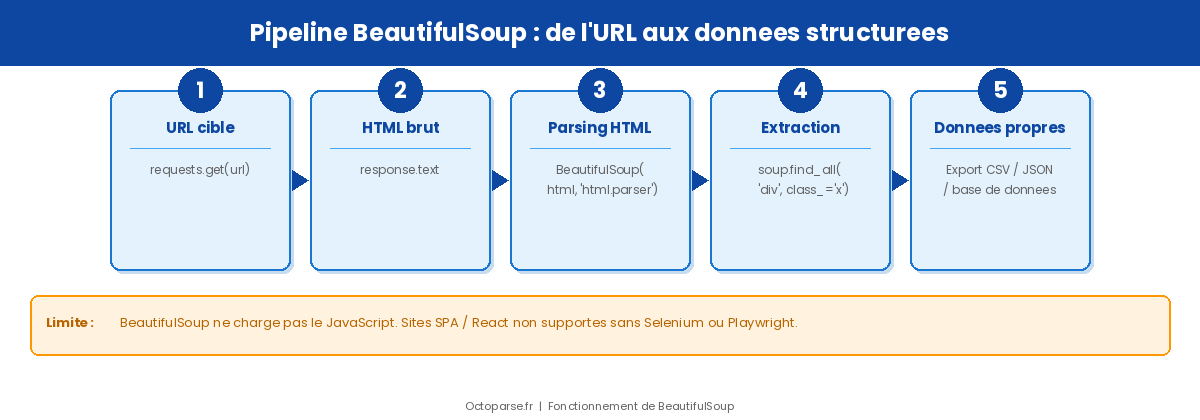
BeautifulSoup (importée sous le nom bs4) est une bibliothèque Python open source spécialisée dans le parsing de HTML et de XML. Lancée en 2004 par Leonard Richardson, elle reste aujourd’hui l’une des références du scraping Python grâce à sa syntaxe intuitive et son intégration facile dans n’importe quel environnement.
Son fonctionnement repose sur deux étapes : la bibliothèque requests récupère le code HTML brut de la page cible, puis BeautifulSoup parse ce code et expose une arborescence navigable pour en extraire les données.
Ce que BeautifulSoup fait bien
- Parsing HTML statique : extraction ciblée depuis n’importe quel tag, classe CSS, attribut ou sélecteur XPath.
- Flexibilité totale : la logique d’extraction est entièrement dans le code Python, ce qui facilite l’intégration dans des pipelines complexes.
- Compatibilité écosystème Python : s’intègre naturellement avec Scrapy, Pandas, ou dans des workflows d’alimentation de bases vectorielles pour des applications RAG ou des agents IA.
- Gratuit et open source : aucun abonnement, aucune limite imposée par l’éditeur, code source auditable.
- Parsers multiples : supporte
html.parser(natif Python),lxml(plus rapide) ethtml5lib(plus tolérant aux HTML mal formés).
Les limites de BeautifulSoup
La limite principale de BeautifulSoup est structurelle : la bibliothèque parse le HTML statique renvoyé par le serveur. Elle ne charge pas le JavaScript. Tous les sites qui génèrent leur contenu côté client, plateformes SPA, applications React ou Vue.js, pages à pagination infinie, se retrouvent donc hors de portée sans couche supplémentaire comme Selenium ou Playwright.
- Pas de rendu JavaScript : les sites dynamiques nécessitent Selenium ou Playwright en complément, ce qui alourdit la stack et multiplie les points de défaillance.
- Anti-scraping entièrement manuel : rotation de proxies, variation des user-agents, gestion des cookies et des délais : tout repose sur le développeur.
- Fragilité face aux changements HTML : un redesign du site cible peut casser le scraper du jour au lendemain, sans alerte.
- Courbe d’apprentissage réelle : maîtrise de Python, lecture du DOM, sélecteurs CSS et XPath : l’investissement initial est significatif pour un profil non technique.
Pour aller plus loin sur le sujet des outils de scraping Python, l’article Les 3 meilleures façons d’extraire les données d’un site web détaille plusieurs approches complémentaires.
Qu’est-ce qu’Octoparse ?
Octoparse est un outil de web scraping no-code (sans programmation) qui permet d’extraire des données depuis n’importe quel site web via une interface visuelle par pointer-cliquer. Il n’est pas nécessaire d’écrire du code : on configure le scraper dans une interface graphique, on définit les champs à collecter, et on exporte directement en Excel, CSV, JSON ou vers une base de données.
Contrairement à BeautifulSoup, Octoparse intègre nativement un moteur de rendu JavaScript, une gestion des proxies rotatifs, et un service cloud pour automatiser et planifier les extractions. La mise en place d’un premier scraper prend généralement moins de cinq minutes.
Ce que fait Octoparse que BeautifulSoup ne peut pas faire seul
- Rendu JavaScript natif : scraping des sites dynamiques, SPA, React et chargement infini, sans configuration supplémentaire.
- Proxy rotatif intégré : contournement automatique des mesures anti-scraping sans intervention manuelle.
- Cloud scheduling : lancement automatique de scrapes à intervalles réguliers, disponible depuis le service cloud.
- Export direct : Excel, CSV, JSON, Google Sheets ou base de données, sans écrire de code de post-traitement.
- Templates prêts à l’emploi : des centaines de modèles préconfigurés pour les sites les plus courants.
Si vous voulez tester par vous-même, un compte Octoparse gratuit suffit pour configurer et lancer votre premier scrape en quelques minutes.
Octoparse convient particulièrement aux profils non techniques et aux équipes qui privilégient la rapidité d’exécution sur la flexibilité du code. Pour les développeurs qui ont besoin d’un contrôle précis sur chaque requête HTTP ou d’une intégration dans un pipeline Python existant, BeautifulSoup reste le choix le plus adapté.

Convertir automatiquement les pages web en fichiers Excel, CSV, Google Sheets ou base de données.
Configurer l’extraction sans écrire une seule ligne de code, grâce à la détection automatique des champs.
Lancer un premier scrape en quelques minutes avec les modèles préconfigurés pour les sites courants.
Limiter les blocages grâce à la rotation automatique de proxies IP et à une gestion intelligente des requêtes.
Planifier des extractions récurrentes via le service cloud, sans serveur à maintenir.
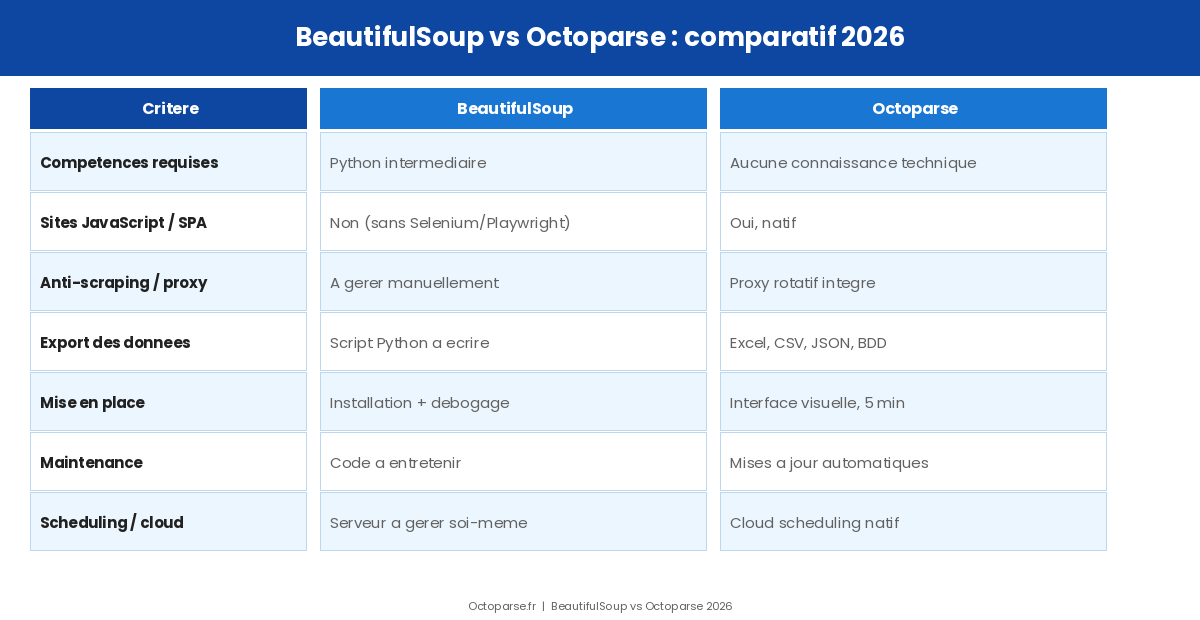
BeautifulSoup vs Octoparse : comparatif détaillé
Voici un tableau comparatif sur les critères qui différencient les deux outils dans la pratique.
| Critère | BeautifulSoup | Octoparse |
| Compétences requises | Python intermédiaire | Aucune compétence technique |
| Sites JavaScript / SPA | Non (sans Selenium) | Oui, natif |
| Anti-scraping / proxy | À gérer manuellement | Proxy rotatif intégré |
| Export des données | Script Python à écrire | Excel, CSV, JSON, BDD |
| Mise en place initiale | Installation + débogage | Interface visuelle, 5 minutes |
| Maintenance du code | Code à entretenir | Mises à jour automatiques |
| Scheduling / cloud | Serveur à gérer soi-même | Cloud scheduling natif |
| Tarif | Gratuit (open source) | Freemium + plans payants |
| Communauté / support | Communauté open source (Stack Overflow, GitHub) | Documentation FR, support e-mail, aide en ligne |
Facilité de prise en main
BeautifulSoup nécessite de connaître Python, de comprendre la structure HTML d’une page, et de savoir utiliser les outils de développement d’un navigateur pour identifier les sélecteurs CSS ou XPath. Pour un profil non technique, la courbe d’apprentissage est significative.
Octoparse fonctionne par pointer-cliquer : on ouvre l’URL dans l’interface, on clique sur les éléments à extraire, et on configure les champs visuellement. Un premier scraper fonctionnel peut être prêt en moins de dix minutes, sans aucune connaissance en programmation.
Gestion des sites dynamiques (JavaScript)
C’est le point où BeautifulSoup montre ses limites les plus concrètes en production. La bibliothèque parse uniquement le HTML renvoyé par le serveur. Pour les sites modernes qui génèrent leur contenu côté client, Airbnb, LinkedIn, certaines pages Amazon, les applications React ou Vue.js, BeautifulSoup reçoit une page quasiment vide, sans les données attendues.
La solution classique consiste à coupler BeautifulSoup avec Selenium ou Playwright, qui pilotent un vrai navigateur Chromium ou Firefox. Cela fonctionne, mais le coût est réel : temps de démarrage plus long, consommation mémoire accrue, gestion du cycle de vie du navigateur, et complexité de maintenance qui augmente à chaque mise à jour du site cible.
Octoparse intègre nativement un moteur de rendu complet. Les sites dynamiques sont traités de la même façon que les sites statiques, sans configuration supplémentaire.
Anti-scraping et gestion des blocages
Avec BeautifulSoup, la gestion anti-scraping est entièrement manuelle : rotation de proxies, variation des user-agents, gestion des cookies de session, délais aléatoires entre les requêtes, traitement des codes HTTP 429. Des outils complémentaires existent dans l’écosystème Python, mais chaque ajout dans la stack augmente la surface de maintenance.
Octoparse intègre un système de proxy rotatif et gère automatiquement les contre-mesures anti-scraping les plus courantes. Pour les cas les plus exigeants, l’article Comment contourner les CAPTCHA lors du web scraping détaille les stratégies disponibles.
Volume et mise à l’échelle
BeautifulSoup est adapté aux extractions ponctuelles ou aux petits volumes. Pour du scraping à grande échelle, il faut s’appuyer sur Scrapy (framework de crawling Python) ou construire une architecture de scraping distribuée, ce qui nécessite une expertise backend significative.
Octoparse propose un service cloud qui permet de lancer des scrapes planifiés, de paralléliser les extractions, et de gérer de grands volumes sans infrastructure à gérer. L’article Maîtriser le crawling de liste avec Octoparse explique comment configurer des extractions multi-URLs en quelques étapes.
Quel outil choisir selon votre profil ?
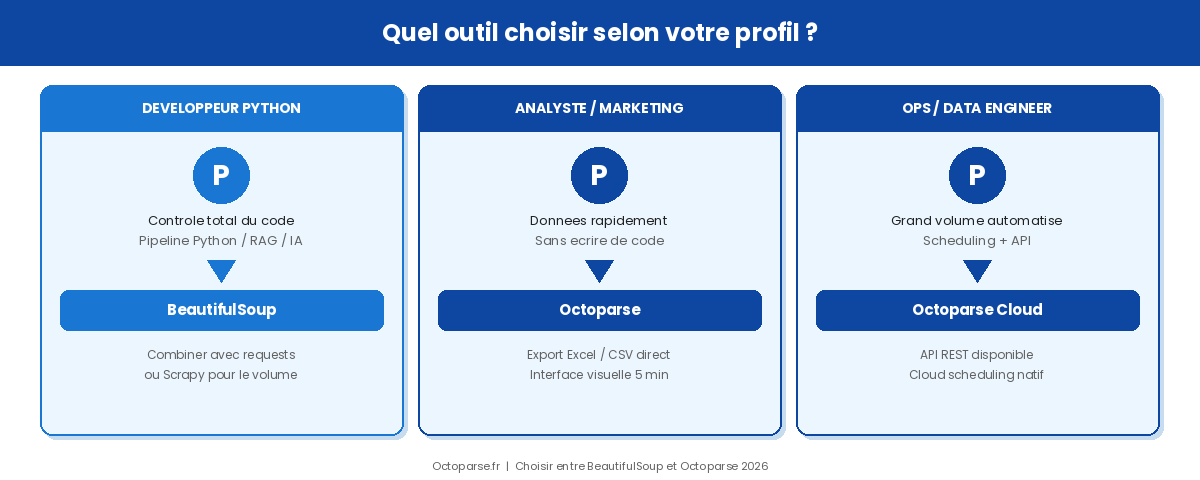
Profil développeur Python
Si vous maîtrisez Python et avez besoin d’un outil s’intégrant dans un pipeline existant, alimentation d’une base vectorielle, pré-traitement pour un LLM, crawling dans un workflow Scrapy, BeautifulSoup reste un choix solide. La bibliothèque est légère, bien documentée, et s’insère directement dans l’écosystème Python sans dépendance supplémentaire.
Pour les développeurs qui travaillent sur des projets d’automatisation web avancés, l’article Navigateur Headless : guide complet pour le scraping web explique comment combiner BeautifulSoup avec Playwright pour gérer les sites dynamiques.
Profil analyste / marketing / ops
Si l’objectif est d’extraire des données pour alimenter un tableau de bord, suivre des prix, constituer une liste de prospects ou enrichir une base CRM, sans écrire ni maintenir du code, Octoparse est le choix le plus direct. La configuration se fait visuellement, l’export est immédiat, et les extractions peuvent être planifiées sans infrastructure à gérer.
Pour la génération de leads B2B, les articles Automatiser sa prospection B2B avec Google Maps et Comment extraire des leads B2B avec Octoparse illustrent des workflows concrets.
Profil data engineer / automatisation
Pour les projets qui nécessitent des volumes importants, des extractions régulières et une intégration dans des outils d’analyse, Octoparse propose une API qui permet de déclencher des scrapes, de récupérer les données et de les intégrer dans n’importe quel pipeline de données.
BeautifulSoup vs Scrapy, Selenium, Playwright : quelle différence ?
Un point fréquent de confusion : BeautifulSoup n’est pas un framework de scraping complet. C’est un parser HTML. Pour du scraping à grande échelle en Python, BeautifulSoup est généralement utilisé conjointement avec d’autres bibliothèques.
BeautifulSoup vs Scrapy
Scrapy est un framework de crawling Python complet : gestion de la file de requêtes, middleware, pipeline de traitement des items, gestion des erreurs, stockage. BeautifulSoup est souvent utilisé à l’intérieur de Scrapy pour le parsing des réponses HTML.
Le choix entre les deux dépend de l’échelle : pour un scraping ponctuel sur quelques pages, BeautifulSoup + requests suffit. Pour crawler des milliers de pages en parallèle avec une logique de suivi de liens, Scrapy est plus adapté.
| BeautifulSoup | Scrapy | |
| Type | Parser HTML | Framework de crawling complet |
| Usage typique | Extraction sur quelques pages | Crawling à grande échelle |
| Courbe d’apprentissage | Moyenne | Élevée |
| Gestion des erreurs | Manuelle | Intégrée (middleware) |
| Utilisation combinée | Souvent utilisé dans Scrapy | Peut appeler BeautifulSoup |
BeautifulSoup vs Selenium / Playwright
Selenium et Playwright pilotent un vrai navigateur et chargent le JavaScript. Ils sont complémentaires de BeautifulSoup pour les sites dynamiques, mais significativement plus lents et plus lourds à déployer. Playwright est généralement préféré à Selenium pour les nouveaux projets grâce à son API moderne et ses performances.
Pour les profils non techniques, Octoparse offre une alternative no-code qui gère l’ensemble de ces scénarios sans nécessiter de choisir ni de combiner des bibliothèques.
Cas d’usage : quand utiliser BeautifulSoup, quand utiliser Octoparse ?
Cas d’usage adaptés à BeautifulSoup
- Extraction de données depuis des sites HTML statiques dans un pipeline Python existant.
- Parsing de fichiers HTML téléchargés localement.
- Alimentation de pipelines RAG ou d’agents IA qui consomment du texte brut.
- Projets de recherche académique ou prototypage rapide en Python.
Cas d’usage adaptés à Octoparse
- Surveillance et comparaison de prix sur les marketplaces françaises :
- https://www.octoparse.fr/template/amazon-product-scraper-by-keywords
- Constitution de fichiers de prospection depuis Google Maps, PagesJaunes ou LinkedIn, sans export manuel.
- Veille concurrentielle et collecte d’avis clients à grande échelle.
- Scraping de sites JavaScript dynamiques sans développement supplémentaire.
- Extractions planifiées et automatisées sans serveur à gérer.
Les modèles Octoparse couvrent les principaux cas d’usage sans configuration : scraping de réseaux sociaux (Social Media Finder), extraction d’e-mails (Email Scrapers), ou encore scraping Amazon (Amazon Scraper).
BeautifulSoup, Octoparse et le RGPD : ce qu’il faut savoir
Quelle que soit la technologie utilisée, BeautifulSoup, Octoparse ou tout autre outil de scraping, la responsabilité du respect du cadre juridique incombe entièrement à l’utilisateur.
En France, le cadre applicable est celui du RGPD et des recommandations de la CNIL. Scraper des données personnelles identifiables (noms, e-mails, numéros de téléphone) sans base légale valide constitue une violation potentielle, indépendamment de l’outil employé. L’article Prospection commerciale et RGPD : peut-on scraper PagesJaunes légalement ? détaille le cadre juridique applicable en France.
Points d’attention pratiques : respectez les directives robots.txt, évitez la collecte de données personnelles sans base légale, et vérifiez les conditions d’utilisation du site cible avant de lancer un scrape.
FAQ
- Le web scraping avec BeautifulSoup est-il légal en France ?
L’outil en lui-même n’est pas illégal. C’est l’usage qui détermine la légalité. En France, le cadre applicable est celui du RGPD pour les données personnelles, et des conditions générales d’utilisation du site scrapé. Collecter des données publiques non personnelles (prix, descriptions produits, informations d’entreprises) est généralement admis, sous réserve de respecter le fichier robots.txt et de ne pas surcharger les serveurs. Pour les données personnelles, une base légale est obligatoire. La section RGPD de cet article détaille les points à vérifier avant de lancer un scrape en France.
- BeautifulSoup est-il encore pertinent en 2026 ?
Oui. Pour le parsing HTML statique dans un contexte Python, BeautifulSoup reste une bibliothèque solide et très utilisée. Sa pertinence diminue pour les sites dynamiques et pour les utilisateurs non techniques, mais elle reste une référence dans l’écosystème Python scraping.
- Peut-on utiliser BeautifulSoup avec des sites dynamiques ?
Pas directement. BeautifulSoup parse uniquement le HTML renvoyé par le serveur. Pour les sites qui génèrent leur contenu en JavaScript, il faut coupler BeautifulSoup avec Selenium ou Playwright, qui pilotent un vrai navigateur et chargent le JavaScript avant de passer le HTML à BeautifulSoup.
- BeautifulSoup ou Scrapy : quelle différence ?
BeautifulSoup est un parser HTML ; Scrapy est un framework de crawling complet. Les deux sont souvent utilisés ensemble : Scrapy gère la navigation entre les pages et la gestion des requêtes, BeautifulSoup parse le contenu HTML de chaque page.
- Octoparse remplace-t-il vraiment BeautifulSoup ?
Pour un développeur Python qui travaille sur des pipelines en code, non. Pour un profil non technique qui a besoin d’extraire des données rapidement sans programmer, oui. Les deux outils répondent à des besoins différents et ne s’adressent pas au même public.
- Comment installer BeautifulSoup ?
BeautifulSoup s’installe en une ligne via pip :
pip install beautifulsoup4
Pour de meilleures performances, installez également le parser lxml, plus rapide que le parser natif Python :
pip install lxml
L’import dans un script se fait avec :
from bs4 import BeautifulSoup
En cas de problème dans un environnement virtuel, utilisez python -m pip install beautifulsoup4 pour vous assurer d’installer dans le bon interpréteur.
- Octoparse est-il gratuit ?
Octoparse propose une version gratuite avec accès aux fonctionnalités de base. Les fonctionnalités avancées (cloud scheduling, proxies rotatifs, API) sont disponibles dans les plans payants. Le détail des offres est disponible sur la page tarifaire.
- Quels sites peut-on scraper avec Octoparse ?
Octoparse fonctionne sur la quasi-totalité des sites web, y compris les sites dynamiques et les plateformes protégées. Des modèles préconfigurés sont disponibles pour les sites les plus courants : Google Maps, TikTok, Twitter/X, et bien d’autres sur Modèles d’Octoparse.
En résumé
BeautifulSoup et Octoparse ne s’adressent pas au même public, et c’est précisément ce qui rend la comparaison utile. BeautifulSoup est l’outil des développeurs Python qui veulent un contrôle total sur leur pipeline, au prix d’une stack à construire et à maintenir. Octoparse répond à un besoin différent : extraire des données rapidement, sans code, avec une gestion automatique des contraintes techniques.
Le bon choix dépend moins de la performance brute de l’outil que de votre situation réelle : si vous codez en Python et que le scraper s’insère dans un projet plus large, BeautifulSoup est pertinent. Si vous avez besoin de données sans consacrer de temps à l’infrastructure, Octoparse est plus efficace.
Pour tester sans engagement, l’essai gratuit Octoparse donne accès à l’ensemble des fonctionnalités de base, sans carte bancaire.



