Depuis son lancement en 2024, Crawl4AI est devenu l’un des projets GitHub les plus étoilés dans l’univers du web scraping : plus de 61 000 étoiles sur GitHub en moins de deux ans, ce qui en fait l’un des projets de web scraping les plus suivis du moment.
Mais si vous n’êtes pas développeur, ou si vous avez simplement besoin de récupérer des données structurées depuis un site web sans écrire une ligne de code, Crawl4AI n’est probablement pas l’outil qu’il vous faut. Cet article fait le point : ce que Crawl4AI fait vraiment, ses limites concrètes, et quelle alternative choisir selon votre profil en 2026.
Qu’est-ce que Crawl4AI ?
Crawl4AI est une bibliothèque Python open source conçue pour extraire du contenu web et le convertir en Markdown structuré, optimisé pour être consommé par des modèles de langage (LLM). Le projet est né en 2023 d’une frustration simple : les outils de crawling existants imposaient soit une API propriétaire, soit un abonnement payant, soit les deux.
Son créateur a publié le code sur GitHub sous licence Apache 2.0. Le projet est passé viral et a atteint la première place des tendances GitHub en 2024.
À la différence d’un scraper classique comme Octoparse ou ParseHub, Crawl4AI ne produit pas de tableau de données. Il transforme une page web en texte propre au format Markdown, pensé pour être injecté dans un LLM, un système RAG ou un agent autonome. Ce n’est pas un extracteur de données au sens commercial du terme : c’est un convertisseur web → texte pour l’IA.
Comment fonctionne Crawl4AI ?
Crawl4AI s’appuie sur Playwright pour piloter un navigateur headless (Chromium), ce qui lui permet de traiter les sites à contenu JavaScript dynamique. Une fois la page chargée, il applique des filtres de contenu dont un algorithme BM25, pour ne conserver que les sections pertinentes par rapport à une requête donnée.
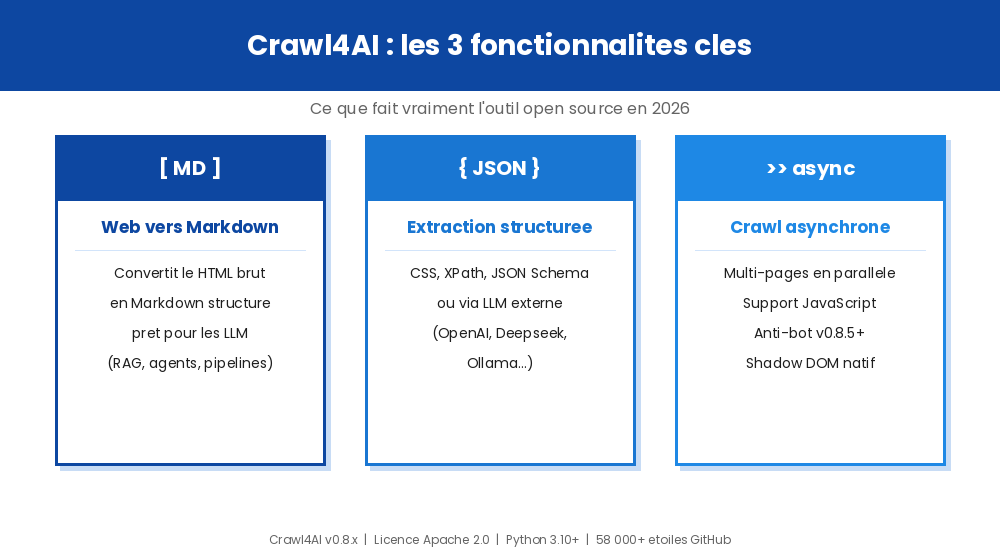
Les trois fonctionnalités centrales :
Génération de Markdown propre
La sortie principale de Crawl4AI est un Markdown structuré avec citations et références. Le filtre BM25 permet de ne garder que les passages pertinents pour un traitement LLM ultérieur.
Extraction structurée
Au-delà du Markdown, l’outil supporte l’extraction JSON via des sélecteurs CSS, XPath ou un schéma défini par l’utilisateur. Pour les cas complexes, il est possible de connecter un LLM externe (OpenAI, Deepseek, Ollama) pour piloter l’extraction.
Crawl asynchrone et multi-pages
Crawl4AI utilise la programmation asynchrone Python (asyncio) pour traiter plusieurs pages en parallèle. Depuis la version 0.8.5, il intègre une détection anti-bot à trois niveaux avec escalade automatique de proxy.
Comment installer Crawl4AI ?
Crawl4AI nécessite Python 3.10 ou supérieur. L’installation se fait en trois étapes depuis un terminal :
Étape 1 : installer la bibliothèque
pip install crawl4ai
Étape 2 : initialiser les dépendances (Playwright, Chromium)
crawl4ai-setup
Étape 3 : vérifier que tout fonctionne
crawl4ai-doctor
La commande crawl4ai-setup télécharge automatiquement le binaire Chromium et configure les dépendances système nécessaires à Playwright. Sur certains systèmes Linux allégés (VPS sans bibliothèques graphiques), cette étape peut nécessiter une installation manuelle complémentaire.
Exemple de crawl minimal :
Ce script charge la page en mode headless, en extrait le contenu et retourne les 300 premiers caractères en Markdown. C’est le niveau d’entrée. Pour aller plus loin, extraction JSON, crawl multi-pages, connexion à un LLM, il faut maîtriser les concepts asynchrones Python et consulter la documentation de l’API.
C’est précisément là que beaucoup d’utilisateurs non-techniques bloquent. Un responsable marketing d’une PME e-commerce qui veut surveiller les prix de ses concurrents n’a pas vocation à déboguer des scripts asyncio ou à configurer un environnement Playwright. Le projet reste fondamentalement un outil de développeur.
Les limites de Crawl4AI pour les profils non-techniques
Crawl4AI est un outil de grande qualité dans son domaine. Ses limites ne sont pas des défauts ; elles reflètent simplement les choix de conception du projet, orienté développeurs Python.
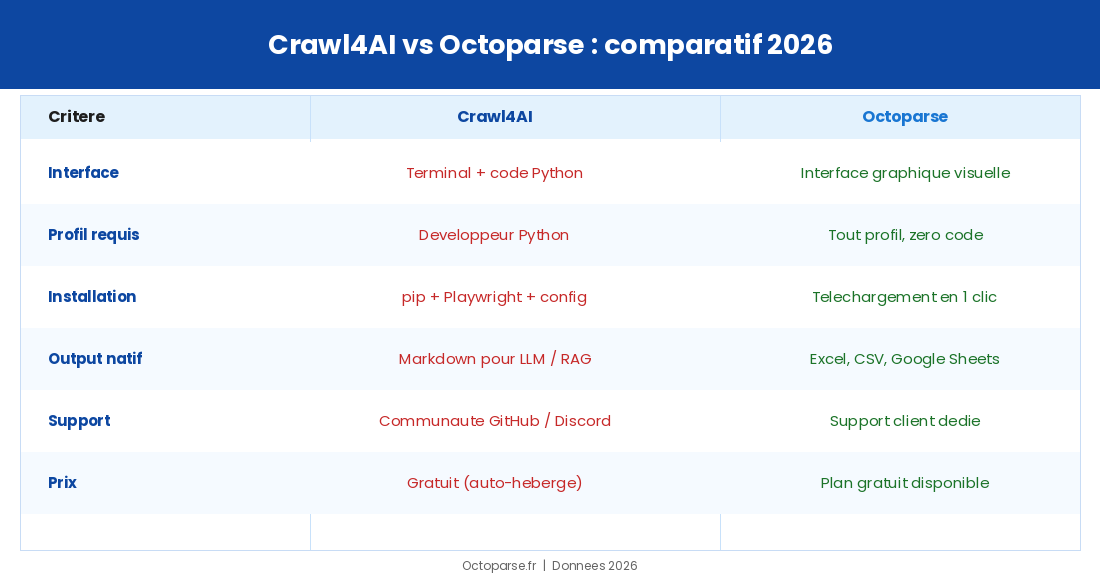
Aucune interface graphique
Tout passe par le terminal et des scripts Python. Il n’existe pas de mode point-and-click pour sélectionner des éléments sur une page.
Courbe d’apprentissage réelle
Maîtriser la programmation asynchrone, configurer BrowserConfig et CrawlerRunConfig, gérer les erreurs de Playwright : cela représente plusieurs jours de travail pour quelqu’un qui n’a pas d’expérience Python.
Maintenance à votre charge
Crawl4AI est maintenu par une communauté GitHub active, mais il n’existe pas de support client dédié. En cas de blocage, vous posez une question sur Discord ou ouvrez une issue.
Mises à jour de sécurité critiques à suivre
La version 0.8.6 a corrigé une faille de sécurité liée à la chaîne d’approvisionnement PyPI. Si vous utilisez Crawl4AI en production, vous devez surveiller activement les releases et appliquer les mises à jour rapidement. Ce type de vigilance est chronophage sans équipe technique dédiée.
Output orienté LLM, pas tableur
Si votre objectif est d’exporter des données dans Excel, Google Sheets ou un CRM, Crawl4AI n’est pas taillé pour ça. Sa sortie native est du Markdown, pas un CSV structuré.
Hébergement à prévoir
L’outil est gratuit mais vous devez gérer l’infrastructure vous-même : serveur, Docker, mémoire RAM, mises à jour. Sur un VPS entrée de gamme (2 vCPU / 4 Go RAM), le coût mensuel tourne autour de 15 à 20 €.
Crawl4AI vs Firecrawl : quelle différence ?
La confusion entre Crawl4AI et Firecrawl est fréquente car les deux outils ciblent les flux IA. Voici les différences essentielles :
Crawl4AI est une bibliothèque Python locale, entièrement open source. Vous l’installez sur votre machine ou votre serveur, vous écrivez du code Python, vous gérez l’infrastructure. Pas d’abonnement, pas de limite de pages, mais tout repose sur vous.
Firecrawl propose principalement une API cloud managée : vous envoyez une URL, vous recevez du Markdown ou du JSON. Dans sa version cloud, aucune installation n’est nécessaire et la maintenance est gérée par l’éditeur.En contrepartie, c’est un service payant : les plans démarrent à 16 $/mois pour 3 000 pages.
Pour les équipes qui veulent intégrer du contenu web dans un pipeline LLM et qui préfèrent une API simple sans infrastructure à gérer, Firecrawl est plus accessible. Pour les développeurs qui veulent un contrôle total, une licence open source et aucun coût par requête, Crawl4AI est le choix naturel.
Si vous travaillez dans les ventes, le marketing ou l’e-commerce et que vous avez besoin d’extraire des données structurées, prix, contacts, annonces : aucun des deux n’est vraiment adapté.
Un comparatif détaillé est disponible dans l’article Firecrawl : avis complet et meilleures alternatives.
Crawl4AI et MCP : ce que ça change pour les équipes IA
Depuis l’émergence du protocole MCP (Model Context Protocol) en 2025, plusieurs projets ont développé des serveurs MCP pour Crawl4AI, permettant à des agents IA comme Claude ou Cursor d’appeler Crawl4AI directement depuis une session de travail.
En pratique, cela signifie qu’un agent IA peut crawler une URL, récupérer le contenu en Markdown et l’utiliser dans une tâche, sans qu’un développeur ait à écrire de code intermédiaire. Un exemple typique : un agent Claude connecté à un serveur MCP Crawl4AI peut, sur simple instruction en langage naturel, extraire le contenu d’une page de documentation et l’intégrer dans une réponse contextualisée. C’est une évolution réelle pour les équipes qui construisent des workflows IA avancés.
Cela dit, la configuration d’un serveur MCP Crawl4AI reste une opération technique (Python ≥ 3.11, configuration JSON, variables d’environnement). Ce n’est pas une solution plug-and-play pour des équipes sans compétences techniques.
Pour les équipes qui veulent connecter leurs extractions de données à des agents IA sans gérer d’infrastructure, Octoparse propose une intégration MCP directement opérationnelle, sans installation de bibliothèque.
Quelle alternative à Crawl4AI si vous n’êtes pas développeur ?
Si votre objectif est de récupérer des données depuis un site web : prix, contacts, annonces immobilières, résultats de recherche, sans écrire de code Python ni gérer un serveur, il existe des outils construits précisément pour ça.
Octoparse : l’alternative no-code la plus complète
Octoparse est un outil de web scraping avec interface graphique, utilisé par des équipes marketing, commerciales et e-commerce pour extraire des données structurées sans une ligne de code. Là où Crawl4AI demande de configurer un environnement Python, Octoparse propose un éditeur visuel : vous pointez sur les éléments à extraire, vous configurez les règles, vous lancez.
Ce que ça change concrètement :
Avec Crawl4AI, extraire les prix de 200 pages produit sur un site e-commerce français demande d’écrire un script Python, de gérer la pagination, d’éviter les blocages et de transformer la sortie Markdown en CSV exploitable. Avec Octoparse, la même tâche se configure en quelques minutes depuis l’interface, avec un export direct vers Excel ou Google Sheets.

Convertir n’importe quel site web en fichier Excel, CSV, Google Sheets ou base de données structurée.
Détecter et extraire automatiquement les données ciblées, sans écrire une seule ligne de code.
Scraper les sites les plus populaires en quelques clics grâce aux modèles prêts à l’emploi.
Contourner les blocages IP grâce aux proxies rotatifs intégrés et à l’API avancée.
Programmer et automatiser vos extractions dans le cloud, sans laisser votre ordinateur allumé.
Un guide complet pour débutants est disponible pour prendre en main l’outil en moins d’une heure.
Octoparse propose un plan gratuit à vie (10 tâches, jusqu’à 50 000 lignes exportées par mois), sans carte bancaire requise. Les plans payants démarrent à 69 $/mois (facturés annuellement). Si vous avez passé plus d’une heure à déboguer un script Python pour extraire des données qui auraient dû prendre dix minutes, c’est le bon moment de changer d’approche : lancez un essai gratuit et voyez la différence par vous-même.
Quel outil choisir selon votre profil ?
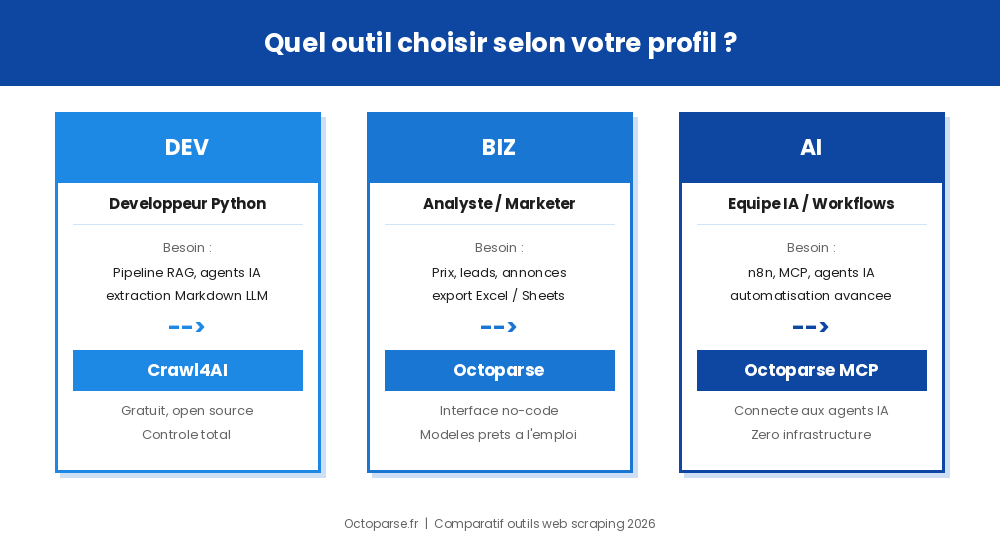
Crawl4AI pour les développeurs Python : pipelines RAG et agents IA
Crawl4AI est fait pour vous. Gratuit, open source, très flexible, avec une communauté active et des mises à jour régulières. La version 0.8.x apporte la détection anti-bot automatique et le support MCP. La documentation officielle couvre l’ensemble des fonctionnalités en anglais.
Alternative no-code à Crawl4AI pour les équipes marketing et e-commerce
Si votre journée ne tourne pas autour de Python, Crawl4AI va vous ralentir, pas vous aider. Le terminal, les scripts asyncio, la gestion des erreurs Playwright : ce sont des obstacles réels pour quelqu’un dont le métier est le marketing, la vente ou la gestion d’un catalogue e-commerce. Octoparse, avec son interface visuelle et ses modèles prêts à l’emploi, vous permettra d’extraire des données en quelques clics. Pour les besoins de génération de leads, les modèles de recherche d’emails et d’extraction depuis les réseaux sociaux sont disponibles directement.
Crawl4AI MCP et Octoparse MCP : pour les équipes IA et workflows automatisés
Les deux outils sont complémentaires. Crawl4AI pour les pipelines RAG en Python ; Octoparse MCP pour connecter vos extractions à des agents IA sans infrastructure à gérer.
Cas d’usage concrets : ce qu’on peut faire avec Crawl4AI (et ce qui reste compliqué)
Ce que Crawl4AI gère bien :
Alimenter une base de connaissances RAG à partir de sites de documentation publics. Construire un agent de veille qui crawle quotidiennement des sources d’information et en extrait les passages pertinents pour un LLM. Automatiser l’extraction de contenu depuis des sites JavaScript-heavy dans un pipeline de fine-tuning.
Ce qui devient vite compliqué sans expérience Python :
Extraire des données paginées depuis un site de e-commerce (il faut gérer la navigation entre pages dans le code). Surveiller les prix de concurrents sur plusieurs dizaines de sites (il faut orchestrer les jobs, gérer les erreurs, relancer les crawls échoués). Exporter vers un Google Sheet ou un CRM (Crawl4AI ne propose pas d’intégration native avec ces outils).
Exemple concret en contexte français : une équipe commerciale d’une PME qui veut constituer un fichier de prospects depuis PagesJaunes n’a pas besoin d’un pipeline RAG. Elle a besoin de noms, d’adresses et de numéros de téléphone exportés dans un Google Sheet. Crawl4AI n’est pas conçu pour ça. Un modèle Octoparse dédié à PagesJaunes fait le travail en quelques clics, sans une ligne de code.
Pour ce dernier type de besoin, données structurées, export vers tableur ou CRM, suivi de prix, Octoparse propose des modèles directement opérationnels, sans configuration technique :
Extrait titres, prix, notes et vendeurs depuis Amazon en quelques clics, avec export direct vers Excel ou CSV :
https://www.octoparse.fr/template/amazon-product-scraper-by-keywords
Récupère la structure HTML brute d’une page pour les équipes qui ont besoin du contenu source sans passer par Python :
https://www.octoparse.fr/template/html-scraper
Pour en savoir plus sur les méthodes d’extraction de données web, cet article sur les 3 meilleures façons d’extraire les données d’un site web couvre les approches disponibles selon le profil technique.
Crawl4AI et le RGPD : ce que vous devez savoir
Crawl4AI est un outil de crawling, pas un service managé. La responsabilité du respect des règles juridiques repose entièrement sur l’utilisateur.
En France, le cadre applicable est celui du RGPD (Règlement Général sur la Protection des Données) et des lignes directrices publiées par la CNIL. Scraper des données personnelles (noms, adresses email, numéros de téléphone identifiables) depuis des sites français sans base légale constitue une violation potentielle du RGPD, quelle que soit la technologie utilisée.
Les points d’attention pratiques :
Fichier robots.txt
Crawl4AI respecte par défaut les directives robots.txt. Il est possible de désactiver cette vérification dans la configuration, mais le faire sur des sites qui l’interdisent explicitement expose à des risques juridiques.
Données personnelles
Si votre crawl collecte des données identifiables (contacts B2B, emails, profils), vous devez disposer d’une base légale valide (intérêt légitime, consentement, etc.) et pouvoir documenter votre démarche en cas de contrôle CNIL.
Conditions d’utilisation des sites
Certains sites interdisent explicitement le scraping dans leurs CGU. Cette interdiction n’a pas la même portée juridique que le RGPD, mais elle peut fonder une action en responsabilité contractuelle ou en concurrence déloyale.
Pour approfondir ce point dans le contexte de la prospection commerciale, l’article Prospection commerciale et RGPD : peut-on scraper PagesJaunes légalement en France ? détaille les conditions d’une collecte conforme au droit français.
Ressources et liens utiles
Pour aller plus loin, la documentation officielle de Crawl4AI couvre l’ensemble des fonctionnalités en anglais. Le dépôt GitHub (Apache 2.0) permet de suivre les releases et de signaler des bugs. Pour Octoparse, le centre d’aide et la page tarifs sont les points d’entrée habituels.
FAQ
- Crawl4AI est-il gratuit ?
Oui, Crawl4AI est entièrement gratuit et distribué sous licence Apache 2.0. Il n’existe pas d’abonnement, pas de crédits à acheter, pas de limite de pages imposée par l’éditeur. En revanche, vous devez gérer vous-même l’infrastructure (serveur, mémoire, mises à jour). Si vous utilisez un LLM externe pour l’extraction (OpenAI, Deepseek), des coûts d’API s’appliquent selon votre usage.
- Faut-il savoir coder pour utiliser Crawl4AI ?
Oui. Crawl4AI est une bibliothèque Python qui s’utilise depuis le terminal. Il n’existe pas d’interface graphique. Vous devez être à l’aise avec Python (idéalement avec la programmation asynchrone), savoir installer des dépendances et déboguer des scripts. Si vous cherchez un outil sans code, des alternatives comme Octoparse ou les extensions de scraping pour Chrome sont plus adaptées.
- Quelle est la différence entre Crawl4AI et un web scraper classique ?
Un web scraper classique (Octoparse, ParseHub, WebScraper.io) extrait des données structurées (prix, noms, adresses) et les exporte dans un tableur ou un CRM. Crawl4AI a une finalité différente : il convertit le contenu d’une page web en Markdown propre pour l’alimenter dans un LLM ou un pipeline RAG. Ce n’est pas un extracteur de données tabulaires. Si vous avez besoin de données organisées dans Excel ou Google Sheets, un scraper classique sera plus adapté. Pour un tour d’horizon des options disponibles, l’article sur les 9 web scrapers gratuits à ne pas manquer couvre les principaux outils selon les profils.
- Crawl4AI fonctionne-t-il avec les sites protégés par anti-bot ?
Depuis la version 0.8.5, Crawl4AI intègre une détection anti-bot automatique à trois niveaux avec escalade de proxy. Cela améliore significativement les taux de succès sur les sites qui utilisent des protections Cloudflare ou des CAPTCHA simples. Pour les sites avec des protections plus avancées, la configuration manuelle reste nécessaire. Un aperçu des techniques de contournement est disponible dans l’article sur les 10 solveurs indispensables pour contourner les captchas.
- Peut-on utiliser Crawl4AI avec n8n ou des outils d’automatisation ?
Oui. Il existe des intégrations Crawl4AI pour n8n qui permettent de déclencher un crawl depuis un workflow sans écrire de code Python. Des serveurs MCP Crawl4AI sont également disponibles pour intégrer le crawl dans des agents IA (Claude, Cursor). Ces configurations restent techniques et demandent une mise en place initiale. Pour une alternative directement intégrée aux workflows IA, l’intégration MCP d’Octoparse est opérationnelle sans configuration supplémentaire.
- Crawl4AI est-il compatible avec les sites en JavaScript ?
Oui. Crawl4AI utilise Playwright en arrière-plan, ce qui lui permet de piloter un navigateur Chromium headless et donc de traiter les sites dont le contenu est rendu côté client (React, Vue, Angular). Pour en savoir plus sur le fonctionnement des navigateurs headless dans le contexte du scraping, l’article sur le navigateur headless couvre les bases.
- Quelle est la meilleure alternative no-code à Crawl4AI en France ?
Pour les profils non-techniques en France, Octoparse est l’alternative la plus complète : interface graphique en français, export direct vers Excel / Google Sheets / CSV, modèles prêts à l’emploi pour les sites français (PagesJaunes, Vinted, Leboncoin, SeLoger) et support client dédié. Pour aller plus loin sur les critères de choix, l’article sur les web scrapers pour Chrome couvre également les options légères pour les profils non-techniques.
- Le web scraping avec Crawl4AI est-il légal en France ?
Crawl4AI en lui-même est un outil neutre. La légalité dépend de ce que vous faites avec : les données que vous collectez, leur nature (personnelles ou non), l’usage que vous en faites et les conditions d’utilisation du site ciblé. En France, le RGPD s’applique dès lors que vous collectez des données identifiables. La CNIL dispose d’un pouvoir de contrôle et de sanction. La règle de base : scraper des données publiques non personnelles dans un cadre professionnel légitime est généralement toléré ; scraper des données personnelles sans base légale valide ne l’est pas. En cas de doute sur un projet spécifique, le site de la CNIL publie des lignes directrices accessibles sur la collecte de données en ligne. Pour les cas complexes, un juriste spécialisé en droit du numérique reste la référence.